In today’s connected world, almost every organization depends on a stable and continuous network connection. Whether it is a small office sharing files or a large enterprise running critical applications across multiple sites, network availability has become a foundation of daily operations. Even a brief interruption in connectivity can cause delays, data loss, or service downtime that affects productivity and user experience.
To prevent such disruptions, network engineers rely on different protocols that enhance stability, routing intelligence, and fault tolerance. Among these, Virtual Router Redundancy Protocol (VRRP) plays a crucial role in ensuring that network traffic continues flowing even when a router fails unexpectedly. Although it often receives less attention compared to routing protocols like OSPF or EIGRP, VRRP is a key mechanism that strengthens network reliability at the gateway level.
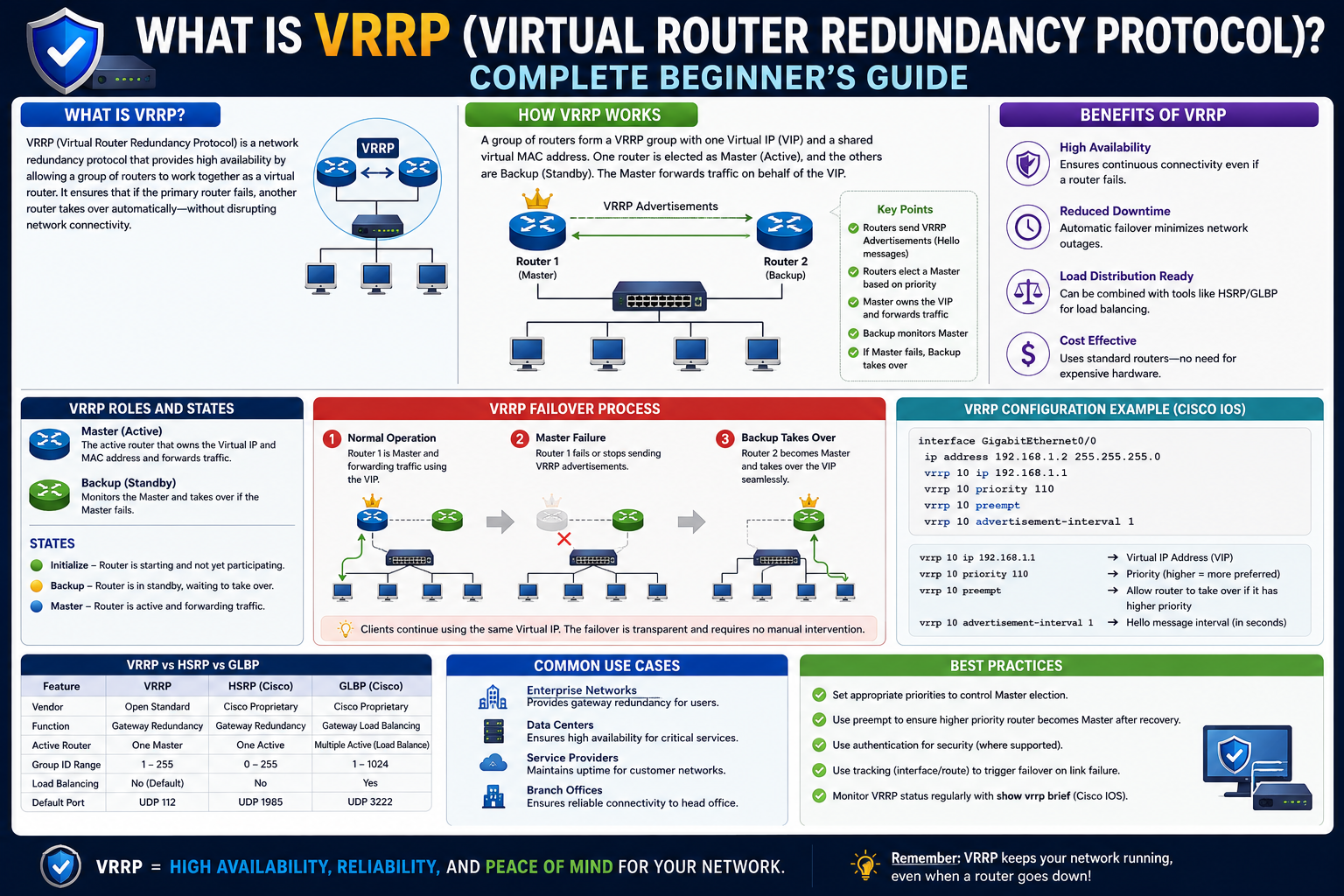
VRRP is designed specifically to solve a very practical problem: what happens when the device responsible for connecting a local network to other networks suddenly stops working? Instead of relying on a single router, VRRP allows multiple routers to work together in a coordinated group. This group behaves like a single logical router, ensuring uninterrupted access to external networks such as the internet or remote services.
Understanding VRRP is important not only for certification exams or theoretical knowledge but also for real-world troubleshooting. Network administrators often encounter situations where redundancy mechanisms determine whether users experience a smooth transition or a complete outage. VRRP ensures that failover happens almost instantly and transparently, without requiring manual intervention.
The Importance of Network Redundancy in LAN Design
To fully appreciate VRRP, it is important to understand why redundancy matters in local area networks. A LAN typically connects devices such as computers, printers, servers, and switches within a limited geographical area. These devices communicate with each other and often rely on a central router or gateway to reach external networks.
In a simple setup, a single router acts as the default gateway for all devices in the network. This router handles all traffic that needs to leave the local network and reach the internet or another remote system. While this design is straightforward and cost-effective, it also creates a single point of failure.
If that router fails, every device in the LAN loses external connectivity. Internally, devices might still communicate with each other, but anything requiring outside access becomes unavailable. In modern business environments, this type of downtime is unacceptable because many applications depend on constant connectivity.
Redundancy is introduced to eliminate this risk. Instead of relying on one router, multiple routers are configured to share the responsibility of acting as the default gateway. However, simply adding more routers is not enough. Devices in the network must still see a single consistent gateway IP address. Otherwise, configuration becomes complex, and routing becomes inefficient.
This is where VRRP becomes essential. It provides a structured method for multiple routers to work together while presenting a single virtual gateway to all connected devices. This balance between redundancy and simplicity is what makes VRRP a widely used solution in network design.
Core Concept Behind Virtual Router Redundancy Protocol
At its core, VRRP is built around a simple but powerful idea: multiple physical routers can act as one virtual router. This virtual router is what end devices interact with, even though, behind the scenes, several routers are participating in the process.
Each VRRP group consists of multiple routers that are configured to share a virtual IP address. This virtual IP address becomes the default gateway for devices on the LAN. Instead of pointing to a specific physical router, all devices point to this shared virtual address.
Within the VRRP group, one router is selected to actively handle traffic. This router is often referred to as the primary or master router. The remaining routers remain in standby mode, ready to take over if the active router becomes unavailable.
The key advantage of this design is that end devices remain unaware of any changes happening within the router group. From their perspective, the gateway remains the same, even if the physical device behind that gateway changes. This seamless transition is what makes VRRP highly effective for maintaining network uptime.
VRRP also ensures that failover happens automatically. There is no need for manual switching or reconfiguration when a router fails. The backup router detects the failure and immediately takes over the responsibilities of the active router, maintaining continuous service availability.
Understanding the Virtual Router Abstraction
One of the most important ideas in VRRP is abstraction. Instead of exposing multiple physical routers to the network, VRRP hides this complexity behind a single virtual identity.
This abstraction simplifies network design significantly. Without VRRP, each device would need to be configured with multiple potential gateways or rely on manual intervention during failures. With VRRP, all devices simply use one gateway address, regardless of how many routers exist behind it.
This virtual router behaves as if it were a real physical device. It responds to network requests, forwards traffic, and maintains continuity even when the underlying physical hardware changes. The abstraction layer ensures that changes in the router group do not affect connected devices.
From a user perspective, everything remains consistent. Applications continue running, internet access remains available, and network sessions are preserved as much as possible. This consistency is critical in environments where downtime directly impacts business operations.
Active and Backup Router Roles in VRRP
Within a VRRP group, routers are assigned specific roles that determine their behavior. The most important role is the active router, which is responsible for handling all traffic sent to the virtual IP address. This router acts as the primary gateway for the network.
Backup routers remain in a standby state. They continuously monitor the active router and wait for an opportunity to take over if needed. These routers do not actively forward traffic under normal conditions, but they are fully prepared to assume control at any moment.
The presence of backup routers ensures that there is always a fallback option available. If the active router fails due to hardware issues, software crashes, or connectivity loss, one of the backup routers immediately steps in to replace it.
This role separation is dynamic rather than static. Depending on network conditions and configuration settings, different routers may assume the active role over time. This flexibility is what allows VRRP to adapt to changing network environments without requiring manual adjustments.
VRRP Election Process and Router Priority
A key mechanism that determines which router becomes active is the election process. VRRP uses priority values assigned to each router to decide which device should take control of the virtual router role.
Each router in the VRRP group is configured with a priority number. The router with the highest priority becomes the active router. If multiple routers share the same priority value, additional factors such as IP address may be used to break the tie.
This election process happens automatically when the VRRP group is formed or when a change occurs in the network. For example, if the current active router fails, the remaining routers immediately participate in a new election to select a replacement.
The election process is essential for maintaining order within the VRRP group. Without it, routers might conflict over which device should handle traffic, leading to instability or routing issues.
Priority values also allow network administrators to influence failover behavior. By assigning higher priority to more powerful or reliable routers, they can ensure that the most capable device remains active under normal conditions.
Role of Virtual Router Identifier (VRID)
To manage multiple VRRP groups within the same network, each group is assigned a unique identifier known as the Virtual Router Identifier (VRID). This identifier helps distinguish one VRRP group from another.
In large networks, it is common to have multiple VRRP groups operating simultaneously. Each group may serve a different subnet or network segment. The VRID ensures that routers only participate in the correct group and do not interfere with unrelated configurations.
The VRID acts as a label that binds routers together within a specific redundancy group. All routers sharing the same VRID work collectively to maintain a single virtual gateway. This prevents confusion and ensures proper coordination among routers.
Without VRIDs, it would be difficult to manage multiple redundancy groups within the same network infrastructure. The identifier provides structure and organization, making VRRP scalable for complex environments.
Virtual IP Address and Gateway Behavior
One of the most important components of VRRP is the virtual IP address. This is the address that end devices use as their default gateway. Unlike physical router IP addresses, the virtual IP remains constant regardless of which router is currently active.
This stability is essential for network continuity. Devices do not need to update their configuration when a failover occurs. They continue sending traffic to the same gateway address, and VRRP handles the routing behind the scenes.
The virtual IP is shared among all routers in the VRRP group. However, only the active router responds to traffic directed to that address at any given time. When a failover occurs, the new active router takes over the virtual IP immediately.
This mechanism ensures that the network remains stable from the perspective of connected devices. Even though the underlying hardware may change, the gateway address remains consistent, preserving communication paths.
Advertisement Messages and Router Communication
VRRP relies heavily on communication between routers to maintain coordination. This communication is achieved through periodic advertisement messages, often referred to as “hello” messages.
These messages are sent at regular intervals from the active router to all backup routers. They serve as a signal that the active router is functioning properly. If backup routers stop receiving these messages, they assume that the active router has failed.
Advertisement messages are sent using multicast communication, allowing all routers in the VRRP group to receive updates simultaneously. This ensures fast detection of failures and quick response times.
The timing of these messages is critical. If the interval is too long, failover may be delayed. If it is too short, unnecessary traffic may be generated. VRRP balances this timing to achieve both efficiency and responsiveness.
Failover Mechanism and Seamless Transition
The failover process is one of the most important features of VRRP. It ensures that network traffic continues flowing even when the active router becomes unavailable.
When backup routers detect that the active router is no longer sending advertisement messages, they immediately initiate a transition process. The highest-priority backup router takes over the active role and assumes control of the virtual IP address.
This transition happens quickly and is designed to be transparent to end devices. In most cases, users do not notice the change, except for a brief interruption that may occur during the switch.
Once the new active router is in place, it begins sending advertisement messages to confirm its status. Other routers update their roles accordingly and continue monitoring the network.
This automated failover mechanism is what makes VRRP highly reliable for environments where continuous connectivity is essential.
VRRP Operation States and Router Behavior in Detail
To understand VRRP more deeply, it is important to look at how routers behave internally while participating in a redundancy group. VRRP does not simply switch roles randomly; instead, each router operates in clearly defined states that control how it reacts to network conditions and other routers in the group.
A router in VRRP typically moves through three main states: Initialize, Backup, and Master. These states determine whether a router is currently active, waiting, or transitioning.
When a router first starts or VRRP is enabled, it enters the Initialize state. In this stage, the router is not yet participating in the VRRP election process. It performs basic setup tasks and checks whether the interface is operational.
Once initialization is complete, the router transitions into the Backup state. In this mode, the router monitors the active router by listening to advertisement messages. It does not forward traffic for the virtual IP address but remains fully prepared to take over if needed.
The Master state is assigned to the router currently responsible for forwarding traffic to and from the virtual IP address. Only one router can be in this state at a time within a VRRP group. The Master router continuously sends advertisement messages to confirm its active status.
These states ensure structured behavior within the VRRP system. Instead of multiple routers competing for control, each device knows exactly what role it should play at any given time.
VRRP Timers and Their Role in Network Stability
Timers play a critical role in how VRRP detects failures and maintains synchronization between routers. Without carefully configured timers, failover could either happen too slowly or trigger unnecessary switches.
The two most important timers in VRRP are the advertisement interval and the master down interval.
The advertisement interval defines how often the Master router sends status messages to Backup routers. These messages confirm that the active router is still functioning correctly. A shorter interval results in faster failure detection but increases network traffic slightly.
The master down interval determines how long Backup routers wait before assuming that the Master router has failed. If no advertisement messages are received within this period, a new election process begins.
These timers are carefully balanced to ensure fast recovery without causing instability. If timers are set too aggressively, temporary network delays might be misinterpreted as failures, leading to unnecessary role changes. On the other hand, overly long timers can delay failover and increase downtime.
In enterprise environments, timer tuning is often customized based on network size, traffic sensitivity, and hardware reliability.
Preemption and Router Priority Re-Evaluation
Preemption is an important VRRP feature that controls whether a higher-priority router can reclaim the Master role after it becomes available again.
When preemption is enabled, a router with a higher priority can take over the Master role even if another router is currently active. This ensures that the most capable device is always responsible for handling traffic.
For example, if a backup router becomes active due to a failure, it may continue operating as the master even after the original router comes back online. However, if preemption is enabled, the original higher-priority router will reclaim its role once it is stable again.
This behavior is useful in networks where certain routers are preferred due to better performance, higher capacity, or strategic placement in the infrastructure.
On the other hand, disabling preemption can provide stability by preventing unnecessary role changes. In some environments, frequent switching between routers may cause temporary disruptions or routing inconsistencies.
The decision to enable or disable preemption depends on network design priorities and operational requirements.
VRRP Load Distribution Limitations and Workarounds
Although VRRP is primarily designed for redundancy, it is not inherently a load-balancing protocol. Only one router actively forwards traffic at any given time within a VRRP group, which means traffic is not distributed across multiple routers by default.
This design simplifies failover but can lead to underutilization of backup routers during normal operation. All standby routers remain idle until needed.
However, network engineers sometimes implement multiple VRRP groups to achieve a form of load distribution. By assigning different virtual IP addresses to different groups, traffic from different subnets or devices can be distributed across multiple active routers.
For example, one router may act as Master for one VRRP group while serving as Backup in another. This creates a balanced workload across the network while still maintaining redundancy.
Although this approach is not true load balancing in the traditional sense, it provides a practical workaround for maximizing resource usage in VRRP-based networks.
Comparison of VRRP with Other Redundancy Protocols
VRRP is not the only protocol designed for gateway redundancy. Other similar protocols include Hot Standby Router Protocol (HSRP) and Gateway Load Balancing Protocol (GLBP). While they share similar goals, their implementations differ in key ways.
HSRP, commonly used in Cisco environments, operates in a similar manner to VRRP but uses different terminology, such as Active and Standby routers. It is a proprietary protocol, whereas VRRP is an open standard, making it more widely supported across different vendors.
GLBP, on the other hand, provides actual load balancing by allowing multiple routers to actively forward traffic simultaneously. This makes it more efficient in terms of resource usage but also more complex to configure and manage.
VRRP strikes a balance between simplicity and reliability. Its open-standard nature allows interoperability between different hardware manufacturers, making it suitable for mixed-vendor environments.
While GLBP may offer better load distribution and HSRP may integrate more tightly with Cisco systems, VRRP remains one of the most widely adopted redundancy protocols due to its simplicity and compatibility.
VRRP Authentication and Security Considerations
In network environments where security is a concern, VRRP includes optional authentication mechanisms to prevent unauthorized devices from participating in the redundancy group.
Without authentication, a malicious or misconfigured device could potentially join a VRRP group and disrupt routing behavior. Authentication ensures that only trusted routers can participate in the VRRP process.
There are different types of authentication methods available depending on implementation, ranging from simple password-based authentication to more secure cryptographic techniques.
When authentication is enabled, routers must share the same credentials to communicate and participate in the VRRP group. Any router that fails authentication checks is ignored by the rest of the group.
Although authentication adds a layer of security, it also introduces configuration complexity. Network administrators must carefully manage credentials and ensure consistency across all routers in the group.
In modern secure networks, authentication is often considered a best practice, especially in environments where multiple administrative domains or external connections exist.
Interface Tracking and Dynamic Priority Adjustment
One advanced feature of VRRP is interface tracking, which allows routers to adjust their priority dynamically based on the status of specific interfaces.
Instead of relying on a fixed priority value, a router can reduce its priority if a critical interface goes down. This ensures that a more suitable router takes over the Master role when necessary.
For example, if a router loses connectivity to an upstream network while still being operational locally, it may not be ideal for it to remain the active gateway. Interface tracking automatically lowers its priority, allowing another router with better connectivity to take over.
This dynamic adjustment improves overall network efficiency and ensures that traffic always flows through the most optimal path.
Interface tracking is particularly useful in complex networks with multiple uplinks, redundant connections, or varying bandwidth conditions.
VRRP Convergence and Failover Speed
Convergence refers to the time it takes for the network to stabilize after a change, such as a router failure. In VRRP, convergence speed is a critical factor that affects user experience during failover events.
Fast convergence ensures minimal disruption, while slow convergence can result in noticeable delays or connection drops.
Several factors influence VRRP convergence speed, including timer settings, network latency, router processing power, and interface detection speed.
In optimized configurations, VRRP can achieve near-instant failover, often within a few seconds or less. However, in poorly tuned environments, convergence may take longer, leading to temporary service interruptions.
Network engineers often test failover scenarios to measure convergence performance and adjust configurations accordingly.
Common VRRP Deployment Scenarios in Enterprise Networks
VRRP is widely used in enterprise environments where high availability is required. One of the most common deployment scenarios is in branch office networks, where a single gateway is critical for internet access.
In such setups, two or more routers are deployed at the network edge. These routers share a virtual IP address that serves as the default gateway for all internal devices.
Another common scenario is data center edge routing, where VRRP ensures continuous access to external services even during hardware maintenance or failure.
VRRP is also frequently used in campus networks, where multiple buildings or departments rely on shared network infrastructure. By implementing VRRP, administrators ensure that users experience uninterrupted connectivity even during planned upgrades or unexpected outages.
Troubleshooting VRRP Issues in Real Networks
Despite its reliability, VRRP configurations can sometimes encounter issues that affect performance or failover behavior. Troubleshooting VRRP typically involves checking router states, interface status, and timer synchronization.
One common issue is split-brain scenarios, where multiple routers incorrectly believe they are the Master. This can occur due to network segmentation or failed communication between routers.
Another issue involves misconfigured priorities, which may result in unexpected Master selection. If priorities are not carefully assigned, a less capable router may become active.
Interface failures, incorrect VRID configuration, and authentication mismatches are also common sources of VRRP problems.
Effective troubleshooting requires a structured approach, starting with verifying VRRP states, checking logs, and ensuring consistent configuration across all routers.
Design Considerations for Scalable VRRP Architectures
Designing a scalable VRRP environment requires careful planning. As networks grow, the number of VRRP groups and participating routers may increase significantly.
One important consideration is the segmentation of VRRP groups based on network topology. Instead of using a single large group, multiple smaller groups can improve performance and manageability.
Another factor is redundancy planning at different network layers. VRRP is typically used at the gateway layer, but it should be integrated with other redundancy mechanisms at the switching and routing levels.
Hardware selection also plays a role in scalability. Routers with higher processing capacity and faster failover capabilities are better suited for large VRRP deployments.
Proper documentation and consistent configuration practices are essential to maintain long-term stability in scalable environments.
VRRP Packet Structure and Under-the-Hood Communication Mechanism
To fully understand how VRRP operates in real network environments, it is useful to examine what actually happens at the packet level when routers communicate. While VRRP appears simple from a configuration perspective, its internal communication relies on carefully structured messages exchanged between routers.
VRRP uses a specific multicast address for communication between participating routers. This ensures that all routers within the same redundancy group can receive updates without requiring individual connections between each device. The communication is efficient and designed to minimize overhead while maintaining constant awareness of router status.
Each VRRP advertisement message contains critical information, including the VRID, priority value, and the state of the sending router. These messages are small in size but highly important for maintaining synchronization between devices.
The advertisement packet also includes an authentication field (if enabled), ensuring that only authorized routers can participate in the VRRP group. Additionally, it carries timing information that helps backup routers determine when the master router is still active.
This structured communication ensures that VRRP remains lightweight while still being highly responsive. Even in large networks, these packets do not create significant congestion, making VRRP suitable for environments where performance and efficiency are critical.
Multicast Behavior and Network Traffic Flow in VRRP
VRRP relies heavily on multicast communication rather than broadcast or unicast messaging. This design choice is intentional, as multicast provides an efficient way to deliver messages to multiple routers simultaneously without overwhelming the network.
The multicast group used by VRRP ensures that all routers participating in a redundancy group receive the same advertisement messages at the same time. This eliminates the need for duplicate transmissions and reduces unnecessary network load.
In practice, this means that VRRP traffic remains localized within the network segment where the routers reside. It does not propagate across unrelated segments, which helps maintain network efficiency and prevents unnecessary traffic flooding.
Multicast behavior also plays an important role in failover detection. Since all routers receive advertisements simultaneously, they can quickly determine when the master router stops sending updates. This shared awareness is what enables VRRP to achieve fast convergence times.
However, multicast traffic must be properly supported by network switches and infrastructure devices. In environments where multicast is filtered or misconfigured, VRRP may fail to operate correctly, leading to failover delays or synchronization issues.
VRRP Version Differences and IPv6 Support (VRRPv3)
As networks have evolved, VRRP has also adapted to support modern protocols and addressing schemes. One of the most significant improvements is VRRP version 3, which introduces support for both IPv4 and IPv6 environments.
Earlier versions of VRRP were primarily designed for IPv4 networks, but VRRPv3 extends functionality to handle IPv6 addresses seamlessly. This makes it suitable for modern infrastructures where IPv6 adoption is increasing.
VRRPv3 also introduces improvements in efficiency and compatibility. It refines certain timing mechanisms and enhances interoperability between devices from different vendors. This is particularly important in multi-vendor environments where consistent behavior is required across diverse hardware platforms.
Another key improvement in VRRPv3 is better alignment with modern networking standards, making it more suitable for high-performance environments such as data centers and cloud infrastructures.
Despite these enhancements, the core principles of VRRP remain unchanged. The concept of a virtual router, shared IP address, and master-backup role structure continues to define how the protocol operates.
Vendor Interoperability and Real-World Deployment Considerations
One of the strengths of VRRP is its status as an open standard. Unlike proprietary protocols, VRRP can operate across devices from different manufacturers, making it highly flexible in heterogeneous network environments.
This interoperability allows organizations to design networks without being locked into a single vendor ecosystem. For example, routers from different manufacturers can participate in the same VRRP group as long as they follow the same protocol standards.
However, in real-world deployments, slight differences in implementation may still exist. These differences can affect timer behavior, default priority values, or configuration syntax. As a result, careful planning is required when integrating devices from multiple vendors.
In enterprise environments, it is common to standardize VRRP configurations to ensure consistent behavior. This includes aligning timer values, priority settings, and authentication methods across all devices.
Proper testing in a controlled environment is often necessary before deploying VRRP in production networks, especially when multiple vendors are involved.
Failure Scenarios and Edge Case Behavior in VRRP Networks
While VRRP is designed to handle failures gracefully, it is important to understand how it behaves under unusual or extreme conditions. Not all failure scenarios are straightforward, and some edge cases can lead to unexpected behavior if not properly accounted for.
One such scenario is the simultaneous failure of multiple routers within a VRRP group. If all routers lose connectivity or become unavailable at the same time, the virtual IP address cannot be maintained, resulting in a complete loss of gateway functionality.
Another edge case occurs when network segmentation prevents VRRP messages from being delivered correctly. In such cases, routers may incorrectly assume that the master has failed, triggering unnecessary elections and instability.
Split-brain situations can also occur when communication between routers is disrupted, but both routers continue functioning independently. In this case, multiple routers may believe they are the master, leading to conflicting traffic paths.
These scenarios highlight the importance of proper network design, redundancy planning, and infrastructure reliability when implementing VRRP.
Monitoring and Observability in VRRP Deployments
Monitoring VRRP performance is essential for maintaining a stable and reliable network environment. Without proper visibility, it becomes difficult to detect issues before they impact users.
Network administrators typically monitor VRRP status using router logs, SNMP-based monitoring systems, or built-in diagnostic tools provided by networking equipment. These tools allow real-time tracking of master and backup states, failover events, and timer synchronization.
One of the most important metrics to monitor is state transitions. Frequent changes between master and backup roles may indicate instability in the network or misconfigured timers.
Another important aspect of monitoring is interface health. Since VRRP relies on interface availability, any instability at the physical or data link layer can directly affect redundancy behavior.
In more advanced environments, monitoring systems may also track multicast traffic patterns to ensure that VRRP advertisements are being transmitted and received correctly.
VRRP in Virtualized and Cloud-Based Network Environments
As networking has evolved beyond traditional hardware-based infrastructure, VRRP has also found relevance in virtualized and cloud-based environments. Virtual routers, software-defined networking (SDN), and cloud gateways often rely on redundancy mechanisms similar to VRRP.
In virtualized environments, VRRP can be implemented between virtual machines acting as routers. This allows cloud-based systems to maintain high availability even when underlying physical hosts experience issues.
Cloud environments often abstract networking layers, but the principle of gateway redundancy remains the same. Multiple virtual instances may share a virtual IP address, ensuring continuous service availability.
However, cloud-based implementations may differ in how failover is handled internally. Some platforms use proprietary mechanisms inspired by VRRP rather than implementing the protocol directly.
Despite these differences, the conceptual model of a shared virtual gateway remains consistent across both physical and virtual environments.
Performance Optimization and Timing Adjustments in VRRP
Optimizing VRRP performance involves careful tuning of timers, priorities, and interface tracking mechanisms. While default configurations are suitable for most environments, high-performance networks often require more precise adjustments.
Reducing advertisement intervals can improve failover speed, allowing backup routers to detect failures more quickly. However, this must be balanced against increased control traffic.
Adjusting priority values based on router capacity, location, or load ensures that the most suitable device remains active under normal conditions. This prevents inefficient routing decisions and improves overall network performance.
Interface tracking can also be used to dynamically adjust router priorities based on real-time conditions. This ensures that traffic always flows through the most optimal path, even if network conditions change unexpectedly.
Performance tuning is often an iterative process, requiring testing and validation to achieve the best balance between speed, stability, and efficiency.
Security Risks and Operational Hardening of VRRP
Although VRRP is primarily designed for redundancy, it can also introduce security risks if not properly secured. Unauthorized participation in a VRRP group can disrupt routing behavior and potentially redirect traffic.
One potential risk is spoofing, where a malicious device sends false VRRP advertisements to take over the master role. This can lead to traffic interception or denial of service.
To mitigate these risks, authentication mechanisms are often used to restrict participation in VRRP groups. Only routers with valid credentials are allowed to exchange messages.
Network segmentation is another important security measure. By isolating VRRP traffic within secure network segments, administrators can reduce exposure to unauthorized devices.
Operational hardening also includes strict configuration control, ensuring that only authorized changes are made to VRRP settings.
Advanced Design Patterns Using VRRP in Large Networks
In large-scale networks, VRRP is often used as part of a broader redundancy architecture. Instead of relying on a single VRRP group, multiple groups are deployed across different network segments.
This approach allows for distributed redundancy, where different routers handle different portions of the network under normal conditions. It also improves scalability by distributing load across multiple devices.
Another advanced design pattern involves combining VRRP with dynamic routing protocols. In such setups, VRRP handles gateway redundancy while routing protocols manage path selection within the broader network.
This layered approach ensures both local and global resilience, allowing networks to remain operational even during complex failure scenarios.
Common Misconfigurations and Their Impact on Network Stability
Misconfiguration is one of the most common causes of VRRP issues in real-world networks. Even small errors can lead to significant instability or unexpected failover behavior.
One frequent issue is inconsistent VRID configuration across routers. If routers are not assigned the same VRID, they will not form a proper redundancy group.
Another common problem is mismatched virtual IP addresses, which prevent devices from recognizing the correct gateway.
Incorrect priority settings can also lead to undesirable master selection, where less capable routers handle traffic unnecessarily.
These issues highlight the importance of careful configuration management and thorough validation before deploying VRRP in production environments.
VRRP Behavior During Network Congestion and Latency Conditions
Network congestion and latency can significantly affect how VRRP behaves in real environments. Since VRRP relies on the timely exchange of advertisement messages, delays in packet delivery can influence failover decisions.
In high-latency environments, backup routers may incorrectly assume that the master router has failed, triggering unnecessary failover events. This can lead to instability and frequent role changes.
Similarly, network congestion can delay VRRP messages, making it appear as though the master router is unresponsive.
To mitigate these issues, timer values must be carefully adjusted based on network conditions. In stable, low-latency networks, shorter timers can improve responsiveness. In high-latency environments, longer timers may be necessary to prevent false failovers.
Understanding how VRRP behaves under different network conditions is essential for maintaining stability in diverse infrastructure environments.
VRRP Convergence Optimization in High-Density Networks
In high-density network environments such as enterprise campuses, data centers, and service provider backbones, VRRP behavior must be carefully tuned to maintain consistent performance under heavy traffic conditions. While basic VRRP operation ensures redundancy, convergence optimization focuses on reducing the time it takes for a backup router to assume control during a failure event without introducing instability.
One of the most effective ways to optimize convergence is by carefully balancing advertisement intervals with detection sensitivity. When routers exchange VRRP advertisements too frequently, they may react aggressively to minor network delays, causing unnecessary role changes. On the other hand, overly relaxed timers can slow down failover response, increasing service disruption during actual outages. Finding the right balance requires understanding the latency characteristics and traffic load of the network.
Another important factor is interface reliability. In high-density environments, network interfaces may experience temporary congestion or microbursts of traffic. VRRP systems that are too sensitive to these fluctuations may interpret them as failures. To avoid this, administrators often pair VRRP with interface monitoring thresholds that filter out short-lived disturbances while still detecting real hardware or link failures.
Hardware performance also plays a role in convergence optimization. Routers with faster processing capabilities can handle VRRP state transitions more efficiently, especially in environments where multiple redundancy groups exist. In such cases, CPU load and control plane capacity must be considered during design to prevent delays in failover processing.
Additionally, reducing configuration complexity improves convergence stability. When VRRP is deployed across multiple segments with consistent priority schemes and synchronized settings, the election process becomes more predictable. This reduces the chance of oscillations where routers repeatedly switch between master and backup states.
In modern networks, convergence optimization is not treated as a one-time configuration task but as an ongoing tuning process. Continuous monitoring of failover events, packet loss patterns, and timing accuracy helps refine VRRP performance over time, ensuring that redundancy mechanisms remain both fast and stable under real operational conditions.
Conclusion
Virtual Router Redundancy Protocol (VRRP) stands as one of the most practical and widely adopted mechanisms for ensuring network gateway reliability in modern local area networks. Its primary strength lies in its ability to eliminate a single point of failure at the router level, which is often one of the most critical vulnerabilities in traditional network designs. By allowing multiple physical routers to function as a single virtual gateway, VRRP introduces a level of resilience that is essential for today’s always-connected digital environments.
At its core, VRRP simplifies what would otherwise be a complex redundancy setup. Instead of requiring end devices to manage multiple gateway addresses or rely on manual intervention during failures, VRRP provides a seamless experience through a single virtual IP address. This abstraction not only reduces configuration complexity but also ensures consistent network behavior even when underlying hardware changes occur unexpectedly.
One of the most important advantages of VRRP is its ability to perform automatic failover. When the active router becomes unavailable, backup routers quickly detect the failure and initiate a transition process without user involvement. This rapid response helps maintain uninterrupted access to external networks, which is especially critical for business applications, cloud services, and real-time communication systems.
Beyond basic redundancy, VRRP also demonstrates flexibility in how it can be deployed. It supports priority-based elections, interface tracking, and optional preemption features that allow network administrators to fine-tune behavior according to operational requirements. These capabilities make VRRP adaptable to a wide range of environments, from small office networks to large-scale enterprise infrastructures.
Another key strength of VRRP is its vendor-neutral design. As an open standard protocol, it can operate across devices from different manufacturers, making it suitable for heterogeneous network environments. This interoperability provides organizations with greater freedom in hardware selection while still maintaining a consistent redundancy strategy.
However, VRRP is not without its challenges. Proper configuration, timer tuning, and network design are essential to ensure stable operation. Misconfigurations or poor planning can lead to unnecessary failovers, instability, or even temporary loss of connectivity. As networks become more complex, careful implementation becomes increasingly important.
In modern networking, where uptime and reliability are critical, VRRP plays a foundational role in maintaining service continuity. It is not just a theoretical concept for certification exams but a real-world solution actively used in enterprise, data center, and cloud environments.
Ultimately, VRRP represents a balance between simplicity and reliability. It provides an elegant solution to a fundamental networking problem while remaining efficient and scalable. Understanding its behavior, components, and operational principles equips network professionals with the knowledge needed to design more resilient and dependable network infrastructures.