Modern virtualised infrastructures depend heavily on efficient memory usage, especially when multiple virtual machines share a single physical host. VMware’s ESXi hypervisor, part of the broader vSphere ecosystem, is designed specifically to make this possible by allowing organisations to run many virtual machines on a single server without requiring each machine to have dedicated physical memory. This approach improves hardware utilisation, reduces costs, and increases operational flexibility.
At the core of this efficiency is the concept of memory overcommitment. In traditional physical systems, memory is strictly allocated: what is installed is what can be used. However, in virtual environments, ESXi allows administrators to assign more memory to virtual machines collectively than what physically exists on the host. This is possible because virtual machines rarely use all the memory assigned to them at any given time. Instead, their memory usage fluctuates depending on workload demand.
This assumption—that not all allocated memory is actively used at once—is what enables virtualisation to be so powerful. However, it also introduces a challenge. When demand suddenly increases, and the total memory usage approaches or exceeds physical limits, ESXi must intervene to manage the situation intelligently. Without intervention, the host would run out of memory, leading to system instability or crashes. To prevent this, ESXi employs several layered memory management techniques that activate progressively as memory pressure increases.
These techniques are designed to minimise performance impact while ensuring stability. Each method has a different level of aggressiveness, starting with the least disruptive approach and gradually moving toward more performance-impacting solutions if necessary.
The Concept of Memory Overcommitment in Virtualisation
Memory overcommitment is one of the foundational principles of virtualisation efficiency. It allows administrators to allocate more virtual memory to guest machines than the physical RAM available on the host server. This works because in real-world usage, virtual machines do not consume their full allocated memory continuously.
For example, a server might have 128 GB of physical RAM, but administrators may allocate a combined total of 200 GB across multiple virtual machines. At first glance, this seems impossible, but in practice, each virtual machine only uses a fraction of its allocated memory at any moment. Some may be idle, others lightly loaded, and only a few may experience high demand simultaneously.
This imbalance creates an opportunity for the hypervisor to optimise memory usage dynamically. Instead of reserving memory permanently for each virtual machine, ESXi monitors actual usage patterns and reclaims unused or redundant memory where possible. This allows the system to run more workloads on the same hardware without immediate upgrades.
However, overcommitment also introduces risk. If too many virtual machines suddenly require their allocated memory simultaneously, the host may face memory pressure. This is when ESXi’s memory management techniques become essential, ensuring that performance degradation is controlled and predictable rather than catastrophic.
Transparent Page Sharing and Memory Deduplication
One of the earliest and least intrusive memory optimisation techniques used by ESXi is Transparent Page Sharing, commonly referred to as TPS. This method focuses on eliminating redundant memory content across virtual machines.
In many virtual environments, multiple virtual machines may be running identical operating systems or applications. As a result, they often store identical memory pages. Instead of allowing each virtual machine to maintain its own duplicate copy of the same data, TPS identifies these identical memory pages and consolidates them into a single shared copy on the physical host.
This process is completely transparent to the virtual machines, meaning they continue to operate as if they each have their own private memory space. When a virtual machine attempts to modify a shared page, the hypervisor creates a private copy of that page for that specific machine, ensuring isolation and data integrity.
TPS can significantly reduce memory consumption, especially in environments where many similar virtual machines are running. However, its effectiveness depends on workload similarity. Heterogeneous environments with diverse applications may see limited benefits.
In addition to intra-VM deduplication, there is also inter-VM TPS, which allows memory sharing between different virtual machines. This can result in even greater memory savings when many similar workloads are hosted on the same server.
However, in modern ESXi versions, inter-VM TPS is often restricted or disabled by default due to security considerations. The concern is that shared memory pages could potentially introduce side-channel risks where one virtual machine might infer information about another. As a result, VMware prioritises isolation over maximum memory efficiency in certain configurations.
Despite these limitations, TPS remains an important baseline optimisation technique that helps reduce overall memory consumption before more aggressive methods are needed.
Introduction to Memory Ballooning in ESXi
When memory demand increases beyond what TPS can handle, ESXi turns to its next major technique: memory ballooning. This method is one of the most widely recognised and important memory management strategies in virtualisation environments.
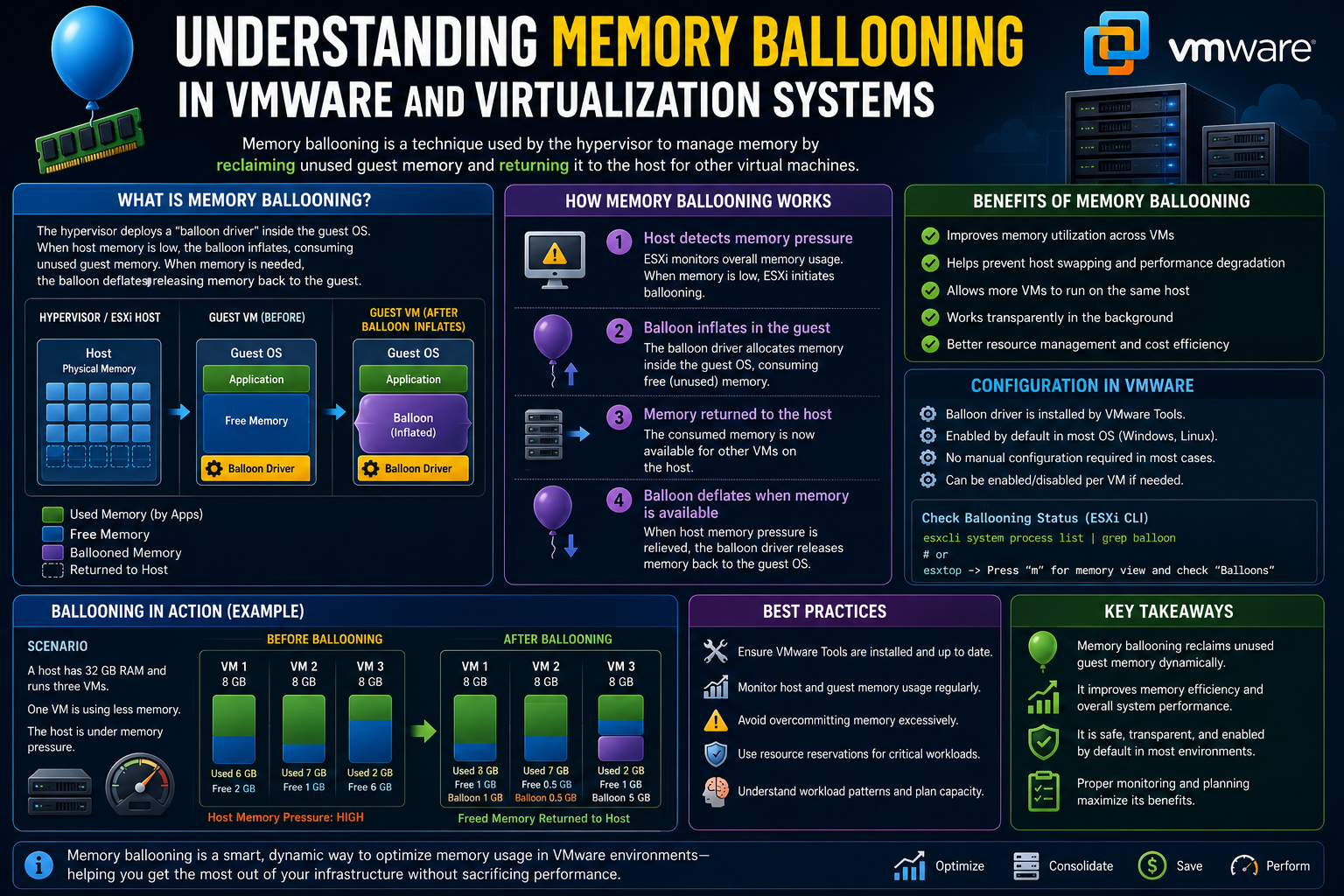
Memory ballooning is designed to reclaim unused memory from virtual machines in a controlled and intelligent way. Unlike traditional swapping, which moves memory to disk, ballooning works by interacting directly with the guest operating system inside the virtual machine.
For ballooning to function, VMware Tools must be installed inside each virtual machine. This is because the balloon driver operates as a component within the guest operating system. Once active, it acts as a communication bridge between the hypervisor and the virtual machine’s memory manager.
When ESXi detects memory pressure on the host, it signals the balloon driver inside selected virtual machines to begin “inflating.” This means the driver starts allocating memory within the guest operating system, effectively consuming idle memory pages that are not actively used by applications.
As the balloon inflates, the guest operating system is forced to identify and release unused memory pages. These pages are then reclaimed by the hypervisor and made available for other virtual machines that require additional memory.
This process is efficient because it targets idle or underutilised memory rather than actively used memory. In most cases, users and applications do not notice any impact, which is why ballooning is considered a non-disruptive or minimally disruptive technique.
How Memory Ballooning Works Inside the Guest Operating System
To understand ballooning more deeply, it is important to examine what happens inside the virtual machine when the balloon driver is activated.
The balloon driver behaves like a memory-consuming application from the perspective of the guest operating system. When it inflates, it requests memory allocations from the operating system, just like any normal application would. The operating system responds by allocating physical memory pages to the driver.
However, since this memory request is artificial and controlled by the hypervisor, the driver does not actually use the memory for computation. Instead, it simply holds onto it, forcing the operating system to reclaim unused memory from other processes.
The operating system, under pressure, begins to identify memory pages that are least important or inactive. These pages are then freed or swapped out at the guest level, depending on the operating system’s own memory management policies.
Once these pages are freed, ESXi can reclaim them from the virtual machine and redistribute them to other workloads on the host.
The key advantage of this approach is that memory is reclaimed based on actual usage patterns inside the virtual machine, not just external assumptions. This makes ballooning a highly adaptive and efficient mechanism.
However, ballooning is not unlimited. Each virtual machine has a maximum balloon size, and if memory pressure continues to increase, ESXi may need to escalate to more aggressive techniques.
The Role of VMware Tools in Ballooning Operations
VMware Tools plays a critical role in enabling memory ballooning. Without it, the balloon driver cannot function, and ESXi loses a key mechanism for reclaiming memory efficiently.
When VMware Tools is installed, it integrates the balloon driver into the guest operating system. This allows direct communication between ESXi and the virtual machine’s memory manager.
If VMware Tools is not installed, ESXi cannot use ballooning and must rely on more disruptive methods such as compression or swapping earlier in the process. This can lead to performance degradation under memory pressure conditions.
For this reason, maintaining updated VMware Tools installations across all virtual machines is essential for optimal memory management.
Early Indicators of Memory Pressure in Virtual Environments
Memory ballooning also serves as an early warning indicator of memory pressure within a virtualised environment. When ballooning activity is observed, it often signals that the host is approaching its memory limits.
Administrators can monitor ballooning behaviour using performance metrics provided by the hypervisor. Increasing balloon activity over time may indicate that workloads are becoming too dense for the available physical memory.
This information is valuable for capacity planning. It can highlight the need to redistribute workloads across additional hosts or adjust memory allocations for specific virtual machines.
Unlike more aggressive techniques such as swapping, ballooning provides a warning stage where corrective action can still be taken before performance is significantly impacted.
Limitations and Practical Considerations of Ballooning
Although memory ballooning is highly effective, it is not without limitations. Its effectiveness depends on the availability of unused memory within virtual machines. If a virtual machine is already fully utilising its memory, ballooning cannot reclaim additional resources without impacting performance.
Additionally, workloads such as databases or in-memory analytics systems may experience performance degradation if ballooning forces them to release actively used memory. In such cases, careful memory reservation strategies may be required.
Another consideration is that excessive reliance on ballooning may indicate poor resource planning. Ideally, a well-balanced virtual environment should experience minimal ballooning activity, as this suggests that memory allocation is properly aligned with workload demands.
When ballooning occurs frequently, it may signal the need for infrastructure scaling or workload redistribution across additional hosts.
Memory Compression Mechanism in Depth
When memory pressure continues to increase beyond what Transparent Page Sharing and memory ballooning can handle, ESXi introduces another layer of reclamation known as memory compression. This technique acts as a middle ground between non-disruptive memory reclamation and more performance-impacting methods like swapping.
Memory compression works by identifying memory pages that are not actively in use but still contain data that cannot be immediately discarded or reclaimed. Instead of writing these pages to disk, ESXi compresses them and stores the compressed versions in a reserved memory area within the host.
The primary goal of compression is to reduce the physical footprint of memory pages while still keeping them in RAM. Since accessing compressed memory is significantly faster than retrieving it from disk, this approach helps maintain better performance compared to swapping.
Compression is typically applied selectively. ESXi does not compress all memory pages, but instead targets those that are least likely to be accessed in the near future. This selective process helps maintain a balance between performance and memory efficiency.
The compression ratio depends on the type of data stored in memory. Some workloads compress very efficiently, while others may not benefit as much. Even when compression is effective, it is still considered a temporary relief mechanism rather than a long-term solution.
Because compressed memory still consumes some CPU resources for compression and decompression operations, there is a measurable performance cost. However, this cost is usually lower than the latency introduced by disk-based swapping.
ESXi Memory States and Host Memory Pressure Levels
To manage memory effectively, ESXi continuously monitors the state of physical memory on the host. Based on available resources, the hypervisor categorises memory conditions into different states that determine which reclamation techniques should be activated.
These memory states generally fall into four broad categories: high availability, soft contention, hard contention, and low memory state. Each state represents a different level of memory pressure and triggers different responses from the hypervisor.
In a healthy system, the host remains in a high availability state, where sufficient free memory exists, and no reclamation techniques are required. Virtual machines operate without interference, and memory overcommitment remains stable.
When free memory begins to decline, the system transitions into a soft contention state. At this stage, ESXi begins activating non-intrusive techniques such as Transparent Page Sharing and memory ballooning. These methods aim to reclaim unused memory without affecting performance significantly.
If memory pressure continues to increase, the system enters a hard contention state. This is where more aggressive techniques, such as compression and swapping, begin to appear. At this stage, performance degradation becomes more noticeable.
Finally, in a low memory state, ESXi has exhausted most reclamation options and relies heavily on swapping to maintain system stability. This state is undesirable and typically indicates severe overcommitment or misconfigured workloads.
Understanding these states is essential for diagnosing memory-related performance issues and determining when corrective actions are required.
Memory Swapping and Its Impact on Performance
Memory swapping represents the most aggressive and performance-impacting memory management technique in ESXi. When all other reclamation methods fail to free enough memory, the hypervisor begins moving memory pages from physical RAM to disk-based storage.
Each virtual machine has a dedicated swap file that is created when the machine is powered on. This file resides on disk and is used as a temporary extension of physical memory when needed.
When ESXi decides to swap memory, it selects inactive memory pages and writes them to the swap file. Later, when those pages are needed again, they must be read back into memory from disk. This process introduces significant latency because disk access is much slower than RAM access.
The performance impact of swapping depends on the type of storage used. Even with high-performance storage systems, disk access is still orders of magnitude slower than memory access. As a result, workloads experiencing heavy swapping often suffer noticeable slowdowns.
Swapping is considered a last-resort mechanism because it directly affects application responsiveness. Unlike ballooning or compression, which attempt to reclaim unused memory, swapping can affect actively used memory pages, leading to performance degradation.
In-Guest vs Hypervisor-Level Swapping Differences
It is important to distinguish between two types of swapping that occur in virtual environments: hypervisor-level swapping and in-guest swapping.
Hypervisor-level swapping is managed by ESXi and occurs when the host is under memory pressure. In this case, ESXi decides which memory pages to swap to disk, independent of the guest operating system. This type of swapping is generally more disruptive because the hypervisor does not have full awareness of application-level memory usage.
In contrast, in-guest swapping is handled by the operating system inside the virtual machine. When the guest OS runs low on memory, it may begin swapping memory pages to its own swap file. This process is controlled entirely by the operating system and is influenced by its internal memory management policies.
While both types of swapping degrade performance, in-guest swapping is often more predictable because the operating system is aware of application priorities. Hypervisor-level swapping, however, can interfere with workloads in a less coordinated manner.
When both types of swapping occur simultaneously, performance issues can become severe. This situation is often referred to as double swapping and is a strong indicator of memory exhaustion.
Active Memory, Consumed Memory, and Granted Memory
To properly understand memory behaviour in ESXi, it is important to distinguish between different memory metrics used by the hypervisor.
Active memory refers to the amount of memory that is currently being used by applications within a virtual machine. This represents the working set of the workload and is the most critical metric for performance analysis.
Consumed memory represents the total physical memory that has been allocated to a virtual machine by the hypervisor. This includes both active and inactive memory pages.
Granted memory is the amount of memory that the hypervisor has made available to a virtual machine. This value can change dynamically based on memory reclamation techniques such as ballooning.
Understanding the difference between these metrics is essential for identifying whether memory pressure is affecting actual workload performance or simply reflecting unused allocated memory.
For example, a virtual machine may have high consumed memory but low active memory, indicating that it has more memory than it currently needs. In such cases, ESXi can safely reclaim memory without impacting performance.
NUMA Awareness and Memory Placement Optimisation
Modern physical servers often use Non-Uniform Memory Access (NUMA) architectures, where memory is divided into multiple nodes associated with specific CPU sockets. Accessing memory within the same NUMA node is faster than accessing memory across nodes.
ESXi is NUMA-aware, meaning it tries to allocate memory to virtual machines in a way that keeps CPU and memory access localised within the same NUMA node. This reduces latency and improves performance.
When virtual machines are sized incorrectly or exceed NUMA boundaries, performance can degrade due to increased memory access latency. ESXi attempts to mitigate this by balancing memory placement dynamically, but optimal performance still depends on proper virtual machine sizing.
Large virtual machines that span multiple NUMA nodes may experience uneven memory performance if not carefully configured. In such cases, memory access patterns become less efficient, leading to potential bottlenecks.
NUMA optimisation is particularly important in high-performance workloads such as databases and analytics systems, where memory access speed directly affects processing efficiency.
Role of vSphere Distributed Resource Scheduler in Memory Balancing
The vSphere Distributed Resource Scheduler (DRS) plays a critical role in maintaining balanced memory usage across multiple hosts in a cluster. While ESXi manages memory at the individual host level, DRS operates at the cluster level to ensure optimal workload distribution.
When memory pressure increases on a specific host, DRS can automatically migrate virtual machines to other hosts with available memory. This process helps prevent sustained memory contention and reduces reliance on aggressive reclamation techniques.
DRS evaluates resource usage across the entire cluster and makes placement decisions based on current demand. It continuously monitors CPU and memory usage patterns to ensure that no single host becomes overloaded.
By distributing workloads evenly, DRS helps reduce the likelihood of ballooning, compression, and swapping. This leads to more stable performance across the entire virtual environment.
However, effective DRS operation depends on proper configuration and sufficient cluster capacity. If all hosts are heavily utilised, DRS may have limited ability to rebalance workloads.
Memory Reservations, Limits, and Shares Explained
ESXi provides several configuration controls that allow administrators to manage memory allocation behaviour for virtual machines. These include reservations, limits, and shares.
Memory reservation guarantees a minimum amount of physical memory for a virtual machine. When a reservation is set, that portion of memory is always available to the virtual machine and cannot be reclaimed by the hypervisor. This is useful for critical workloads that require consistent performance.
Memory limits define the maximum amount of memory a virtual machine is allowed to use, regardless of available host resources. While limits can prevent resource overconsumption, they can also lead to performance bottlenecks if set too low.
Memory shares determine priority when multiple virtual machines compete for memory. In contention scenarios, virtual machines with higher share values receive preferential access to available memory.
These controls allow fine-grained tuning of memory allocation behaviour, but they must be used carefully. Improper configuration can lead to inefficient resource utilisation or unintended performance issues.
Detecting Memory Contention Using Performance Metrics
Monitoring memory behaviour is essential for maintaining a healthy virtual environment. ESXi provides several tools and metrics that help identify memory contention.
One of the most important indicators is memory ballooning activity. Increasing balloon usage often signals that the host is under memory pressure and actively reclaiming memory from virtual machines.
Another key indicator is swap usage. If swap activity is present, it suggests that memory pressure has exceeded the capacity of non-disruptive reclamation methods.
Compression activity is also a useful indicator, showing that the system is under moderate to high memory pressure.
Tools such as esxtop provide real-time visibility into memory usage, including active memory, consumed memory, and balloon statistics. These metrics help administrators identify which virtual machines are contributing most to memory pressure.
Practical Memory Overcommit Strategy in Production Environments
Effective memory overcommitment requires careful planning rather than aggressive allocation. While overcommitment allows higher consolidation ratios, it must be balanced against workload behaviour.
In production environments, memory allocation should be based on observed usage patterns rather than theoretical maximum requirements. This helps avoid unnecessary pressure on the hypervisor.
Workloads with stable memory usage are ideal candidates for overcommitment. In contrast, workloads with unpredictable spikes require more conservative allocation strategies.
Balancing memory across multiple hosts also helps reduce pressure on individual systems. This ensures that no single host becomes a bottleneck.
A well-designed strategy considers workload type, peak usage patterns, and available infrastructure capacity.
Common Misconfigurations Leading to Memory Pressure Issues
Many memory-related performance issues arise from misconfigurations rather than hardware limitations. One common issue is over-provisioning memory without considering actual workload usage patterns.
Another frequent problem is disabling or ignoring memory reclamation mechanisms, which prevents ESXi from efficiently managing resources.
Improper virtual machine sizing can also contribute to memory pressure. Assigning excessive memory to virtual machines that do not require it reduces overall efficiency.
Failure to distribute workloads evenly across hosts can lead to localised memory exhaustion, even when overall cluster capacity is sufficient.
Understanding these misconfigurations is essential for maintaining a stable and efficient virtual environment.
Advanced Memory Behaviour in High-Density Virtual Environments
As virtual infrastructures scale into high-density environments, memory behaviour becomes significantly more complex. In such setups, a single ESXi host may run dozens or even hundreds of virtual machines simultaneously, each with different workloads, memory usage patterns, and performance requirements. While earlier memory management techniques, such as Transparent Page Sharing, ballooning, compression, and swapping, form the foundation of ESXi’s memory control system, high-density environments introduce additional challenges that require a deeper understanding of how memory behaves under sustained pressure.
In these environments, memory is no longer just a static resource assigned to virtual machines. It becomes a constantly shifting pool of shared capacity influenced by workload spikes, idle cycles, application design, and hypervisor-level decisions. ESXi must continuously make real-time decisions about which memory pages to prioritise, which to reclaim, and which to protect based on changing demand patterns.
One of the most critical aspects of high-density memory management is the concept of temporal memory usage. Virtual machines rarely use memory uniformly over time. Instead, they exhibit bursts of activity followed by idle periods. ESXi takes advantage of these fluctuations by reclaiming memory during idle phases and reallocating it during peak demand.
However, as density increases, the probability of overlapping memory spikes across multiple virtual machines also increases. This creates a situation where multiple workloads simultaneously demand more memory than is physically available, forcing ESXi to rely more heavily on reclamation techniques.
At this stage, memory efficiency is no longer just about optimisation—it becomes a balancing act between stability and performance.
Memory Scheduling and Hypervisor-Level Decision Making
Memory management in ESXi is not reactive alone; it is also predictive and policy-driven. The hypervisor uses a memory scheduler that continuously evaluates system conditions and determines which reclamation strategy should be applied at any given moment.
This scheduling process is influenced by multiple factors, including current free memory, rate of memory consumption, virtual machine priority levels, and historical usage patterns. ESXi does not treat all virtual machines equally when reclaiming memory. Instead, it prioritises workloads based on configuration settings such as memory shares, reservations, and limits.
For example, a virtual machine configured with higher memory shares will be less likely to experience aggressive reclamation compared to a lower-priority machine. Similarly, machines with strict memory reservations are protected from ballooning and swapping, ensuring predictable performance even under pressure.
The memory scheduler also evaluates the efficiency of each reclamation technique in real time. If ballooning is yielding sufficient reclaimed memory, ESXi will continue using it and delay escalation to compression or swapping. However, if ballooning is insufficient, the system will progressively activate more aggressive methods.
This layered decision-making process ensures that memory pressure is handled in a controlled and gradual manner rather than through sudden performance disruption.
The Relationship Between CPU Scheduling and Memory Pressure
Although memory and CPU are separate resources, they are closely interconnected in virtual environments. Memory pressure can indirectly affect CPU performance, and vice versa.
When memory ballooning occurs, the guest operating system inside a virtual machine must decide which memory pages to release. This process consumes CPU cycles within the virtual machine. Similarly, compression and decompression operations require CPU resources at the hypervisor level.
As memory pressure increases, the CPU overhead associated with memory management also increases. This means that a system under heavy memory contention may also experience elevated CPU usage, even if application workloads remain unchanged.
In extreme cases, excessive memory reclamation can lead to a feedback loop where CPU resources are consumed by memory management tasks rather than application processing. This results in reduced overall system efficiency.
Understanding this relationship is important when diagnosing performance issues in virtual environments. High CPU usage does not always indicate CPU-bound workloads; it may also reflect underlying memory pressure.
Memory Hot-Add and Dynamic Resource Expansion
One of the advantages of virtualisation platforms like ESXi is the ability to dynamically adjust resources without shutting down virtual machines. Memory hot-add allows additional memory to be added to a running virtual machine, provided that the guest operating system supports this feature.
This capability is particularly useful in environments where workloads experience unpredictable spikes in memory demand. Instead of relying solely on reclamation techniques, administrators can expand memory allocations dynamically to accommodate growing workloads.
However, memory hot-add is not a replacement for proper capacity planning. It is a reactive mechanism rather than a preventive one. If multiple virtual machines frequently require memory expansion, it may indicate that the underlying infrastructure is undersized.
Additionally, memory hot-add introduces NUMA considerations. Adding memory dynamically may alter how memory is distributed across NUMA nodes, potentially affecting performance if not managed carefully.
Despite these considerations, memory hot-add remains a valuable tool for maintaining flexibility in dynamic environments.
Impact of Memory Overcommitment on Application Behaviour
Memory overcommitment is central to virtualisation efficiency, but it can have varying effects on application behaviour depending on workload type.
Stateless applications, such as web servers or lightweight services, typically handle memory overcommitment well. These workloads tend to release unused memory naturally, making them ideal candidates for shared memory environments.
In contrast, stateful applications such as databases, analytics engines, and in-memory processing systems behave differently. These applications often reserve large portions of memory for caching and performance optimisation. As a result, they may appear to be underutilising memory from the hypervisor’s perspective, even though that memory is critical for performance.
When memory reclamation techniques are applied to such workloads, performance degradation can occur. Ballooning may force the application to release cached data, compression may introduce latency, and swapping can severely impact responsiveness.
For this reason, workload classification is essential when designing overcommitted environments. Not all applications benefit equally from memory sharing, and some require strict reservations to maintain performance consistency.
Memory Fragmentation in Virtualised Systems
Memory fragmentation is another important factor that affects ESXi memory efficiency. Over time, as virtual machines allocate and release memory dynamically, the physical memory pool on the host becomes fragmented.
Fragmentation occurs when free memory is divided into small, non-contiguous blocks rather than large continuous segments. While the total available memory may appear sufficient, it may not be usable for large allocations due to fragmentation.
ESXi attempts to mitigate fragmentation through its internal memory management algorithms, including page sharing and reclamation techniques. However, complete elimination of fragmentation is not always possible, especially in long-running systems with fluctuating workloads.
Fragmentation can also impact NUMA efficiency, as memory pages may become distributed across multiple nodes in a suboptimal manner. This can increase latency and reduce overall performance.
In extreme cases, fragmentation may force ESXi to rely more heavily on compression or swapping, even when nominal free memory appears available.
Memory Latency and Its Effect on Virtual Machine Performance
Latency is a critical but often overlooked aspect of memory performance. While total memory capacity is important, the speed at which memory can be accessed has an equally significant impact on application behaviour.
In virtual environments, memory latency can be influenced by several factors, including NUMA placement, hypervisor overhead, and memory reclamation techniques.
Ballooning introduces minimal latency because it primarily affects unused memory. Compression introduces moderate latency due to CPU overhead required for decompression. Swapping introduces the highest latency because it involves disk access.
As memory pressure increases and more aggressive reclamation techniques are used, overall memory latency increases. This can result in slower application response times, even if total memory capacity remains technically sufficient.
Understanding latency behaviour is essential when diagnosing performance degradation in virtual environments. In many cases, performance issues are not caused by a lack of memory but by increased memory access delays.
Role of Memory Shares in Resource Competition Scenarios
When multiple virtual machines compete for limited memory resources, ESXi uses memory shares to determine allocation priority. Memory shares act as a weighting system that defines how memory is distributed during contention.
Virtual machines with higher share values receive a larger portion of available memory compared to those with lower values. This ensures that critical workloads maintain performance even under pressure.
Shares become particularly important during memory contention events when reclamation techniques are actively reclaiming memory from multiple virtual machines.
However, shares are relative rather than absolute. They only influence distribution during contention and do not guarantee fixed memory allocation.
Proper configuration of memory shares is essential for maintaining service quality in multi-tenant or mixed-workload environments.
Long-Term Effects of Sustained Memory Reclamation
While ESXi memory reclamation techniques are designed to handle temporary memory pressure, sustained use of these techniques can have long-term implications.
Continuous ballooning may indicate chronic overcommitment, where virtual machines are consistently allocated more memory than the host can support. Over time, this can lead to unpredictable performance behaviour.
Persistent compression activity may suggest that workloads are consistently exceeding available physical memory, forcing the hypervisor into constant optimisation mode.
Frequent swapping is the most concerning condition, as it indicates that the system is operating beyond its stable capacity. Long-term swapping can lead to severe performance degradation and instability.
In well-designed environments, reclamation techniques should operate intermittently rather than continuously. Continuous activity suggests the need for architectural adjustments.
Memory Efficiency in Mixed Workload Clusters
In real-world environments, ESXi hosts rarely run identical workloads. Instead, they operate mixed clusters containing a variety of applications with different memory profiles.
This diversity creates opportunities for memory optimisation. Idle workloads can release memory that is temporarily consumed by active workloads, improving overall efficiency.
However, mixed workloads also introduce unpredictability. Memory demand may fluctuate widely depending on application behaviour, making it difficult to predict resource requirements accurately.
ESXi handles this complexity by continuously adjusting memory allocation based on real-time demand rather than static assumptions.
The effectiveness of memory management in mixed environments depends heavily on workload balance. Proper distribution of resource-intensive and lightweight applications can significantly improve overall system efficiency.
Observing Memory Trends for Capacity Planning
Long-term memory behaviour analysis is essential for capacity planning in virtual environments. By observing trends in ballooning, compression, and swapping activity, administrators can identify whether the current infrastructure is sufficient.
Increasing ballooning trends may indicate that memory allocation is approaching physical limits. Rising compression activity suggests that memory demand is consistently high. Swapping activity signals that the system is exceeding safe operating thresholds.
These trends provide valuable insights into future infrastructure requirements. Instead of reacting to performance issues after they occur, administrators can proactively scale resources based on observed patterns.
Capacity planning based on memory trends ensures stable performance and reduces the likelihood of unexpected degradation.
Efficiency Tradeoffs in Virtual Memory Design
Every memory management technique in ESXi involves tradeoffs between efficiency, performance, and stability. Transparent Page Sharing improves efficiency but may be limited by security considerations. Ballooning provides a balanced approach but depends on guest cooperation. Compression reduces physical memory usage but increases CPU overhead. Swapping ensures stability but significantly impacts performance.
The challenge in virtual memory design is not eliminating tradeoffs, but balancing them effectively based on workload requirements.
A well-designed environment minimises reliance on aggressive techniques while maximising the benefits of non-disruptive reclamation methods.
Memory Entitlement and the Hidden Layer of Resource Allocation
In virtualised environments, memory allocation is not only about how much RAM is assigned to a virtual machine, but also about how much memory it is actually entitled to receive under current system conditions. This concept of memory entitlement becomes especially important when multiple virtual machines compete for limited resources on a shared ESXi host.
Memory entitlement represents the amount of physical memory a virtual machine is effectively guaranteed at any given moment, based on current demand, priority settings, and overall host availability. Unlike configured memory, which is a static assignment defined by administrators, entitlement is dynamic and continuously recalculated by the hypervisor.
When the host is under no memory pressure, most virtual machines receive full entitlement equal to their configured memory. However, as contention increases, ESXi begins to adjust entitlements based on factors such as memory shares and reservation policies. High-priority workloads maintain higher entitlement levels, while lower-priority machines may experience reduced access to physical memory.
This adjustment process is critical for maintaining fairness and performance stability across the environment. Without entitlement balancing, all virtual machines would compete equally for memory, potentially allowing less important workloads to consume resources needed by critical applications.
Entitlement also plays a key role in determining how aggressively memory reclamation techniques are applied. Virtual machines with lower entitlement are more likely to be selected for ballooning or compression, while those with higher entitlement are protected as much as possible.
Understanding memory entitlement provides deeper insight into how ESXi makes real-time decisions about resource distribution. It reveals that memory management is not simply about capacity, but about prioritisation, fairness, and workload awareness.
In complex virtual infrastructures, entitlement becomes a silent but powerful mechanism that ensures critical services remain responsive even under constrained conditions.
Conclusion
Memory management in VMware ESXi is not a single mechanism but a carefully layered system designed to maintain stability while maximising hardware efficiency. In modern virtualised environments, where dozens or even hundreds of workloads share the same physical resources, memory becomes one of the most critical and tightly controlled components of infrastructure performance.
The key strength of ESXi lies in its ability to overcommit memory safely. By assuming that virtual machines rarely use their full allocated memory at the same time, the hypervisor enables organisations to run significantly more workloads on the same hardware. This improves cost efficiency and resource utilisation without requiring proportional increases in physical infrastructure.
To support this model, ESXi relies on a progressive memory reclamation strategy. It begins with non-intrusive techniques like Transparent Page Sharing, which reduces redundancy by eliminating duplicate memory pages across virtual machines. When pressure increases, memory ballooning takes over, reclaiming unused memory from within guest operating systems in a controlled and generally non-disruptive manner.
If memory demand continues to rise, ESXi escalates to more aggressive methods such as memory compression, which reduces the physical footprint of inactive memory pages while keeping them in RAM for faster access. As a final safeguard, swapping ensures system stability by moving memory pages to disk when no other options remain, although at a significant performance cost.
This tiered approach ensures that memory pressure is handled gradually rather than abruptly. Each stage represents a tradeoff between performance and resource availability, allowing administrators to maintain operational continuity even under constrained conditions.
However, the effectiveness of these techniques depends heavily on proper infrastructure design. Overcommitment must be carefully balanced with workload requirements, and not all applications respond well to memory reclamation. High-performance or memory-intensive systems may require reservations or dedicated resources to maintain consistent behaviour.
Monitoring and understanding memory behaviour is also essential. Metrics such as ballooning activity, compression usage, and swapping trends provide valuable insight into the health of a virtual environment. These indicators help administrators identify inefficiencies early and make informed decisions about scaling, redistribution, or optimisation.
Ultimately, ESXi memory management reflects a sophisticated balance between automation and control. It continuously adapts to changing workload demands while protecting system stability. When properly configured and monitored, it allows organisations to achieve high levels of consolidation without sacrificing performance.
The success of virtualised memory systems depends not just on technology but on thoughtful planning, workload awareness, and ongoing optimisation.