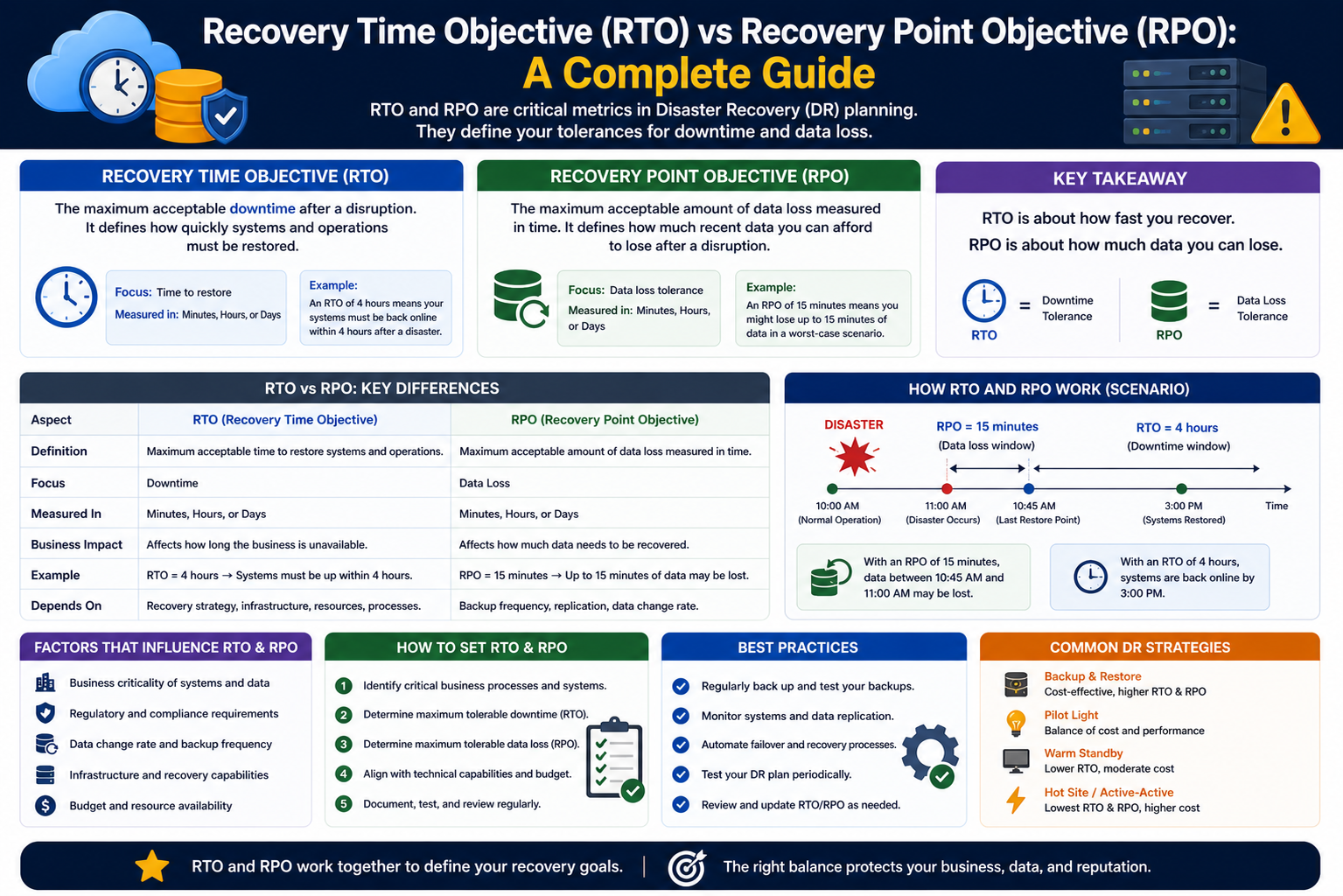
Recovery Time Objective (RTO) and Recovery Point Objective (RPO) are two essential concepts in modern IT operations that define how organizations respond to unexpected disruptions. In an environment where digital services are expected to function continuously, even a short outage can lead to serious consequences. These metrics provide a structured way to measure how quickly systems must be restored and how much data loss is acceptable during failures.
RTO focuses on the duration of downtime, while RPO focuses on the extent of data loss. Together, they form the backbone of disaster recovery planning and business continuity strategies. Organizations rely on these benchmarks to design systems that can recover efficiently while maintaining user trust and operational stability. Without clearly defined RTO and RPO values, recovery efforts become inconsistent, slow, and potentially damaging to the business.
Understanding these concepts is not just important for IT teams but also for decision-makers who need to balance cost, performance, and risk. Every system, application, and service within an organization may require different RTO and RPO targets depending on its importance. By defining these objectives properly, organizations can prepare for disruptions in a way that minimizes impact and ensures a smooth recovery process.
The Growing Importance of System Availability
In today’s digital landscape, system availability is no longer a luxury but a necessity. Users expect uninterrupted access to applications, websites, and services regardless of time or location. When a service becomes unavailable, even briefly, it can lead to frustration, lost revenue, and damage to reputation. This increasing reliance on technology has made downtime one of the most critical risks organizations face.
Businesses now operate in highly competitive environments where reliability is directly linked to customer satisfaction. A delay in accessing a service or completing a transaction can push users toward competitors. As a result, organizations must ensure that their systems are resilient enough to handle failures without significant disruption. This is where RTO and RPO play a vital role.
These metrics help organizations define clear expectations for recovery. Instead of reacting to failures without a plan, teams can follow predefined guidelines that outline how quickly systems should be restored and how much data loss is acceptable. This structured approach reduces uncertainty and enables faster decision-making during critical situations.
Moreover, regulatory requirements and industry standards often demand strict recovery objectives. Organizations handling sensitive data must ensure that their recovery processes meet compliance requirements. Properly defined RTO and RPO values help achieve these goals while maintaining operational efficiency.
Defining Recovery Time Objective (RTO)
Recovery Time Objective represents the maximum amount of time a system, application, or process can remain unavailable after a failure occurs. It essentially answers the question: how quickly must the system be restored to avoid unacceptable consequences? This metric is critical because it determines the urgency of recovery efforts and the resources required to achieve them.
RTO is often measured in seconds, minutes, or hours, depending on the importance of the system. For highly critical applications, the acceptable downtime may be extremely short, requiring near-instant recovery. On the other hand, less critical systems may tolerate longer downtime without causing significant impact.
This objective acts as a target for IT teams during recovery operations. When a failure occurs, the goal is to restore functionality within the defined RTO. Failing to meet this objective can result in financial losses, operational delays, and reduced customer trust. Therefore, organizations invest significant effort in designing systems that can meet their RTO requirements consistently.
It is important to understand that RTO is not just about speed but also about preparedness. Achieving a low RTO requires careful planning, efficient processes, and reliable infrastructure. Without these elements in place, even the most ambitious RTO targets become difficult to achieve.
Factors That Influence RTO Values
Several factors determine how RTO is defined and achieved within an organization. One of the most significant factors is system complexity. Complex systems with multiple dependencies take longer to recover because each component must be restored and synchronized properly. Simpler systems, on the other hand, can often be recovered more quickly.
Resource availability also plays a crucial role. Organizations with dedicated recovery teams, backup infrastructure, and automated processes are better equipped to achieve shorter RTOs. Limited resources can slow down recovery efforts, leading to longer downtime.
Another important factor is business impact. Systems that directly affect revenue generation or customer experience typically require shorter RTOs. For example, an online payment system must be restored quickly to avoid financial losses, whereas an internal reporting tool may tolerate longer downtime.
The level of preparedness within the organization also influences RTO. Well-documented recovery procedures, regular testing, and trained personnel can significantly reduce recovery time. Without these, even minor issues can escalate into prolonged outages.
Strategies for Reducing Recovery Time Objective
Organizations use various strategies to minimize RTO and ensure rapid recovery during failures. One of the most effective approaches is automation. Automated systems can detect failures and initiate recovery processes without human intervention, significantly reducing response time.
Another key strategy is maintaining redundant systems. By having backup components ready to take over, organizations can restore services quickly without waiting for repairs. Redundancy ensures that failures do not result in complete system shutdowns, allowing operations to continue with minimal interruption.
Disaster recovery planning is also essential. A well-defined plan outlines the steps required to restore systems and assigns responsibilities to team members. This reduces confusion during critical situations and ensures that recovery efforts are coordinated and efficient.
Regular testing of recovery processes further enhances RTO performance. Simulations and drills help identify weaknesses in the recovery plan and provide opportunities for improvement. By continuously refining these processes, organizations can achieve faster and more reliable recovery outcomes.
Understanding the Business Impact of Downtime
Downtime can have far-reaching consequences that go beyond immediate operational disruptions. Financial losses are often the most visible impact, especially for businesses that rely on continuous online transactions. Even a short outage can result in missed opportunities and reduced revenue.
Customer trust is another critical factor affected by downtime. Users expect reliable services, and repeated disruptions can lead to dissatisfaction and loss of confidence. In competitive markets, this can drive customers toward alternative solutions.
Operational efficiency also suffers during downtime. Employees may be unable to perform their tasks, leading to delays and reduced productivity. This can create a ripple effect that impacts multiple areas of the organization.
Reputation damage is often a long-term consequence of downtime. Organizations known for frequent outages may struggle to maintain credibility and attract new customers. This highlights the importance of maintaining low RTO values to ensure consistent service availability.
The Relationship Between RTO and System Design
System design plays a crucial role in achieving desired RTO targets. Architectures that prioritize resilience and fault tolerance are better equipped to handle failures without significant downtime. This includes designing systems with modular components that can be isolated and restored independently.
Scalability is another important aspect. Systems that can scale dynamically are more adaptable to changing conditions and can recover more efficiently. This flexibility allows organizations to respond to failures without compromising performance.
Monitoring and alerting systems also contribute to effective RTO management. By detecting issues early, organizations can initiate recovery processes before they escalate into major failures. This proactive approach reduces downtime and improves overall system reliability.
Ultimately, achieving a low RTO requires a combination of thoughtful design, robust infrastructure, and efficient processes. Organizations that invest in these areas are better positioned to maintain high availability and minimize the impact of disruptions.
Introduction to Recovery Point Objective (RPO)
While RTO focuses on downtime, Recovery Point Objective addresses data loss. RPO defines the maximum amount of data that can be lost during a disruption, measured in time. It answers the question: how much recent data can the organization afford to lose?
This metric is particularly important for systems that handle frequent updates or transactions. Losing even a small amount of data can have significant consequences, especially in industries where accuracy and consistency are critical.
RPO is closely tied to backup and replication strategies. Organizations must ensure that data is captured and stored at regular intervals to minimize potential loss. The shorter the RPO, the more frequently data must be backed up or replicated.
Understanding RPO is essential for maintaining data integrity and ensuring that recovery processes restore systems to an acceptable state. Without a clear RPO, organizations risk losing valuable information that may be difficult or impossible to recover.
Why RPO Matters in Data-Driven Environments
In modern organizations, data is one of the most valuable assets. From customer information to transaction records, data drives decision-making and operational efficiency. Losing this data can disrupt processes, compromise accuracy, and lead to significant setbacks.
RPO helps organizations define acceptable levels of data loss and implement strategies to meet those requirements. By setting clear expectations, teams can design backup and replication processes that align with business needs.
Different systems may have different RPO requirements. Critical systems that handle real-time data may require near-zero data loss, while less critical systems may tolerate longer intervals between backups. This flexibility allows organizations to allocate resources effectively while maintaining data protection.
Ultimately, RPO ensures that recovery efforts restore not just functionality but also data integrity. This is essential for maintaining trust, compliance, and operational continuity in data-driven environments.
Key Factors That Influence Recovery Point Objective (RPO)
Recovery Point Objective is shaped by several critical factors that determine how much data an organization can afford to lose during a disruption. One of the most important factors is the frequency of data changes. Systems that process continuous transactions or real-time updates require much shorter RPO values because even a few minutes of data loss could result in serious inconsistencies or financial impact. In contrast, systems with infrequent updates can tolerate longer intervals between backups without significant consequences.
Another major factor is the volume of data being generated and stored. Large-scale environments that handle massive amounts of information must carefully plan how data is captured and protected. High data volumes can make frequent backups more complex and resource-intensive, which directly affects how RPO targets are defined and achieved. Organizations must balance performance and protection to ensure that backup processes do not disrupt normal operations.
Infrastructure capabilities also play a significant role in determining RPO. The availability of high-speed networks, advanced storage systems, and efficient replication technologies allows organizations to reduce the gap between data updates and backups. Environments with limited infrastructure may struggle to achieve shorter RPOs, leading to higher potential data loss during failures.
Business priorities further influence RPO decisions. Data that directly impacts customer experience, financial transactions, or compliance requirements typically demands stricter RPO targets. On the other hand, less critical data can be backed up less frequently without causing major issues. By aligning RPO with business importance, organizations can allocate resources more effectively.
Techniques for Improving Recovery Point Objective
Organizations rely on various techniques to minimize data loss and achieve shorter RPO values. One of the most effective methods is synchronous data replication. This approach ensures that data is written to both primary and backup systems at the same time. As a result, there is virtually no gap between the original data and its backup, significantly reducing the risk of loss. However, this method requires strong infrastructure and can introduce performance overhead due to the need for constant synchronization.
Incremental backups provide another practical solution for improving RPO. Instead of copying all data during each backup cycle, this method captures only the changes made since the last backup. This reduces the time and resources required for backup operations, allowing them to occur more frequently. As a result, organizations can maintain more up-to-date recovery points without overwhelming their systems.
Continuous data replication is also widely used to achieve near real-time data protection. In this approach, changes are continuously transmitted to a secondary system, ensuring that an up-to-date copy of the data is always available. This significantly reduces the amount of data that could be lost during a failure, making it an ideal solution for critical systems.
Another important technique involves snapshot-based backups. Snapshots capture the state of a system at a specific point in time, allowing organizations to quickly restore data to a recent version. While not always real-time, frequent snapshots can still provide a strong balance between performance and data protection.
The Relationship Between RTO and RPO
Although RTO and RPO serve different purposes, they are closely connected and must be considered together when designing recovery strategies. RTO focuses on how quickly systems can be restored, while RPO determines how much data will be available after recovery. A fast recovery process is not sufficient if it restores outdated or incomplete data, just as minimal data loss is not helpful if systems take too long to come back online.
Balancing these two objectives requires careful planning. Organizations must evaluate their operational needs and determine acceptable levels of downtime and data loss. In many cases, achieving extremely low RTO and RPO values requires significant investment in infrastructure, automation, and redundancy. Therefore, decisions must be based on both technical feasibility and business priorities.
The relationship between RTO and RPO also influences system architecture. Environments designed for rapid recovery often incorporate automated failover mechanisms and redundant components. Similarly, systems with strict data protection requirements rely on advanced replication and backup strategies. By aligning these approaches, organizations can create a cohesive recovery framework that addresses both downtime and data loss.
Understanding this relationship helps organizations avoid common pitfalls. For example, focusing solely on reducing downtime without addressing data protection can lead to incomplete recovery. Conversely, prioritizing data integrity without considering recovery speed can result in prolonged outages. A balanced approach ensures that both objectives are met effectively.
Introduction to Redundancy in IT Systems
Redundancy is a fundamental concept in building resilient systems. It involves maintaining duplicate components or resources that can take over in case of failure. By eliminating single points of failure, redundancy ensures that systems can continue operating even when individual components fail.
This concept applies to various aspects of an IT environment, including hardware, networks, and applications. For example, having multiple servers allows workloads to be distributed and ensures that if one server fails, others can handle the load. Similarly, redundant network paths enable data to flow through alternative routes if the primary path becomes unavailable.
Redundancy is not just about duplication but also about strategic placement and management of resources. Simply having extra components is not enough; they must be properly configured and maintained to ensure seamless transition during failures. This requires careful planning and ongoing monitoring to ensure that backup systems are always ready to perform when needed.
By implementing redundancy effectively, organizations can significantly reduce both RTO and RPO. Systems can recover faster because backup components are already in place, and data loss can be minimized through continuous synchronization between primary and secondary resources.
High Availability and Its Role in Recovery Objectives
High availability refers to the ability of a system to remain operational for extended periods with minimal downtime. It is achieved by combining redundancy, automation, and intelligent system design to ensure continuous service delivery. High availability environments are specifically designed to handle failures without interrupting user access.
In such environments, failover mechanisms play a crucial role. When a component fails, another component automatically takes over its responsibilities without requiring manual intervention. This seamless transition reduces downtime and helps meet strict RTO targets.
Load balancing is another important aspect of high availability. By distributing workloads across multiple resources, organizations can prevent overload and ensure consistent performance. This not only improves system reliability but also enhances the ability to recover quickly from failures.
High availability also supports RPO objectives by enabling real-time or near real-time data synchronization. When data is continuously replicated across multiple systems, the risk of data loss is significantly reduced. This ensures that recovery processes can restore systems to a recent and consistent state.
However, achieving high availability requires careful planning and investment. Organizations must evaluate their needs and determine the appropriate level of redundancy and automation required to meet their objectives. While the benefits are substantial, the costs associated with high availability can be significant, making it essential to strike the right balance.
Eliminating Single Points of Failure
A single point of failure is any component whose failure can bring down an entire system. Identifying and eliminating these weak points is essential for achieving reliable recovery objectives. Without addressing these vulnerabilities, even the most advanced recovery strategies may fail to deliver the desired results.
Eliminating single points of failure involves analyzing system architecture and identifying components that lack redundancy. This could include servers, network devices, power supplies, or even software services. Once identified, these components must be reinforced with backup solutions that can take over in case of failure.
For example, using multiple power sources ensures that systems remain operational even if one source fails. Similarly, deploying applications across multiple servers prevents a single server failure from disrupting services. Network redundancy ensures that data can continue to flow even if one path becomes unavailable.
This approach not only improves system reliability but also enhances recovery capabilities. When failures occur, systems with no single points of failure can continue operating with minimal disruption, reducing both downtime and data loss.
The Role of Failover Mechanisms in Recovery
Failover mechanisms are essential for maintaining continuity during system failures. These mechanisms automatically transfer workloads from a failed component to a backup component, ensuring that services remain available. The effectiveness of failover directly impacts RTO, as faster transitions result in shorter downtime.
There are different types of failover mechanisms, including active-active and active-passive configurations. In active-active setups, multiple components operate simultaneously, sharing the workload. If one component fails, the others continue handling the load without interruption. In active-passive configurations, backup components remain on standby and take over only when the primary component fails.
Automation is a key factor in successful failover. Manual intervention can introduce delays and increase the risk of errors, whereas automated systems can detect failures and initiate failover instantly. This ensures a smooth transition and minimizes the impact on users.
Failover mechanisms also contribute to RPO by ensuring that data remains consistent across systems. When combined with real-time replication, failover can provide seamless recovery with minimal data loss. This makes it an essential component of modern disaster recovery strategies.
Balancing Cost and Performance in Recovery Planning
Achieving optimal RTO and RPO values often requires significant investment in infrastructure, tools, and expertise. Organizations must carefully evaluate the cost of implementing advanced recovery solutions against the potential impact of downtime and data loss.
High-performance systems with near-zero downtime and minimal data loss typically involve expensive technologies such as real-time replication, redundant data centers, and automated failover systems. While these solutions provide excellent reliability, they may not be necessary for all applications.
Cost-effective strategies involve prioritizing critical systems and allocating resources accordingly. By identifying which systems require strict recovery objectives and which can tolerate more flexibility, organizations can optimize their investments. This ensures that resources are used efficiently without compromising overall resilience.
Performance considerations also play a role in recovery planning. Some recovery techniques may introduce overhead that affects system performance. Organizations must ensure that their solutions strike a balance between maintaining performance during normal operations and achieving rapid recovery during failures.
Building an Effective Disaster Recovery Strategy
A well-structured disaster recovery strategy is essential for achieving reliable Recovery Time Objective and Recovery Point Objective targets. It provides a clear roadmap for how systems, applications, and data will be restored after a disruption. Without a defined strategy, recovery efforts can become disorganized, leading to delays, confusion, and increased impact on business operations.
An effective disaster recovery strategy begins with identifying critical systems and understanding their role within the organization. Not all systems require the same level of protection, so prioritization is key. By focusing on the most important services, organizations can allocate resources efficiently and ensure that essential operations are restored first.
Another important aspect is defining recovery procedures in detail. These procedures should outline step-by-step actions for restoring systems, including roles and responsibilities for each team member. Clear documentation reduces uncertainty during high-pressure situations and ensures that recovery efforts are executed consistently.
Communication planning is also a critical component. During a disruption, teams must coordinate effectively to resolve issues quickly. Having predefined communication channels and escalation paths helps streamline decision-making and reduces response time.
Testing and validation further strengthen disaster recovery strategies. Regular drills and simulations allow organizations to evaluate their preparedness and identify areas for improvement. By continuously refining these strategies, businesses can enhance their ability to meet RTO and RPO targets under real-world conditions.
The Importance of Backup Strategies in Data Protection
Backup strategies form the foundation of any effort to meet Recovery Point Objective requirements. They ensure that data is preserved and can be restored to a usable state after a failure. Without reliable backups, organizations risk losing valuable information that may be impossible to recover.
There are several types of backup strategies, each with its own advantages. Full backups capture all data at a specific point in time, providing a complete snapshot for recovery. While comprehensive, they can be resource-intensive and may not be suitable for frequent execution.
Incremental backups, on the other hand, focus on capturing only the changes made since the last backup. This approach reduces storage requirements and allows for more frequent backups, helping to minimize data loss. Differential backups offer a balance by capturing changes since the last full backup, providing faster recovery while maintaining efficiency.
The frequency of backups directly impacts RPO. More frequent backups result in shorter intervals between recovery points, reducing potential data loss. However, increasing backup frequency also requires additional resources, making it important to find the right balance.
Storage location is another critical consideration. Keeping backups in multiple locations, including offsite or cloud-based storage, ensures that data remains accessible even if the primary site is compromised. This adds an extra layer of protection and enhances overall resilience.
Data Replication and Its Role in Continuous Protection
Data replication is a powerful technique for maintaining up-to-date copies of information across different systems or locations. Unlike traditional backups, which capture data at specific intervals, replication continuously or near-continuously updates secondary systems with changes from the primary system. This significantly reduces the gap between data creation and data protection.
There are different types of replication methods, each suited to specific needs. Synchronous replication ensures that data is written to both primary and secondary systems simultaneously. This approach provides the highest level of data consistency and minimizes RPO, but it requires high-performance infrastructure and can introduce latency.
Asynchronous replication offers greater flexibility by allowing data to be transferred with a slight delay. While this may result in minimal data loss, it reduces the performance impact on primary systems and is more suitable for long-distance replication scenarios.
Replication also supports geographic redundancy by maintaining copies of data in multiple locations. This is particularly important for protecting against large-scale disruptions such as natural disasters or regional outages. By distributing data across different locations, organizations can ensure continuity even in extreme situations.
Combining replication with backup strategies creates a comprehensive data protection framework. While replication provides real-time or near real-time protection, backups offer additional recovery points and safeguard against issues such as data corruption or accidental deletion.
Automation in Disaster Recovery Processes
Automation plays a critical role in improving both RTO and RPO by reducing the need for manual intervention during recovery. Automated systems can detect failures, initiate recovery processes, and restore services with minimal delay. This not only speeds up recovery but also reduces the risk of human error.
One of the key benefits of automation is consistency. Manual processes can vary depending on the situation and the individuals involved, whereas automated workflows follow predefined steps every time. This ensures that recovery procedures are executed accurately and efficiently.
Automation also enhances scalability. As organizations grow and their systems become more complex, manual recovery processes become increasingly difficult to manage. Automated solutions can handle large-scale environments more effectively, ensuring that recovery objectives are met even as infrastructure expands.
Monitoring and alerting systems are often integrated with automation to provide real-time insights into system health. When an issue is detected, automated responses can be triggered immediately, reducing downtime and preventing further damage.
Despite its advantages, automation must be carefully designed and tested. Poorly implemented automation can lead to unintended consequences, such as triggering unnecessary failovers or failing to address the root cause of an issue. Regular testing and refinement are essential to ensure reliability.
Testing and Validation of Recovery Plans
Testing is a crucial step in ensuring that disaster recovery plans are effective and reliable. Without regular testing, organizations cannot be confident that their recovery strategies will work as intended during an actual disruption. Testing helps identify weaknesses, validate assumptions, and improve overall preparedness.
There are different types of testing methods that organizations can use. Tabletop exercises involve discussing hypothetical scenarios and evaluating how teams would respond. These exercises help improve communication and decision-making without affecting live systems.
Simulation testing takes a more practical approach by creating controlled environments where recovery procedures can be executed. This allows teams to evaluate the effectiveness of their strategies and identify technical issues that may not be apparent during discussions.
Full-scale testing involves executing recovery plans in real or near-real conditions. While more complex and resource-intensive, this method provides the most accurate assessment of recovery capabilities. It helps organizations understand how their systems and teams perform under pressure.
Testing should be conducted regularly and updated as systems and requirements evolve. Each test provides valuable insights that can be used to refine recovery plans and improve performance. By maintaining a cycle of continuous improvement, organizations can ensure that they remain prepared for unexpected disruptions.
Monitoring and Performance Analysis for Continuous Improvement
Monitoring is essential for maintaining system reliability and ensuring that recovery objectives are met. By continuously tracking system performance, organizations can detect issues early and take proactive measures to prevent failures. This reduces the likelihood of disruptions and improves overall resilience.
Performance metrics provide valuable insights into how systems behave under different conditions. These metrics can include response times, error rates, and resource utilization. Analyzing this data helps organizations identify trends and potential bottlenecks that could impact recovery efforts.
Monitoring also supports incident response by providing real-time information during disruptions. This allows teams to assess the situation quickly and make informed decisions about recovery actions. Faster response times contribute directly to achieving RTO targets.
In addition to real-time monitoring, historical analysis plays a key role in continuous improvement. By reviewing past incidents and recovery efforts, organizations can identify patterns and areas for enhancement. This information can be used to refine recovery strategies and optimize system design.
Integrating monitoring with automation further enhances its effectiveness. Automated systems can use monitoring data to trigger recovery actions, ensuring that issues are addressed तुरंत without delay. This combination of visibility and responsiveness is essential for maintaining high availability.
The Role of Documentation in Recovery Preparedness
Documentation is often overlooked, but it is a critical component of successful disaster recovery. Clear and comprehensive documentation ensures that recovery procedures are well understood and can be executed efficiently during a disruption.
Good documentation includes detailed instructions for restoring systems, configuring infrastructure, and accessing backup data. It should also outline roles and responsibilities, ensuring that each team member knows what is expected of them during recovery operations.
Keeping documentation up to date is equally important. As systems evolve, recovery procedures must be revised to reflect changes in architecture, tools, and processes. Outdated documentation can lead to confusion and delays, undermining recovery efforts.
Accessibility is another key factor. Documentation should be stored in a way that allows teams to access it بسهولة even during outages. This may involve maintaining offline copies or using secure cloud-based platforms that remain available during disruptions.
By prioritizing documentation, organizations can improve coordination, reduce errors, and enhance their ability to meet RTO and RPO targets. It serves as a reliable reference point that guides recovery efforts and ensures consistency across different scenarios.
Aligning Recovery Objectives with Business Continuity Goals
Recovery objectives must be closely aligned with broader business continuity goals to ensure that organizations can maintain operations during disruptions. This alignment requires collaboration between technical teams and business stakeholders to define priorities and expectations.
Business continuity planning focuses on maintaining essential functions during and after a disruption. RTO and RPO play a central role in this process by defining acceptable levels of downtime and data loss. By integrating these metrics into continuity plans, organizations can ensure that recovery efforts support overall business objectives.
Risk assessment is a key step in this alignment process. Organizations must identify potential threats and evaluate their impact on operations. This helps determine appropriate RTO and RPO values for different systems and ensures that resources are allocated effectively.
Regular review and adjustment are necessary to maintain alignment. As business needs change, recovery objectives must be updated to reflect new priorities and challenges. This ensures that recovery strategies remain relevant and effective over time.
Strong alignment between recovery objectives and business continuity goals enables organizations to respond to disruptions with confidence. It ensures that recovery efforts are focused on what matters most, minimizing impact and supporting long-term success.
Advanced Strategies for Optimizing RTO and RPO
Achieving highly optimized Recovery Time Objective and Recovery Point Objective targets requires moving beyond basic recovery methods and adopting advanced strategies. Organizations that operate critical systems often implement multi-layered approaches that combine redundancy, automation, intelligent monitoring, and distributed architectures. These strategies are designed to minimize both downtime and data loss while maintaining system performance and reliability.
One advanced approach involves the use of geographically distributed environments. By hosting systems and data across multiple locations, organizations can ensure that a failure in one region does not disrupt overall operations. This approach significantly reduces recovery time because traffic can be redirected to unaffected locations almost instantly. It also improves data protection by maintaining copies of information in separate regions.
Another strategy focuses on microservices architecture. Instead of relying on a single monolithic system, applications are divided into smaller, independent components. When a failure occurs, only the affected component needs to be restored rather than the entire system. This reduces recovery time and limits the impact of failures. Additionally, microservices can be scaled and updated independently, improving overall resilience.
Containerization and orchestration technologies further enhance recovery capabilities. Containers allow applications to run consistently across different environments, making it easier to deploy and restore services quickly. Orchestration tools automate the management of these containers, ensuring that failed components are restarted or replaced automatically. This level of automation directly contributes to achieving lower RTO values.
Cloud-Based Disaster Recovery Solutions
Cloud computing has transformed the way organizations approach disaster recovery. Cloud-based solutions provide flexible and scalable resources that can be used to restore systems بسرعة without the need for extensive on-premises infrastructure. This makes it easier for organizations to achieve both low RTO and low RPO targets.
One of the key advantages of cloud-based recovery is on-demand scalability. During a disruption, organizations can quickly allocate additional resources to handle increased workloads. This ensures that systems can be restored and stabilized without delays.
Cloud environments also support automated backups and replication, allowing data to be continuously protected. These features reduce the risk of data loss and enable faster recovery. Additionally, cloud providers often offer built-in tools for monitoring, failover, and recovery management, simplifying the overall process.
Another important benefit is cost efficiency. Instead of maintaining expensive backup infrastructure that may rarely be used, organizations can rely on cloud services that operate on a pay-as-you-go model. This allows them to optimize costs while still maintaining strong recovery capabilities.
However, cloud-based recovery requires careful planning. Organizations must ensure that their data is securely stored and that recovery processes are properly configured. Network connectivity and latency must also be considered, as they can impact recovery performance.
Hybrid Approaches to Disaster Recovery
Many organizations adopt hybrid disaster recovery strategies that combine on-premises and cloud-based solutions. This approach provides the best of both worlds by leveraging the control and performance of on-premises systems alongside the scalability and flexibility of the cloud.
In a hybrid model, critical systems may be maintained on-premises with real-time replication to the cloud. In the event of a failure, workloads can be shifted to the cloud environment, ensuring continuity. This reduces downtime and provides an additional layer of protection against large-scale disruptions.
Hybrid strategies also allow organizations to tailor their recovery solutions based on specific needs. For example, highly sensitive data may be stored locally for security reasons, while less critical data can be backed up in the cloud. This flexibility enables organizations to balance performance, security, and cost effectively.
Implementing a hybrid approach requires careful integration between different environments. Systems must be compatible, and data synchronization must be reliable. Proper configuration and testing are essential to ensure that recovery processes work seamlessly across both environments.
Security Considerations in Recovery Planning
Security is a critical aspect of disaster recovery that cannot be overlooked. During a disruption, systems may be more vulnerable to attacks, making it essential to implement strong security measures. Protecting data and ensuring secure recovery processes are key to maintaining trust and compliance.
One important consideration is data encryption. Both stored data and data in transit should be encrypted to prevent unauthorized access. This ensures that sensitive information remains protected even if it is intercepted or accessed during recovery operations.
Access control is another crucial factor. Only authorized personnel should have access to recovery systems and data. Implementing strict authentication and authorization mechanisms helps prevent misuse and ensures accountability.
Regular security assessments and audits are also necessary. These evaluations help identify vulnerabilities and ensure that recovery processes meet security standards. By addressing potential risks proactively, organizations can strengthen their overall resilience.
Integrating security into recovery planning ensures that systems are not only restored quickly but also protected against potential threats. This holistic approach enhances both reliability and trustworthiness.
Common Challenges in Achieving RTO and RPO Targets
Despite careful planning, organizations often face challenges when trying to meet their recovery objectives. One common issue is the complexity of modern IT environments. As systems become more interconnected, recovering them quickly and accurately becomes more difficult. Dependencies between components can slow down recovery efforts and increase the risk of errors.
Resource limitations can also pose significant challenges. Achieving low RTO and RPO values often requires substantial investment in infrastructure, tools, and skilled personnel. Organizations with limited budgets may struggle to implement advanced recovery solutions, leading to compromises in performance.
Another challenge is the lack of regular testing. Without testing, recovery plans may contain hidden flaws that only become apparent during an actual disruption. This can result in delays and unexpected complications.
Data consistency is another concern. Ensuring that data remains accurate and synchronized across systems during recovery can be complex, especially in distributed environments. Inconsistencies can lead to operational issues and require additional effort to resolve.
Addressing these challenges requires a proactive approach that includes continuous improvement, investment in technology, and a strong focus on training and preparedness.
The Role of Training and Team Preparedness
Human factors play a significant role in disaster recovery success. Even the most advanced systems require skilled personnel to manage and oversee recovery processes. Proper training ensures that teams are prepared to respond effectively during disruptions.
Training programs should cover both technical and procedural aspects of recovery. Team members must understand how to use recovery tools, execute procedures, and communicate effectively during incidents. Regular drills and simulations help reinforce these skills and build confidence.
Collaboration is also essential. Recovery efforts often involve multiple teams working together, including IT, security, and business units. Clear communication and coordination ensure that recovery processes are executed smoothly and efficiently.
Preparedness extends beyond technical skills. Teams must also be able to handle the pressure and uncertainty that come with disruptions. Strong leadership and well-defined roles help maintain focus and ensure that recovery efforts remain on track.
By investing in training and preparedness, organizations can improve their ability to meet RTO and RPO targets and respond to disruptions with confidence.
Continuous Improvement and Future Trends in Disaster Recovery
Disaster recovery is not a one-time effort but an ongoing process that evolves with technology and business needs. Continuous improvement is essential for maintaining effective recovery strategies and adapting to new challenges.
Organizations should regularly review their recovery objectives and update them based on changes in operations, technology, and risk landscape. This ensures that RTO and RPO values remain relevant and achievable.
Emerging technologies are also shaping the future of disaster recovery. Artificial intelligence and machine learning are being used to predict failures, optimize recovery processes, and automate decision-making. These technologies have the potential to further reduce downtime and data loss.
Edge computing is another trend that influences recovery strategies. By processing data closer to its source, organizations can reduce latency and improve resilience. This approach requires new methods for data protection and recovery but offers significant benefits in terms of performance and reliability.
As technology continues to evolve, organizations must stay informed and adapt their strategies accordingly. Embracing innovation while maintaining strong fundamentals ensures that recovery processes remain effective and efficient.
Final Thoughts
Recovery Time Objective and Recovery Point Objective are fundamental to ensuring business continuity in a technology-driven world. They provide clear benchmarks for how quickly systems must be restored and how much data loss is acceptable, guiding organizations in designing effective recovery strategies.
By combining strong planning, advanced technologies, and continuous improvement, organizations can achieve reliable recovery outcomes. Redundancy, automation, and high availability play key roles in minimizing downtime and protecting data, while training and preparedness ensure that teams can respond effectively during disruptions.
Balancing cost, performance, and risk is essential when defining recovery objectives. Not all systems require the same level of protection, and organizations must prioritize resources based on business impact. This strategic approach allows them to maintain resilience without unnecessary expense.
Ultimately, success in disaster recovery depends on a comprehensive and well-executed strategy that integrates RTO and RPO into every aspect of system design and operation. By focusing on these principles, organizations can navigate disruptions with confidence and maintain the reliability that users expect.