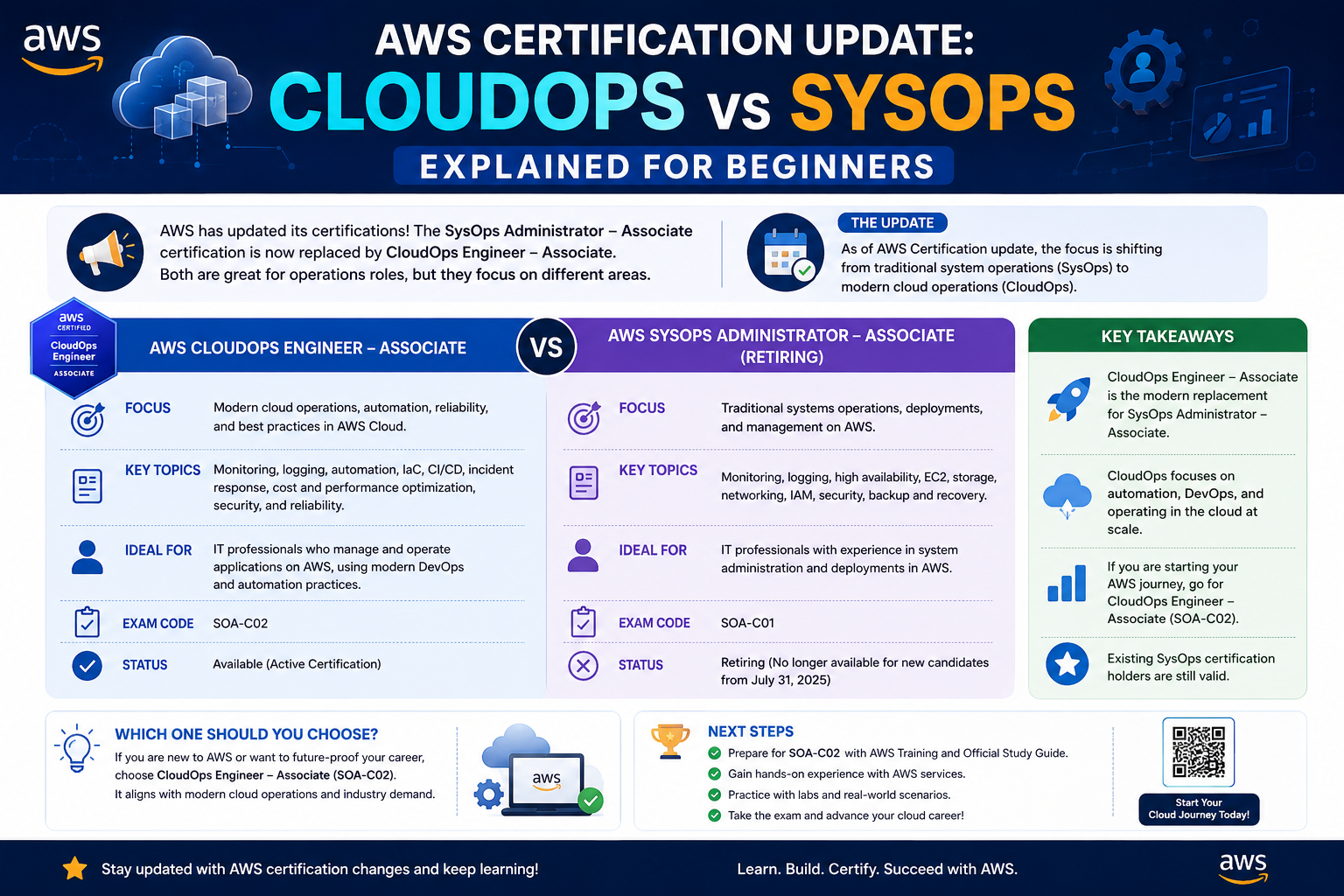
The world of cloud computing has changed dramatically over the past decade, and one of the clearest signs of this transformation is the evolution of AWS certification paths. The transition from the traditional SysOps Administrator role to the newer CloudOps Engineer role reflects how deeply cloud technology has reshaped IT operations.
SysOps, short for Systems Operations, was originally designed for professionals who managed traditional IT infrastructure. This included server maintenance, system monitoring, patching, backups, and ensuring uptime in environments that were often physically hosted or only partially cloud-integrated. At the time, this was the backbone of enterprise IT operations.
However, as organizations rapidly moved to cloud environments, the nature of operations changed. Infrastructure became virtual, scalable, and heavily automated. The responsibilities of IT professionals have also expanded beyond maintenance into automation, orchestration, security enforcement, cost optimization, and continuous delivery management.
The CloudOps concept emerged as a reflection of this new reality. It is not just a renamed certification but a representation of how operational work is now structured in cloud-first environments. Instead of manually managing systems, professionals now design, automate, and continuously improve cloud infrastructure.
This shift is not just technical—it is strategic. It signals that companies expect IT teams to think beyond system stability and focus on agility, efficiency, and scalability. CloudOps represents this modern mindset.
Understanding the Evolution of SysOps in the Cloud Era
SysOps originated in an era where IT systems were primarily physical or on-premises. The role focused heavily on maintaining servers, ensuring uptime, managing storage, and troubleshooting hardware or software issues. System administrators were often reactive, responding to incidents as they occurred.
When cloud computing began to gain traction, SysOps roles gradually migrated into cloud environments. AWS SysOps Administrator certification became a bridge between traditional IT operations and cloud-based administration. It introduced professionals to monitoring tools, basic automation, and cloud resource management.
However, even as SysOps evolved, its foundation remained tied to operational maintenance. It still reflected a mindset where systems were managed rather than engineered for continuous change. This became increasingly limiting in modern cloud environments.
Today, systems are dynamic rather than static. Infrastructure is frequently deployed, updated, scaled, and destroyed automatically. Manual intervention is no longer efficient or scalable. This is where SysOps begins to feel outdated in concept, even if many of its principles remain relevant.
The evolution of SysOps into CloudOps is essentially a shift from system maintenance to system engineering. Instead of simply keeping systems running, professionals are now expected to design systems that manage themselves through automation, observability, and intelligent scaling.
Why AWS Introduced CloudOps as the New Standard
The introduction of CloudOps reflects a broader industry transformation rather than just a certification update. AWS recognized that the traditional SysOps model no longer fully represents the skills required in modern cloud environments.
CloudOps emphasizes a proactive and automated approach to operations. Rather than reacting to system failures, professionals are expected to anticipate issues, design resilient architectures, and use automation to reduce human intervention.
One of the main reasons for this shift is the widespread adoption of Infrastructure as Code (IaC). Instead of manually configuring servers, professionals now define infrastructure using code-based templates. This allows systems to be deployed consistently, quickly, and at scale.
Another major factor is observability. In modern cloud systems, monitoring is not just about uptime—it is about understanding system behavior, detecting anomalies early, and making data-driven decisions. CloudOps places significant emphasis on telemetry, logs, metrics, and distributed tracing.
Security also plays a more integrated role in CloudOps. Instead of being a separate function, security is embedded into every layer of infrastructure and operations. This includes identity management, automated compliance checks, and continuous security validation.
AWS introduced CloudOps to align certification paths with these realities. It ensures that professionals are evaluated on skills that directly match modern job expectations rather than legacy operational models.
The Changing Nature of IT Operations in Cloud Environments
In traditional IT environments, operations were largely linear. A system would be built, deployed, and maintained over a long lifecycle. Changes were infrequent, and scaling required significant planning and manual effort.
Cloud computing has completely disrupted this model. Infrastructure is now ephemeral, meaning resources can be created and destroyed in seconds. Applications are deployed continuously, and systems are designed to scale automatically based on demand.
This change has fundamentally altered the role of IT operations professionals. Instead of managing fixed systems, they now manage dynamic environments where change is constant.
Automation has become the foundation of this new operational model. Once manual tasks—such as provisioning servers, applying updates, or configuring networks—are now handled by automated systems.
Another major shift is the rise of DevOps and DevSecOps practices, where development, operations, and security teams collaborate closely. This integration has blurred traditional role boundaries and increased the need for cross-functional expertise.
In this environment, CloudOps emerges as the operational backbone. It supports continuous deployment pipelines, automated scaling systems, and real-time monitoring frameworks. It ensures that cloud environments remain stable even as they evolve rapidly.
Key Differences Between SysOps and CloudOps Mindsets
One of the most important aspects of this transition is the difference in mindset between SysOps and CloudOps.
SysOps is traditionally reactive. It focuses on responding to system issues, performing maintenance tasks, and ensuring that infrastructure remains functional. The emphasis is on stability and control.
CloudOps, on the other hand, is proactive and design-oriented. It focuses on building systems that can manage themselves. Instead of reacting to problems, CloudOps professionals aim to prevent them through automation and intelligent design.
In SysOps, success is often measured by uptime and system availability. In CloudOps, success is measured by efficiency, scalability, resilience, and automation maturity.
Another key difference lies in tool usage. SysOps often relies on manual interfaces and administrative tasks, while CloudOps relies heavily on APIs, scripting, automation frameworks, and cloud-native services.
CloudOps also places a stronger emphasis on data. Metrics, logs, and traces are not just diagnostic tools—they are essential inputs for decision-making and system optimization.
Overall, the shift represents a move from system administration to system engineering. It requires a broader skill set and a more strategic approach to infrastructure management.
How Automation Became the Core of Cloud Operations
Automation is one of the most defining features of CloudOps. It fundamentally changes how infrastructure is managed and operated.
In traditional SysOps environments, automation was limited and often optional. Many tasks were still performed manually, especially in smaller environments. However, as cloud systems grew in scale and complexity, manual operations became unsustainable.
CloudOps embraces automation as a core principle rather than an enhancement. Everything from infrastructure provisioning to monitoring, scaling, and recovery is designed to be automated.
Infrastructure as Code plays a central role in this transformation. It allows entire environments to be defined in templates and deployed consistently across multiple regions or accounts.
Automation also extends to operational tasks such as patch management, backups, and performance tuning. These processes are executed through scripts or managed services, reducing human error and increasing efficiency.
Another important aspect is event-driven automation. Systems can respond automatically to specific conditions, such as increased traffic or resource failure, without human intervention.
This level of automation not only improves efficiency but also enables systems to operate at a scale that would be impossible to manage manually.
Security and Governance in the CloudOps Era
Security has become deeply integrated into CloudOps practices. Unlike traditional models, where security was handled separately, modern cloud environments require security to be embedded into every layer of the system.
Identity and access management play a crucial role in controlling who can access resources and under what conditions. Permissions are often defined as code and managed alongside infrastructure configurations.
Governance is equally important. Organizations must ensure that cloud resources comply with internal policies and external regulations. This is achieved through automated compliance checks and policy enforcement tools.
CloudOps also emphasizes continuous security monitoring. Instead of periodic audits, systems are constantly evaluated for vulnerabilities, misconfigurations, and suspicious activity.
Encryption, network segmentation, and secure deployment pipelines are standard practices in CloudOps environments. These measures ensure that security is not an afterthought but an ongoing process.
The integration of security into operational workflows is one of the key reasons CloudOps is becoming the dominant model in cloud environments.
The Role of Monitoring and Observability in CloudOps
Monitoring has evolved significantly in cloud environments. In traditional SysOps, monitoring was primarily focused on system health metrics such as CPU usage, memory consumption, and uptime.
CloudOps expands this concept into observability, which provides a deeper understanding of system behavior. Observability includes logs, metrics, and traces that allow professionals to understand not just what is happening, but why it is happening.
Modern cloud systems generate massive amounts of data. CloudOps professionals must be able to interpret this data to identify patterns, detect anomalies, and optimize performance.
Real-time monitoring is essential in cloud environments where systems can scale or fail rapidly. Automated alerts and intelligent dashboards help teams respond quickly to potential issues.
Observability also supports continuous improvement. By analyzing system behavior over time, teams can identify inefficiencies and optimize infrastructure performance.
This data-driven approach is a key component of CloudOps and represents a significant advancement over traditional monitoring practices.
Preparing for the Operational Future of Cloud Systems
The shift from SysOps to CloudOps is not just a certification change—it reflects the future direction of IT operations. As cloud environments continue to evolve, the demand for professionals who understand automation, scalability, and cloud-native design will continue to grow.
Organizations are no longer looking for system administrators who simply maintain infrastructure. They need professionals who can design resilient systems, automate operations, and optimize performance at scale.
This means that IT professionals must continuously evolve their skill sets. Understanding automation tools, cloud architecture principles, and observability practices is becoming essential.
CloudOps represents this new standard. It is not just about managing systems—it is about engineering intelligent, self-operating environments that can adapt to changing demands.
The transformation is ongoing, and its impact will continue to shape the future of cloud computing and IT operations.
The New Shape of AWS Cloud Operations: What CloudOps Changes in Practice
The transition from SysOps to CloudOps is not only a change in certification naming—it reflects a deeper restructuring of how cloud operations are expected to function in real-world environments. In practice, CloudOps shifts the focus from maintaining systems to engineering operational intelligence into every layer of infrastructure.
This means that operational teams are no longer just responsible for ensuring systems run correctly. Instead, they are expected to design environments that are self-healing, self-scaling, and continuously optimized without constant manual intervention.
In modern cloud architecture, this approach is essential. Applications are no longer deployed as single, stable units. They are distributed across multiple services, regions, and availability zones. Each component must be monitored, managed, and optimized independently while still functioning as part of a larger system.
CloudOps introduces a mindset where operations are treated as part of the development lifecycle rather than a separate function. Infrastructure decisions are made early in the design process, and operational requirements are built into system architecture from the beginning.
This shift has significant implications for how IT professionals approach their work. It requires a broader understanding of cloud services, system design patterns, automation frameworks, and performance engineering.
How CloudOps Redefines Daily Responsibilities in Cloud Engineering
In traditional SysOps roles, daily responsibilities often involved reactive tasks such as troubleshooting system failures, applying patches, checking logs, and ensuring uptime. While these tasks still exist in cloud environments, they now represent only a small portion of the overall workload.
CloudOps professionals spend more time designing automated workflows than manually executing tasks. For example, instead of manually deploying servers, they define infrastructure templates that automatically provision resources when needed.
Another major shift is the emphasis on proactive system optimization. Rather than waiting for performance issues to occur, CloudOps engineers analyze system metrics continuously and adjust configurations to improve efficiency before problems arise.
Incident response also looks different in CloudOps environments. When issues occur, automated systems often detect and respond to them before human intervention is required. Engineers then focus on root cause analysis and long-term improvements rather than immediate fixes.
In addition, CloudOps professionals are heavily involved in cost optimization. Cloud environments can scale quickly, which also means costs can escalate rapidly if not managed properly. Engineers must continuously evaluate resource usage and implement strategies to reduce waste.
This includes rightsizing compute resources, optimizing storage usage, and using automation to shut down unused environments. Cost awareness has become a core operational responsibility rather than a finance-only concern.
The Growing Importance of Infrastructure as Code in CloudOps
Infrastructure as Code (IaC) is one of the most critical pillars of CloudOps. It fundamentally changes how infrastructure is created, managed, and maintained.
Instead of manually configuring servers or networking components, engineers define infrastructure using declarative templates. These templates describe the desired state of the system, and automation tools ensure that the actual infrastructure matches that state.
This approach provides several key advantages. It ensures consistency across environments, reduces human error, and allows infrastructure to be version-controlled just like application code.
In CloudOps environments, IaC is not optional—it is a standard practice. Every environment, from development to production, is typically defined using code-based templates.
This also enables faster recovery and replication. If an environment fails or needs to be recreated, it can be rebuilt quickly using the same infrastructure definitions.
Another important aspect is collaboration. Developers and operations teams can work from the same infrastructure definitions, reducing misunderstandings and improving alignment between teams.
As cloud environments become more complex, IaC serves as the foundation for scalable and reliable operations.
Automation-First Thinking in Modern Cloud Operations
One of the defining characteristics of CloudOps is automation-first thinking. This means that any repetitive or predictable task is evaluated for automation before being performed manually.
This mindset extends across all areas of cloud operations. Deployment pipelines, system monitoring, scaling decisions, and even security enforcement are designed to operate automatically whenever possible.
For example, instead of manually scaling servers during high traffic periods, CloudOps systems use automated scaling policies that adjust resources based on real-time demand.
Similarly, backup processes are automated to ensure consistency and reliability. Systems regularly create snapshots or backups without requiring human intervention.
Patch management is another area where automation plays a key role. Instead of manually updating systems, automated workflows ensure that updates are applied consistently across all environments.
This automation-first approach not only improves efficiency but also reduces operational risk. Human error is one of the leading causes of system outages, and automation significantly minimizes this risk.
Over time, organizations that fully embrace automation achieve higher system reliability and faster deployment cycles compared to those relying on manual operations.
Observability as a Core Skill in CloudOps Engineering
As cloud systems become more distributed, observability becomes increasingly important. Unlike traditional monitoring, which focuses on predefined metrics, observability provides a more comprehensive view of system behavior.
In CloudOps environments, observability is built on three primary components: metrics, logs, and traces. Together, these data sources provide a detailed understanding of how systems behave under different conditions.
Metrics provide quantitative data such as CPU usage, memory consumption, and request latency. Logs capture detailed event information, including errors and system events. Traces follow requests as they move through distributed systems.
By combining these data sources, engineers can diagnose complex issues that would be difficult to identify using traditional monitoring tools.
For example, if an application is experiencing slow performance, observability tools can help identify whether the issue is related to database latency, network delays, or application logic.
This level of visibility is essential in modern cloud environments where systems are highly distributed and interdependent.
CloudOps professionals are expected to not only use observability tools but also design systems that generate meaningful telemetry data from the beginning.
Cloud Governance and Policy-Driven Infrastructure Management
As cloud environments scale, governance becomes a critical concern. Organizations must ensure that resources are used appropriately, securely, and in compliance with internal and external regulations.
CloudOps introduces a policy-driven approach to governance. Instead of manually enforcing rules, policies are defined and applied automatically across cloud environments.
These policies can control a wide range of behaviors, including resource creation, access permissions, and configuration standards.
For example, organizations may enforce rules that prevent the creation of unsecured storage resources or restrict access to sensitive systems based on identity roles.
Governance also includes tracking resource usage to ensure compliance with budget constraints and operational guidelines.
This automated governance model allows organizations to maintain control over complex cloud environments without slowing down development or deployment processes.
It also reduces the risk of configuration drift, where systems gradually deviate from their intended state over time.
In CloudOps, governance is not a separate function but an integrated part of infrastructure design and management.
Cost Optimization as a Continuous Operational Responsibility
One of the most significant differences between traditional SysOps and CloudOps is the role of cost management. In cloud environments, costs are dynamic and directly tied to resource usage.
This means that inefficient configurations or unused resources can quickly lead to unnecessary expenses. As a result, cost optimization becomes a continuous responsibility rather than a periodic task.
CloudOps professionals actively monitor resource usage and implement strategies to optimize costs. This includes identifying underutilized resources, optimizing storage tiers, and selecting appropriate compute configurations.
Automation plays a key role in cost optimization. Systems can automatically shut down unused environments, scale resources based on demand, and adjust configurations to improve efficiency.
Another important aspect is forecasting. Engineers analyze usage patterns to predict future resource needs and prevent over-provisioning.
Cost optimization also involves architectural decisions. Choosing the right services and designing systems efficiently can have a significant impact on long-term operational costs.
In CloudOps environments, cost awareness is integrated into every stage of system design and operation.
Incident Management in Highly Automated Cloud Systems
Incident management in CloudOps environments is significantly different from traditional approaches. In highly automated systems, many incidents are detected and resolved automatically before they escalate.
This is possible because modern cloud systems are designed with self-healing capabilities. When a component fails, automated systems can restart services, replace instances, or reroute traffic without human intervention.
However, not all incidents can be resolved automatically. In such cases, CloudOps professionals focus on rapid diagnosis and root cause analysis.
The emphasis is not only on fixing the immediate issue but also on understanding why it occurred and preventing it from happening again.
Incident management in CloudOps is closely tied to observability. Without detailed system insights, diagnosing distributed system issues would be extremely difficult.
Another important aspect is post-incident improvement. Every incident is treated as an opportunity to improve system resilience and automation.
Over time, this approach leads to more stable and reliable systems with fewer manual interventions required.
Integration of DevOps Principles into CloudOps Practices
CloudOps and DevOps are closely related, but they focus on different aspects of the software lifecycle. DevOps emphasizes collaboration between development and operations, while CloudOps focuses on operational excellence in cloud environments.
In practice, CloudOps extends DevOps principles by applying them specifically to cloud infrastructure and services.
Continuous integration and continuous deployment pipelines are a key part of this integration. These pipelines ensure that code changes are automatically tested, validated, and deployed to production environments.
CloudOps professionals play a critical role in designing and maintaining these pipelines. They ensure that infrastructure supports rapid and reliable deployment cycles.
Another key area of integration is feedback loops. CloudOps systems continuously provide feedback to development teams through monitoring and observability data.
This allows developers to understand how their applications perform in real-world conditions and make improvements accordingly.
The combination of DevOps and CloudOps creates a highly efficient and responsive development ecosystem where software and infrastructure evolve together continuously.
Skills That Define Success in the CloudOps Era
Success in CloudOps environments requires a diverse set of skills that go beyond traditional system administration.
Technical skills such as cloud architecture design, automation scripting, and infrastructure management are essential. However, equally important are analytical skills related to performance optimization and system design.
Understanding distributed systems is also critical, as most modern applications are built using microservices and multi-region architectures.
Security knowledge is another key requirement. CloudOps professionals must understand identity management, encryption, and compliance frameworks.
In addition, problem-solving and critical thinking skills are essential for diagnosing complex system issues in distributed environments.
Communication skills also play an important role, especially in collaborative environments where multiple teams are involved in system design and operations.
The combination of these skills defines the modern CloudOps engineer and reflects the complexity of today’s cloud environments.
CloudOps in Real-World Cloud Architecture: How Systems Are Actually Built and Operated
The shift from SysOps to CloudOps becomes most visible when you look at how modern cloud systems are actually designed and operated in real environments. In earlier IT models, infrastructure was built in layers that were relatively fixed and predictable. Servers were provisioned, applications were deployed, and changes were made cautiously because downtime was expensive and recovery was slow.
CloudOps replaces this static mindset with a dynamic and continuously evolving model. Infrastructure is no longer treated as a fixed asset but as a flexible system that can expand, contract, and reconfigure itself based on demand, performance needs, and business requirements.
In practical terms, this means that cloud architecture is now built around elasticity and automation. Every component is designed with change in mind. Systems are expected to scale up during peak usage and scale down during quiet periods without manual intervention.
This flexibility is made possible by cloud-native services and automation frameworks that continuously manage infrastructure behavior. Instead of manually adjusting systems, CloudOps professionals design policies and automation rules that govern how systems respond to different conditions.
Modern cloud architecture is also heavily distributed. Applications are rarely hosted on a single server or even within a single region. Instead, they are spread across multiple availability zones, regions, and service layers. This distribution improves resilience but also increases complexity.
CloudOps plays a critical role in managing this complexity. It ensures that all components of a system remain synchronized, secure, and performant despite being spread across multiple environments.
The Shift from Static Infrastructure to Elastic Cloud Systems
One of the most important architectural changes in the CloudOps era is the move from static infrastructure to elastic systems. In traditional SysOps environments, capacity planning was a major concern. Organizations had to estimate future demand and provision infrastructure accordingly.
This often led to over-provisioning, where excess capacity was maintained to handle peak loads, resulting in wasted resources. Alternatively, under-provisioning could lead to performance issues during traffic spikes.
CloudOps eliminates this limitation by introducing elasticity. Systems automatically adjust their resources based on real-time demand.
For example, when traffic increases, additional compute resources are automatically deployed. When traffic decreases, unnecessary resources are shut down.
This elasticity is driven by automation rules and cloud-native scaling services. These systems continuously monitor usage patterns and adjust infrastructure accordingly.
Elasticity also extends to storage and networking. Data storage systems can grow dynamically, and network resources can be adjusted to maintain performance.
The result is a more efficient and cost-effective infrastructure model that aligns resources with actual demand rather than predictions.
Microservices and Distributed System Design in CloudOps
CloudOps is closely tied to the rise of microservices architecture. Instead of building monolithic applications, modern systems are divided into smaller, independent services that communicate with each other.
Each microservice is responsible for a specific function and can be developed, deployed, and scaled independently.
This approach provides several advantages. It improves scalability, as individual services can be scaled based on demand. It also improves resilience, since failures in one service do not necessarily impact the entire system.
However, microservices also introduce complexity. Communication between services must be carefully managed, and system behavior becomes harder to predict.
CloudOps addresses this complexity by introducing standardized communication patterns, observability tools, and automated deployment pipelines.
Distributed tracing becomes essential in microservices environments. It allows engineers to follow requests as they move across multiple services, helping identify performance bottlenecks and failure points.
Service discovery, load balancing, and API gateways are also critical components of distributed system design.
CloudOps ensures that all these components work together seamlessly to maintain system stability and performance.
Automation Pipelines and Continuous Delivery Systems
In CloudOps environments, automation is not limited to infrastructure provisioning. It extends deeply into application deployment and lifecycle management.
Continuous integration and continuous delivery pipelines form the backbone of modern software deployment strategies. These pipelines automate the process of building, testing, and deploying applications.
Every code change is automatically validated before being deployed to production environments. This reduces the risk of introducing errors and accelerates the release cycle.
CloudOps professionals are responsible for designing and maintaining these pipelines. They ensure that deployments are consistent, repeatable, and secure.
Automation pipelines also include rollback mechanisms. If a deployment fails or causes issues, systems can automatically revert to a previous stable version.
This level of automation significantly reduces downtime and improves system reliability.
In addition, pipelines are often integrated with monitoring systems. This allows real-time feedback on deployment performance and system behavior after updates.
The combination of automation and continuous delivery enables organizations to release updates frequently without compromising stability.
Cloud Security Integration in Operational Workflows
Security in CloudOps is not treated as a separate layer but as an integrated part of every operational process.
This approach is often referred to as “security by design.” It means that security considerations are included from the very beginning of system design and continue throughout the entire lifecycle.
Identity and access management systems control who can access resources and what actions they can perform. These permissions are often defined as code and managed alongside infrastructure configurations.
Encryption is applied both at rest and in transit to protect sensitive data. Network security policies ensure that only authorized traffic can flow between services.
CloudOps also includes automated security scanning. Systems are continuously checked for vulnerabilities, misconfigurations, and compliance violations.
When issues are detected, automated workflows can apply fixes or alert security teams for further investigation.
Another important aspect is least privilege access. Users and services are only granted the minimum permissions required to perform their tasks.
This reduces the risk of unauthorized access and limits the potential impact of security breaches.
In CloudOps environments, security is an ongoing process rather than a one-time implementation.
Observability-Driven Architecture Design
Modern cloud systems are designed with observability in mind from the beginning. This means that systems are built to generate meaningful data that can be used to understand their behavior.
Observability is not just about collecting data—it is about making systems understandable through their outputs.
Metrics provide high-level insights into system performance, such as response times, error rates, and resource utilization.
Logs provide detailed event information that helps diagnose specific issues.
Traces show how requests move through distributed systems, revealing dependencies and performance bottlenecks.
Together, these data sources create a complete picture of system behavior.
CloudOps professionals use this information to optimize performance, identify issues, and improve system design.
Observability also supports predictive analysis. By analyzing trends over time, teams can anticipate potential issues before they occur.
This proactive approach is a key advantage of CloudOps over traditional operational models.
Cloud Resilience and Fault-Tolerant System Design
Resilience is a core principle of CloudOps architecture. Systems are designed to continue functioning even when individual components fail.
This is achieved through redundancy, failover mechanisms, and distributed architecture.
For example, applications may be deployed across multiple availability zones. If one zone experiences an outage, traffic is automatically redirected to healthy zones.
Data is often replicated across multiple storage systems to prevent loss in case of failure.
Load balancers distribute traffic across multiple instances to prevent overload and improve performance.
Auto-healing systems automatically replace failed components without manual intervention.
These resilience mechanisms ensure that systems remain available even under adverse conditions. CloudOps professionals design and manage these systems to ensure maximum uptime and reliability. Resilience is not treated as an optional feature but as a fundamental requirement in cloud architecture.
Cost Efficiency Through Intelligent Resource Management
Cost efficiency is one of the most important aspects of CloudOps. Unlike traditional IT environments, where costs were largely fixed, cloud environments operate on a usage-based model.
This means that inefficient resource usage can quickly lead to increased operational costs.
CloudOps introduces intelligent resource management strategies to address this challenge.
Resources are continuously monitored and adjusted based on usage patterns. Unused resources are automatically shut down, and underutilized resources are optimized.
Storage systems are often tiered, with different performance and cost levels depending on data access patterns.
Compute resources are selected based on workload requirements to avoid over-provisioning.
Automation plays a key role in cost optimization. Systems can dynamically adjust resource allocation based on demand.
Cost monitoring tools provide real-time visibility into spending patterns, allowing teams to make informed decisions.
CloudOps ensures that cost efficiency is maintained without sacrificing performance or reliability.
Multi-Region and Global Cloud Deployment Strategies
Modern cloud systems often operate across multiple geographic regions to improve performance and resilience.
Multi-region deployment allows applications to serve users from the nearest location, reducing latency and improving user experience.
It also provides redundancy in case of regional failures.
However, multi-region architecture introduces complexity in data synchronization, consistency, and traffic routing.
CloudOps manages this complexity through automated replication systems, global load balancing, and consistent deployment strategies.
Data consistency models are carefully chosen based on application requirements. Some systems prioritize consistency, while others prioritize availability.
Traffic routing systems ensure that users are directed to the most appropriate region based on location and system health.
CloudOps professionals design these systems to balance performance, cost, and reliability across global infrastructure.
The Continuous Evolution of Cloud Operations Practices
CloudOps is not a static concept. It continues to evolve as cloud technologies advance and new challenges emerge.
Emerging technologies such as serverless computing, edge computing, and AI-driven automation are further transforming how cloud operations are managed.
Serverless computing reduces the need for infrastructure management by automatically handling resource provisioning.
Edge computing brings processing closer to users, reducing latency and improving performance for real-time applications.
AI-driven automation is increasingly being used to predict system behavior, optimize performance, and detect anomalies.
These advancements are making cloud systems more intelligent and autonomous.
CloudOps professionals must continuously adapt to these changes by learning new tools, frameworks, and architectural patterns.
The role is becoming more strategic over time, focusing on system design, optimization, and automation rather than manual operations.
CloudOps represents the future direction of cloud computing, where systems are increasingly self-managing and highly adaptive to change.
Event-Driven Architecture and Reactive Cloud Operations
One of the most significant advancements shaping CloudOps is the rise of event-driven architecture. In this model, systems do not rely on constant manual oversight or fixed schedules to perform tasks. Instead, they react automatically to events as they occur within the environment.
An event can be anything from a sudden spike in user traffic, a file being uploaded, a database update, or a system metric crossing a predefined threshold. Once an event is detected, automated workflows are triggered to handle the situation without human intervention.
This approach is fundamentally different from traditional operational models, where actions were often performed at scheduled intervals or in response to manual monitoring. Event-driven systems are more dynamic, responsive, and efficient because they operate only when needed.
In CloudOps environments, event-driven design is used to improve scalability and responsiveness. For example, when traffic increases unexpectedly, an event may trigger the automatic provisioning of additional compute resources. When traffic decreases, another event may scale those resources back down.
This reactive model reduces unnecessary resource consumption and ensures that systems remain efficient even under fluctuating demand.
Policy-Based Automation and Governance Enforcement
Another important aspect of CloudOps is the use of policy-based automation. Instead of relying on manual enforcement of rules, organizations define policies that automatically govern system behavior.
These policies act as guardrails that ensure infrastructure remains secure, compliant, and consistent. They can control everything from resource creation to network configuration and access permissions.
For example, a policy might prevent the deployment of unsecured storage systems or restrict certain types of traffic between services. If a violation occurs, automated systems can either block the action or trigger corrective measures.
This approach reduces the need for constant human oversight and ensures that governance is consistently applied across all environments.
Policy-based automation also improves scalability. As cloud environments grow, manually managing compliance becomes impossible. Automated governance ensures that standards are maintained regardless of system size or complexity.
In CloudOps, governance is not a separate function but an embedded layer within infrastructure management.
Intelligent Load Distribution and Traffic Optimization
CloudOps also introduces advanced techniques for managing application traffic efficiently. Intelligent load distribution ensures that user requests are handled in the most effective way possible across available resources.
Instead of distributing traffic evenly, modern systems analyze real-time conditions such as server performance, geographic location, and network latency to make routing decisions.
This ensures that users experience consistent performance even during high-demand periods or partial system failures.
Traffic optimization also includes techniques such as caching, edge delivery, and request prioritization. Frequently accessed data can be stored closer to users to reduce response times, while less critical requests may be processed with lower priority during peak load conditions.
These mechanisms work together to ensure that systems remain responsive and stable under varying conditions.
CloudOps engineers design and configure these systems to balance performance, reliability, and cost efficiency.
Predictive Operations and AI-Assisted Cloud Management
A growing trend in CloudOps is the use of predictive analytics and artificial intelligence to improve system operations. Instead of reacting to issues after they occur, systems are increasingly capable of anticipating problems before they happen.
Predictive models analyze historical data, system behavior, and usage patterns to forecast potential failures, performance bottlenecks, or resource shortages.
This allows automated systems to take preventive actions such as scaling resources, adjusting configurations, or rerouting traffic before users are affected.
AI-assisted operations also help identify anomalies that might not be obvious through traditional monitoring. Subtle changes in system behavior can be detected early and investigated before they escalate into serious issues.
Over time, these intelligent systems improve their accuracy by learning from past incidents and operational data.
This shift toward predictive CloudOps represents a major step toward fully autonomous cloud environments where systems manage themselves with minimal human intervention.
Conclusion
The evolution from SysOps to CloudOps marks a fundamental shift in how cloud environments are designed, managed, and optimized. It reflects a broader transformation in the IT industry where manual system administration is giving way to intelligent, automated, and continuously evolving infrastructure.
CloudOps is not simply a rebranding of existing operational practices. It represents a deeper change in mindset, where systems are no longer treated as static assets but as dynamic, self-adjusting ecosystems. This shift has been driven by the rapid adoption of cloud computing, the increasing complexity of distributed systems, and the growing demand for scalability, resilience, and efficiency.
At the core of CloudOps lies automation. Tasks that once required manual intervention are now handled by intelligent workflows and event-driven systems. This reduces operational overhead, minimizes human error, and enables faster response times. Alongside automation, observability has become a critical pillar, allowing teams to understand system behavior in real time and make informed decisions based on data rather than assumptions.
Security and governance have also evolved into integrated components of cloud operations. Instead of being applied after systems are built, they are now embedded into every stage of design and deployment. This ensures that compliance, protection, and control are maintained consistently across all environments.
Perhaps most importantly, CloudOps reflects the growing need for adaptability in modern IT systems. As workloads become more distributed and user demands continue to fluctuate, organizations must rely on architectures that can respond instantly and efficiently to change.
The future of cloud operations will likely move even further toward autonomy, with AI-driven systems playing a larger role in prediction, optimization, and decision-making. For IT professionals, this means continuous learning and adaptation are essential.
CloudOps is ultimately about building smarter systems that require less manual effort while delivering greater reliability, performance, and scalability in an increasingly digital world.