Modern digital systems generate data at a pace that would have been unimaginable just a decade ago. Every online search, mobile app interaction, financial transaction, social media post, and sensor reading contributes to an ever-growing ocean of information. This constant stream of data has transformed how organizations operate, compete, and make decisions. However, raw data on its own holds limited value. The real challenge lies in collecting it efficiently, organizing it meaningfully, and making it accessible for analysis at scale.
This is where big data engineers become essential. They operate behind the scenes, building the infrastructure that allows organizations to transform fragmented and chaotic data into structured, usable assets. Without them, even the most advanced analytics or machine learning systems would struggle to function effectively.
Businesses today are not just interested in storing data; they want to process it in real time, analyze patterns instantly, and respond to insights without delay. Whether it is detecting fraud in banking transactions, recommending products in e-commerce, or optimizing logistics in supply chains, everything depends on reliable data pipelines. Big data engineers are responsible for making those pipelines possible.
As industries continue to digitize operations, the scale and complexity of data will only increase. This creates a continuous demand for professionals who can design systems capable of handling massive workloads without breaking down. In many ways, big data engineers have become the architects of the modern data-driven economy.
What a Big Data Engineer Actually Does in Modern Organizations
A big data engineer is primarily responsible for designing and maintaining systems that handle large-scale data processing. Unlike traditional software engineers who may focus on application development, big data engineers specialize in the infrastructure that supports data movement and transformation across systems.
Their work starts with identifying where data originates. This could include mobile applications, IoT devices, customer databases, or third-party APIs. Once identified, they design systems that can reliably capture this data without loss or delay. These systems must be able to handle both structured data, such as database records, and unstructured data, such as logs, images, or text streams.
After data is collected, it must be transformed into a usable format. Raw data is often messy, incomplete, or inconsistent. Big data engineers build processes that clean, normalize, and structure this information so it can be used by analysts and data scientists. This stage is critical because poor-quality data leads to unreliable insights.
Another important aspect of the role involves ensuring that data is stored efficiently. Given the volume of information modern organizations deal with, storage systems must be scalable, cost-effective, and secure. Engineers must decide how data should be partitioned, indexed, and retained over time.
Beyond technical tasks, big data engineers also collaborate closely with other teams. Data analysts rely on them to ensure that datasets are accurate and accessible. Data scientists depend on them to provide structured inputs for machine learning models. Business teams rely on them to ensure that insights are delivered in real time when needed.
This collaborative nature makes the role both technical and strategic. It is not just about writing code; it is about building systems that support decision-making across an entire organization.
Core Responsibilities Across Data Systems and Pipelines
One of the most important responsibilities of a big data engineer is building data pipelines. These pipelines act as automated pathways that move data from one system to another. A typical pipeline involves three stages: ingestion, processing, and storage.
During ingestion, data is collected from multiple sources. This stage requires systems that can handle high-speed input without data loss. Depending on the use case, data may arrive in real time or in scheduled batches.
The processing stage is where the transformation happens. Engineers apply rules, filters, and logic to convert raw data into structured formats. This can involve removing duplicates, correcting errors, or merging data from different sources. In large systems, this stage often requires distributed computing to handle massive workloads efficiently.
The final stage is storage. Processed data must be stored in a way that makes it easy to retrieve and analyze. This often involves data warehouses or data lakes designed for scalability and performance. Engineers must ensure that storage systems remain efficient even as data volumes grow over time.
Another major responsibility is performance optimization. Data systems can become slow or inefficient if not properly maintained. Engineers continuously monitor processing speeds, memory usage, and system performance to identify bottlenecks. They then adjust configurations or redesign workflows to improve efficiency.
Reliability is also critical. In many industries, even a few minutes of downtime can lead to significant financial losses. Big data engineers must design fault-tolerant systems, meaning they can continue operating even if individual components fail. This often involves redundancy, failover mechanisms, and distributed architecture.
Security is another key responsibility. Data often contains sensitive information, including personal details, financial records, or proprietary business insights. Engineers must implement access controls, encryption, and compliance frameworks to ensure data remains protected.
Understanding the Big Data Ecosystem
The big data ecosystem is made up of interconnected technologies that work together to process and manage large volumes of data. Understanding how these components interact is essential to understanding the role of a big data engineer.
At the core of this ecosystem are data sources. These are the origins of all data, including applications, sensors, websites, and external APIs. Each source generates data in different formats and at different speeds, creating a complex environment for engineers to manage.
Once data is generated, it moves into ingestion systems. These systems are responsible for capturing data in real time or batch mode. Real-time ingestion is particularly important for applications that require immediate insights, such as fraud detection or live monitoring systems.
After ingestion, data flows into processing frameworks. These frameworks are designed to handle large-scale computations across distributed systems. Instead of relying on a single machine, they divide tasks across multiple nodes, allowing for faster and more efficient processing.
Processed data is then stored in specialized storage systems. These systems are optimized for different use cases. Some are designed for fast querying, while others are built for long-term storage of massive datasets. The choice of storage depends on how the data will be used later.
Finally, data is accessed by analytics tools, dashboards, and machine learning systems. These tools convert raw information into insights that businesses can act on. Without the underlying infrastructure built by big data engineers, none of these tools would function effectively.
The ecosystem is constantly evolving, with new tools and frameworks emerging regularly. However, the core principles remain the same: collect data efficiently, process it reliably, store it securely, and make it accessible for decision-making.
Key Technologies That Define the Role
Big data engineering relies on a wide range of technologies, each serving a specific purpose within the data lifecycle. These tools can be grouped into several major categories based on their function.
Distributed processing frameworks form the backbone of big data systems. These frameworks allow engineers to process massive datasets by distributing workloads across multiple machines. This approach ensures that even extremely large datasets can be processed in a reasonable amount of time.
Streaming technologies play a critical role in real-time data processing. Instead of waiting for data to be collected in batches, streaming systems process data as it arrives. This is essential for applications that require instant insights, such as monitoring systems or real-time recommendations.
Data pipeline orchestration tools help manage complex workflows. In large organizations, data does not flow through a single path. Instead, it moves through multiple stages, each with its own dependencies. Orchestration tools ensure that these workflows run smoothly and in the correct order.
Cloud platforms have become central to modern data engineering. They provide scalable infrastructure that allows engineers to build and deploy systems without managing physical hardware. Cloud environments also offer specialized services for data storage, processing, and analytics.
Storage technologies are equally important. Different types of storage systems are designed for different workloads. Some prioritize speed, while others focus on scalability or cost efficiency. Engineers must choose the right storage solution based on the needs of the organization.
Finally, monitoring tools ensure that systems remain healthy and efficient. They provide visibility into system performance, helping engineers detect and resolve issues before they impact operations. This proactive approach is essential in maintaining reliable data systems.
How Big Data Engineers Fit Into Data Teams and Business Decision Making
Big data engineers play a foundational role within data teams. While they may not directly analyze data or build machine learning models, their work enables those activities to happen effectively.
In a typical data team, engineers work alongside data analysts, data scientists, and business intelligence professionals. Each role has a distinct function, but they are all interconnected. Engineers provide the infrastructure, analysts interpret the data, and scientists build predictive models.
The impact of big data engineers extends beyond technical teams. Business leaders rely on data-driven insights to make strategic decisions. Whether it is launching a new product, entering a new market, or optimizing operations, these decisions depend on accurate and timely data.
Because of this, engineers often find themselves indirectly influencing business outcomes. A well-designed data pipeline can improve the speed and accuracy of decision-making across an entire organization. On the other hand, poorly designed systems can lead to delays, inconsistencies, or incorrect insights.
Communication is also an important part of the role. Engineers must understand the needs of different teams and translate them into technical solutions. This requires not only technical expertise but also an understanding of business priorities.
As organizations become more data-driven, the role of the big data engineer continues to evolve. They are no longer just system builders; they are key contributors to how businesses operate and grow in a data-centric world.
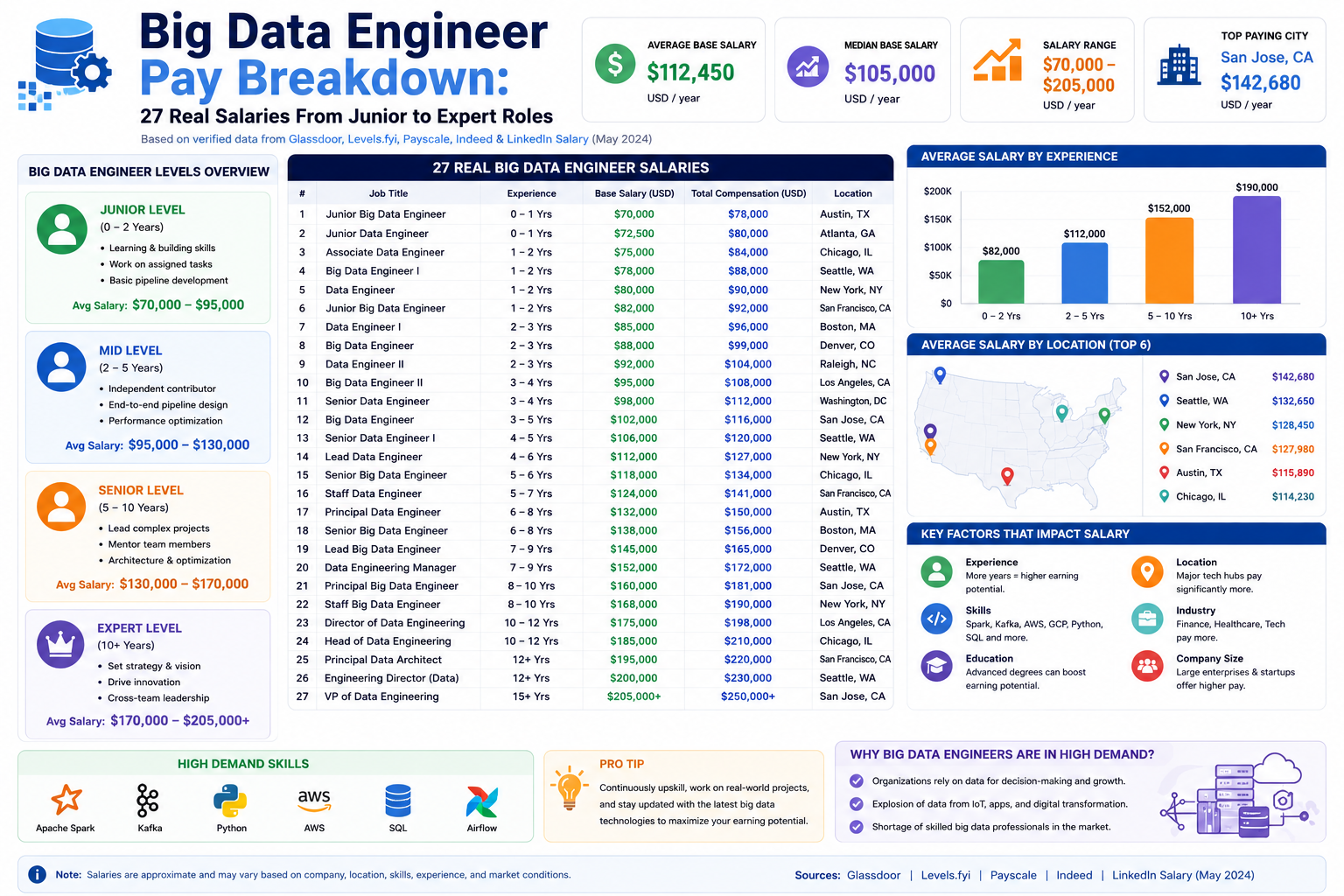
How Compensation is Structured in Big Data Engineering
Compensation for big data engineers is rarely based on a single fixed formula. Instead, it is built from multiple components that together define total earning potential. While base salary is the most visible part, it is only one piece of a broader structure that often includes performance bonuses, stock-based incentives, and role-specific benefits tied to technical impact.
At its core, base salary reflects the expected contribution of an engineer in a standard working capacity. However, in data-heavy organizations where systems directly influence revenue, performance-based compensation becomes a major differentiator. Engineers responsible for optimizing data pipelines that reduce costs or improve system speed can often receive additional financial rewards tied to measurable outcomes.
Equity compensation is another significant factor, particularly in technology-driven companies. Instead of only receiving immediate cash compensation, engineers may receive ownership stakes in the company. This creates long-term financial alignment between individual performance and organizational growth. In fast-scaling companies, this component can sometimes exceed the base salary value over time.
Bonuses are often linked to project delivery, system stability, or the successful implementation of large-scale infrastructure improvements. In some environments, engineers may also receive retention bonuses, especially when working with highly specialized or difficult-to-replace systems.
This layered compensation structure means that two engineers with similar base salaries can have vastly different total earnings depending on performance, company type, and equity value.
Factors That Influence Earnings Beyond Location
While geography plays a visible role in salary variation, many other factors have an equally strong influence over how much a big data engineer earns. One of the most important is technical depth. Engineers who understand systems at both a high architectural level and a low implementation level tend to command higher compensation because they can operate independently across complex environments.
The breadth of tools and technologies also matters. Engineers who specialize in only one platform may find limited earning growth compared to those who can work across multiple ecosystems. Flexibility in adapting to different cloud environments, data frameworks, and orchestration tools significantly increases value in the job market.
Another major factor is problem complexity. Not all data engineering roles are equal in difficulty. Some engineers work on relatively stable systems with predictable workloads, while others manage real-time, high-throughput environments where even small failures can result in major operational disruptions. The more critical the system, the higher the compensation tends to be.
Communication ability also plays an unexpected but important role. Engineers who can translate technical concepts into business language often take on more strategic responsibilities. This increases their visibility within organizations and can lead to faster salary growth.
Finally, ownership of systems rather than just tasks strongly influences pay. Engineers who design entire data architectures or lead infrastructure decisions are compensated at a significantly higher level than those who only maintain existing pipelines.
Industry-Specific Salary Differences and Demands
Different industries place different levels of value on big data engineering expertise. In finance, for example, data systems are directly tied to revenue generation and risk management. Even small improvements in data processing speed or accuracy can lead to substantial financial gains. As a result, engineers in this sector often receive higher compensation compared to many other industries.
Healthcare is another industry where data engineering is highly valued. The complexity of medical data, combined with strict regulatory requirements, makes system design particularly challenging. Engineers working in this space must ensure both performance and compliance, which increases their overall market value.
The technology sector remains one of the highest-paying environments due to the scale of data being processed. Social media platforms, cloud service providers, and software companies often operate at massive data volumes, requiring highly optimized and scalable infrastructure.
Retail and e-commerce also offer strong compensation packages, particularly for engineers working on recommendation systems, customer analytics, and supply chain optimization. These systems directly influence sales performance, making data engineering a revenue-impacting function.
On the other hand, industries such as education or small-scale manufacturing may offer lower base compensation, but they often provide more stable workloads and less system complexity.
Career Progression Path and Salary Growth Over Time
The career trajectory of a big data engineer typically follows a structured but flexible path. At the beginning stage, engineers focus on learning system fundamentals, working with existing pipelines, and supporting senior team members. Compensation at this level is generally moderate, reflecting the learning-oriented nature of the role.
As engineers move into mid-level positions, they begin to take ownership of entire pipelines or system components. This stage is marked by increased responsibility, including debugging production issues, optimizing workflows, and contributing to architectural decisions. Salary growth at this stage is often significant, reflecting the increased impact on system performance.
At the senior level, engineers transition into architectural and leadership roles. They design large-scale systems, define data strategies, and often mentor junior engineers. Their work influences not just technical systems but also organizational direction. Compensation at this level reflects both technical expertise and leadership responsibility.
Beyond senior roles, some engineers move into staff or principal positions. These roles focus less on daily implementation and more on long-term system design, cross-team coordination, and strategic planning. Compensation at this stage can increase substantially due to the rarity of such expertise.
Another possible path involves transitioning into specialized roles such as data architecture, machine learning infrastructure, or cloud engineering. These paths often lead to higher compensation due to their specialized nature.
Skills That Directly Impact Earning Potential
Technical skills form the foundation of salary growth in big data engineering. However, not all skills contribute equally to compensation. Some areas of expertise consistently correlate with higher earning potential due to their complexity and demand.
Distributed system design is one of the most valuable skill areas. Engineers who understand how to build systems that scale across multiple machines are highly sought after because modern data environments rarely operate on single servers.
Real-time data processing is another high-value skill. Organizations increasingly require instant insights rather than delayed reports, making streaming data expertise particularly important.
Data modeling skills also significantly impact earnings. Engineers who can design efficient and scalable data structures help organizations reduce storage costs and improve query performance.
Another important area is data reliability engineering. Ensuring that data pipelines are fault-tolerant, self-healing, and resilient under load is critical in production environments. Engineers with this skill set are often trusted with mission-critical systems.
Soft skills such as collaboration and system documentation also play an indirect role in compensation. Engineers who can clearly document systems and collaborate across teams reduce operational risk, making them more valuable in organizational structures.
The Role of Cloud and Distributed Systems in Pay Scales
Cloud computing has fundamentally reshaped the big data engineering landscape. Instead of relying on physical infrastructure, companies now build systems on scalable cloud platforms. This shift has significantly influenced salary structures.
Engineers with deep cloud expertise are in particularly high demand. Understanding how to design systems using cloud-native services requires knowledge beyond traditional data engineering. This includes cost optimization, service integration, and distributed architecture design.
Distributed systems also play a central role in determining compensation. The ability to design systems that can handle large-scale data processing across multiple nodes is one of the most important skills in the field.
Cloud environments also introduce new challenges such as latency management, data consistency across regions, and cost control. Engineers who can balance performance with cost efficiency are especially valuable.
As cloud systems continue to evolve, engineers who stay updated with new services and architectural patterns tend to experience faster salary growth compared to those who rely on outdated approaches.
How Hiring Decisions Are Made for Big Data Engineers
Hiring decisions in big data engineering roles are influenced by a combination of technical evaluation and practical problem-solving ability. Employers are not only interested in theoretical knowledge but also in how candidates apply that knowledge in real-world scenarios.
One of the key evaluation criteria is system design capability. Candidates are often assessed on their ability to design scalable data pipelines that can handle large volumes of information efficiently.
Another important factor is hands-on experience with production systems. Employers value engineers who have worked in real-time environments where performance, reliability, and scalability are critical.
Problem-solving ability is also heavily evaluated. Big data environments often involve unexpected issues such as data inconsistencies, system failures, or performance bottlenecks. Engineers must demonstrate the ability to diagnose and resolve such issues quickly.
Cultural fit and collaboration skills also influence hiring decisions. Since big data engineers work closely with multiple teams, communication and teamwork are essential.
Finally, adaptability plays a major role. The data engineering landscape evolves rapidly, and companies prefer candidates who can learn new technologies and adapt to changing system requirements.
Interview Expectations and Evaluation Criteria
Interviews for big data engineering roles tend to focus on both technical depth and system-level thinking. Candidates are expected to demonstrate an understanding of how large-scale data systems operate under real-world constraints.
One major area of focus is data pipeline design. Candidates may be asked to explain how they would build systems that ingest, process, and store large volumes of data efficiently.
Another common evaluation area is distributed computing. Understanding how to divide workloads across multiple systems is essential in modern data environments.
Candidates are also often tested on troubleshooting scenarios. This includes identifying bottlenecks in data pipelines or diagnosing failures in streaming systems.
In addition to technical evaluation, interviewers assess communication skills. Engineers must be able to explain complex systems in a way that non-technical stakeholders can understand.
System optimization is another key topic. Candidates may be asked how they would improve the performance of an existing data pipeline or reduce operational costs.
Geographic Trends and Remote Work Influence
Geographic location has traditionally played a major role in salary differences for big data engineers. Major technology hubs tend to offer higher compensation due to higher demand and cost of living. However, the rise of remote work has begun to change this dynamic.
Many companies now hire engineers remotely, allowing talent to work from different regions while still earning competitive salaries. This has led to a gradual reduction in strict geographic salary boundaries.
Despite this shift, location still influences compensation in many cases. Companies may adjust salaries based on the regional cost of living or market benchmarks.
However, engineers with highly specialized skills often experience less geographic restriction, as their expertise is in demand regardless of location.
Remote work has also increased competition in the job market. Engineers now compete on a global scale, making skill development even more important for salary growth.
Emerging Specializations That Command Higher Salaries
As the field evolves, several specialized areas within big data engineering are becoming particularly valuable. These specializations often command higher salaries due to their complexity and scarcity of expertise.
Real-time analytics engineering is one such area. Systems that process and analyze data instantly require advanced knowledge of streaming technologies and low-latency architectures.
Another growing specialization is machine learning infrastructure engineering. This involves building data systems that support training and deployment of machine learning models at scale.
Data security engineering is also becoming increasingly important. With growing concerns around privacy and compliance, engineers who can design secure data systems are in high demand.
Multi-cloud architecture design is another emerging specialization. Organizations are increasingly using multiple cloud providers, requiring engineers who can design systems that operate seamlessly across different environments.
Finally, data observability and reliability engineering are gaining attention. This involves ensuring that data systems are not only functional but also transparent, measurable, and easy to debug in complex environments.
The Evolving Big Data Engineering Stack and Why It Keeps Changing
The technology landscape for big data engineering is not static. It evolves continuously as organizations face new challenges in scale, speed, and complexity. What worked five years ago may still function today, but it is often no longer optimal. This constant evolution is driven by increasing data volume, real-time expectations, and the need for more intelligent systems.
Modern data engineering stacks are built around flexibility. Instead of relying on a single monolithic system, organizations now use modular architectures where different tools handle specific responsibilities. This approach allows engineers to swap, upgrade, or optimize individual components without rebuilding entire systems.
At the center of this evolution is the shift from batch processing to real-time processing. Traditional systems were designed to process data in intervals—hourly, daily, or weekly. Today, businesses expect insights in seconds or milliseconds. This change has forced engineers to adopt streaming-first architectures.
Another major shift is the move toward cloud-native systems. Instead of managing physical servers or on-premise infrastructure, engineers now rely on scalable cloud services. This reduces operational overhead but introduces new complexity in cost management, distributed coordination, and service integration.
Containerization and orchestration technologies have also reshaped how data systems are deployed. Instead of running processes on fixed machines, engineers now deploy workloads in dynamic environments where resources are allocated based on demand.
This evolving stack requires engineers to continuously learn and adapt. Once optional skills are now essential, and new tools emerge frequently. The ability to understand foundational principles rather than just specific technologies has become a critical advantage.
The Rise of Real-Time Data Processing Systems
Real-time data processing has become one of the most important trends in modern data engineering. Instead of waiting for data to be collected and processed in batches, organizations now require continuous data flow and immediate insights.
This shift is driven by industries where timing is critical. In financial trading, even a few seconds of delay can lead to significant losses. In e-commerce, real-time recommendation systems directly influence customer behavior. In cybersecurity, immediate detection of anomalies can prevent major breaches.
Real-time systems rely on streaming architectures that process data as it arrives. Unlike batch systems, which store data before processing it, streaming systems operate continuously. This requires engineers to design pipelines that are both fast and resilient.
One of the biggest challenges in real-time processing is maintaining consistency. Data arrives at different speeds and from different sources, making it difficult to ensure accuracy. Engineers must design systems that can handle out-of-order events, duplicates, and partial failures without breaking.
Latency is another critical factor. Even small delays can reduce the effectiveness of real-time systems. Engineers must carefully optimize every stage of the pipeline, from ingestion to processing to output.
Scalability is equally important. Real-time systems often experience sudden spikes in data volume, especially during peak usage periods. Engineers must ensure that systems can scale dynamically without performance degradation.
As more industries adopt real-time analytics, expertise in streaming systems has become one of the most valuable skill sets in big data engineering.
Distributed Computing and the Challenge of Scale
At the heart of big data engineering lies distributed computing. Instead of processing data on a single machine, distributed systems divide workloads across multiple machines working in parallel.
This approach is essential because modern datasets are too large to be processed efficiently on a single system. Distributed computing allows engineers to scale horizontally, meaning they can add more machines to handle increased workloads.
However, building distributed systems is significantly more complex than traditional computing. Engineers must manage communication between nodes, handle failures, and ensure consistency across the system.
One of the biggest challenges is fault tolerance. In a distributed environment, failures are expected rather than exceptional. Machines can go offline, networks can fail, and processes can crash. Systems must be designed to recover automatically without data loss.
Another challenge is data partitioning. Engineers must decide how to divide data across nodes in a way that balances load and minimizes communication overhead. Poor partitioning can lead to bottlenecks and uneven resource usage.
Synchronization is also a key issue. When multiple nodes process related data, ensuring that results remain consistent requires careful coordination.
Despite these challenges, distributed systems remain the foundation of modern data engineering. They enable the scale and performance required for today’s data-driven applications.
Data Storage Architectures and Their Strategic Importance
Data storage is one of the most critical components of any big data system. The way data is stored directly impacts performance, cost, and accessibility.
Modern data architectures typically use a combination of storage systems rather than relying on a single solution. This approach allows engineers to optimize for different types of workloads.
Object storage systems are commonly used for storing large volumes of unstructured data. These systems are highly scalable and cost-effective, making them ideal for raw data storage.
Data warehouses are used for structured data that requires fast querying and analysis. These systems are optimized for performance and are often used in business intelligence applications.
Data lakes provide a flexible storage layer where both structured and unstructured data can coexist. They are commonly used in environments where data variety is high, and use cases are not fully defined.
Choosing the right storage architecture is not just a technical decision; it is a strategic one. Poor storage design can lead to increased costs, slow performance, and limited scalability.
Engineers must also consider data lifecycle management. Not all data needs to be stored indefinitely. Some data becomes less valuable over time and can be archived or deleted to reduce storage costs.
Security and compliance are also critical considerations. Sensitive data must be protected through encryption, access controls, and auditing mechanisms.
As data volumes continue to grow, storage architecture design has become one of the most important responsibilities in big data engineering.
The Role of Data Pipelines in Modern Systems
Data pipelines are the backbone of big data engineering. They define how data moves from one system to another and how it is transformed along the way.
A well-designed pipeline ensures that data flows smoothly, efficiently, and reliably. It also reduces manual intervention, allowing systems to operate automatically at scale.
Pipelines typically consist of multiple stages, including ingestion, transformation, validation, and storage. Each stage plays a specific role in ensuring data quality and usability.
Ingestion is the first step, where data is collected from various sources. This stage must be able to handle high-volume and high-velocity data without loss.
Transformation is where raw data is cleaned and structured. This stage often involves filtering, aggregation, and enrichment.
Validation ensures that data meets quality standards. This includes checking for missing values, inconsistencies, and errors.
Storage finalizes the pipeline by placing processed data into systems where it can be accessed by analysts or applications.
One of the biggest challenges in pipeline design is managing dependencies. Many pipelines rely on data from other pipelines, creating complex dependency chains.
Another challenge is monitoring. Engineers must ensure that pipelines are functioning correctly and identify issues quickly when they arise.
Modern pipeline systems often include automation features that allow for self-healing and automatic retries in case of failure.
Data Quality and Its Impact on Business Outcomes
Data quality is one of the most important factors influencing the effectiveness of any data system. Poor-quality data can lead to incorrect insights, flawed predictions, and bad business decisions.
Ensuring data quality involves multiple dimensions, including accuracy, completeness, consistency, and timeliness.
Accuracy refers to whether data correctly represents real-world values. Inaccurate data can lead to misleading conclusions.
Completeness refers to whether all required data is present. Missing data can reduce the reliability of the analysis.
Consistency ensures that data remains uniform across different systems. Inconsistent data can create confusion and errors.
Timeliness refers to how up-to-date the data is. Outdated data may no longer reflect current conditions.
Big data engineers play a crucial role in maintaining data quality. They design validation rules, implement monitoring systems, and build processes that detect and correct errors.
In many organizations, data quality is directly tied to revenue. Poor-quality data can lead to incorrect targeting, inefficient operations, or regulatory compliance issues.
Because of this, engineers who specialize in data quality systems are increasingly valued in the job market.
The Importance of Data Governance and Compliance
As data becomes more central to business operations, governance and compliance have become critical responsibilities in big data engineering.
Data governance refers to the management of data availability, usability, integrity, and security. It ensures that data is properly controlled and used responsibly within an organization.
Compliance refers to adherence to legal and regulatory standards. Depending on the industry, this may include privacy laws, financial regulations, or healthcare requirements.
Big data engineers must implement systems that enforce these rules automatically. This includes access controls, audit logging, and data lineage tracking.
Data lineage is particularly important because it allows organizations to trace how data flows through systems. This is essential for debugging, auditing, and compliance reporting.
Security is another key aspect of governance. Engineers must ensure that sensitive data is encrypted, both in storage and in transit.
Failure to implement proper governance can result in legal penalties, financial losses, and reputational damage.
As regulations around data continue to tighten globally, expertise in governance systems is becoming increasingly valuable.
The Growing Importance of Data Reliability Engineering
Data reliability engineering is an emerging discipline within big data engineering that focuses on ensuring systems are dependable, consistent, and resilient.
Unlike traditional system reliability, which focuses on uptime, data reliability focuses on the correctness and trustworthiness of data.
A system may be operational but still produce incorrect or incomplete data. This makes reliability engineering critical for maintaining trust in data-driven systems.
Engineers in this field design monitoring systems that track data accuracy, pipeline performance, and system behavior.
They also implement automated recovery mechanisms that detect and fix issues without human intervention.
Another key aspect is observability. This involves making systems transparent so engineers can understand what is happening inside them at any given time.
Data reliability engineers often work closely with infrastructure teams to ensure that systems remain stable under high load.
As organizations increasingly rely on real-time analytics and automated decision-making, data reliability has become a core requirement rather than an optional feature.
Advanced Optimization Techniques in Big Data Systems
Optimization is a continuous process in big data engineering. As systems grow in size and complexity, inefficiencies can accumulate, leading to performance issues and increased costs.
One common optimization area is query performance. Engineers must ensure that data queries execute efficiently, especially in large datasets.
Another area is resource utilization. Efficient systems use computing resources effectively without overloading infrastructure.
Data partitioning strategies also play a major role in optimization. Proper partitioning can significantly reduce processing time and improve system performance.
Caching is another technique used to improve performance by storing frequently accessed data in memory.
Compression techniques help reduce storage costs and improve data transfer speeds.
Load balancing ensures that no single node in a distributed system becomes a bottleneck.
Optimization is not a one-time task but an ongoing responsibility. As data grows and usage patterns change, systems must be continuously refined to maintain performance.
Automation and the Increasing Role of Intelligent Systems in Data Engineering
As big data environments grow in size and complexity, manual management of pipelines and infrastructure is becoming less practical. This has led to a strong shift toward automation across nearly every layer of data engineering. Automation is no longer limited to simple scheduling tasks; it now extends into system optimization, anomaly detection, and even self-healing data workflows.
Modern data platforms are increasingly designed to reduce human intervention. Instead of engineers manually fixing failed jobs or adjusting performance settings, intelligent systems can now detect issues and take corrective action automatically. For example, if a data pipeline experiences delays due to resource bottlenecks, automated systems can redistribute workloads or scale computing resources without waiting for human input. This reduces downtime and improves overall system reliability.
Another major development is the integration of machine learning techniques into the data infrastructure itself. These systems can analyze historical pipeline performance to predict future failures or inefficiencies. By identifying patterns such as recurring bottlenecks or unusual spikes in data volume, intelligent monitoring tools can proactively alert engineers or adjust configurations in real time. This predictive capability is reshaping how engineers think about system maintenance, shifting the focus from reactive troubleshooting to proactive optimization.
Automation is also improving data quality management. Instead of relying on static validation rules, modern systems can learn what normal data behavior looks like and detect anomalies dynamically. This is especially useful in environments where data sources frequently change or evolve. Intelligent validation systems can adapt without requiring constant manual updates, reducing maintenance overhead while improving accuracy.
At the same time, orchestration systems are becoming more autonomous. Complex workflows that involve multiple dependent stages can now be managed through intelligent scheduling engines that adjust execution timing based on system load, data availability, and priority levels. This ensures that critical data processes are completed efficiently even in highly variable environments.
As these technologies mature, the role of the big data engineer is also evolving. Rather than focusing solely on manual pipeline construction, engineers are increasingly responsible for designing and supervising automated systems. This requires a deeper understanding of system behavior, machine learning integration, and adaptive architecture design. The future of data engineering is not just about managing data—it is about building systems that manage themselves intelligently and continuously improve over time.
Conclusion
Big data engineering has become one of the most important pillars of the modern digital economy. As organizations continue to generate massive volumes of structured and unstructured data, the need for professionals who can design, build, and maintain scalable data systems has grown rapidly. These engineers do far more than manage pipelines; they create the infrastructure that enables analytics, machine learning, and real-time decision-making across industries.
Throughout this discussion, it becomes clear that the role is both highly technical and strategically significant. Big data engineers work with complex systems that require strong knowledge of distributed computing, cloud platforms, data storage architectures, and real-time processing frameworks. At the same time, they must ensure that data remains accurate, secure, and accessible for business use.
Compensation in this field reflects its importance. Salaries are influenced by multiple factors, including experience, industry, technical specialization, and system complexity. Engineers who develop expertise in cloud technologies, streaming systems, and data governance often find themselves in particularly high demand.
As technology continues to evolve, the role of the big data engineer will keep expanding. Automation, artificial intelligence, and real-time analytics are reshaping how data systems are built and managed. This means engineers must continuously adapt, learn new tools, and refine their understanding of large-scale system design.
Ultimately, big data engineering is not just a technical career—it is a foundational force behind modern innovation. Those who master it will remain essential to the future of data-driven decision-making.