In the world of networking and the internet, identifying and accessing resources is a fundamental requirement. Every webpage, file, image, or service that exists online must have a way to be referenced so that users and systems can interact with it efficiently. This is where concepts like URI, URL, and URN come into play. Although these terms are often used interchangeably in casual conversation, they serve distinct purposes within the broader framework of network communication. At their core, all three are designed to help identify resources, but they differ in how they define, locate, or name those resources. To truly understand the differences, it is important to begin with the basic idea that networks rely on standardized methods to avoid confusion and ensure consistency when referencing digital assets. Without such standards, navigating the web or even internal networks would become chaotic and unreliable.
The Role of Standardization in Networking
Networking systems depend heavily on standardization to function smoothly across different devices, platforms, and environments. When you access a website, send an email, or download a file, your system relies on predefined rules and formats to interpret the resource you are trying to reach. URI, URL, and URN are part of these standardized frameworks, ensuring that resources can be identified in a uniform manner regardless of where they are located or how they are accessed. This uniformity allows developers, engineers, and everyday users to interact with resources without needing to understand the underlying complexity of network architecture. By establishing a consistent naming and identification system, these concepts eliminate ambiguity and make communication across networks more efficient.
Defining a Uniform Resource Identifier
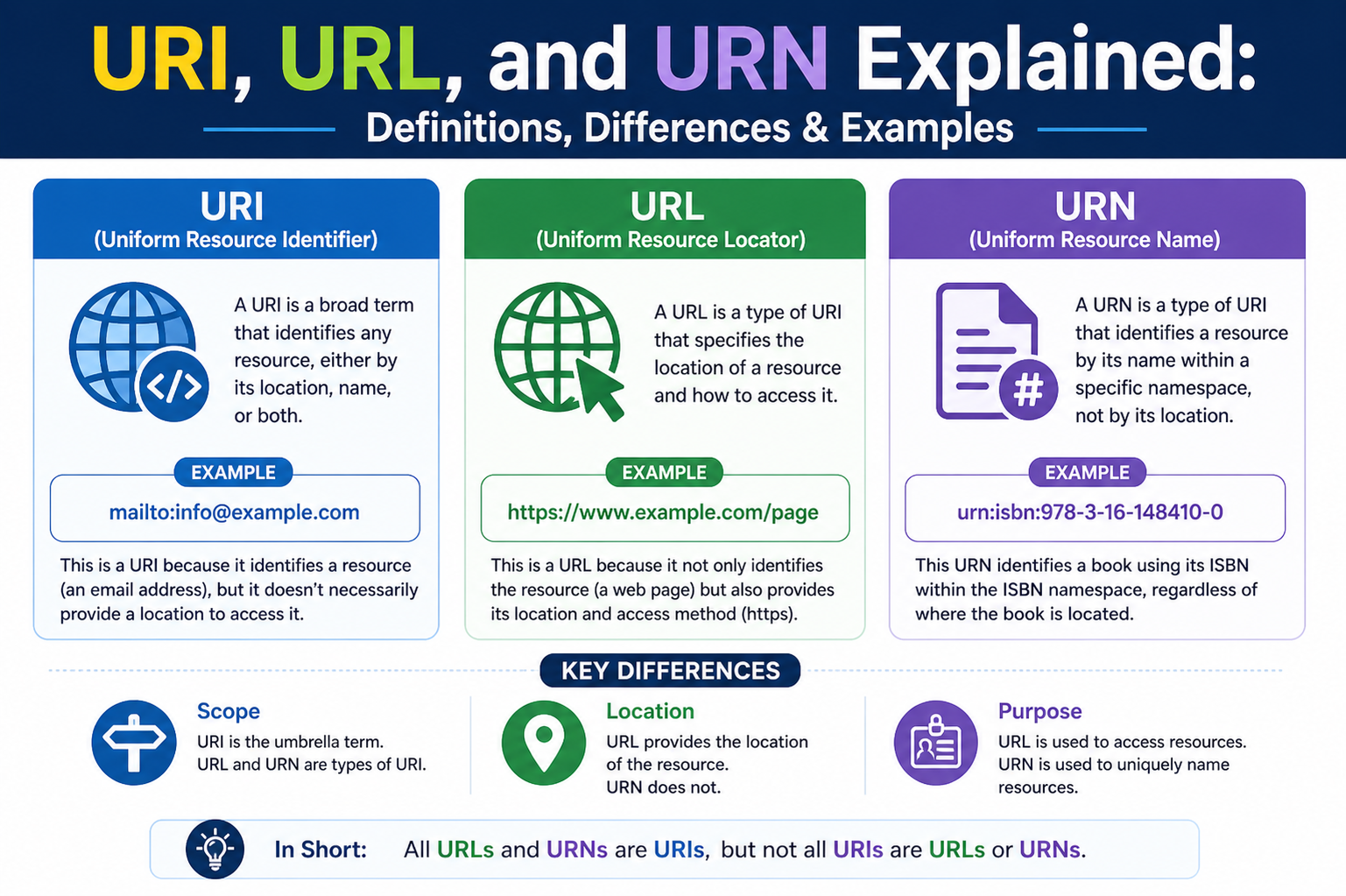
A Uniform Resource Identifier, commonly known as a URI, is the most general concept among the three. It is essentially a string of characters used to identify a resource, whether that resource exists physically on a server or logically within a system. The key idea behind a URI is identification rather than location or access. It acts as a label that distinguishes one resource from another. This means that a URI does not necessarily provide instructions on how to retrieve the resource; instead, it simply ensures that the resource can be uniquely recognized within a given context. Because of its broad definition, a URI serves as the umbrella term under which both URLs and URNs fall.
Breaking Down the Structure of a URI
A URI typically consists of multiple components that work together to form a complete identifier. These components may include a scheme, which indicates the type of resource or protocol, as well as additional parts that specify details about the resource itself. While not all URIs follow the same structure, many share common patterns that make them easier to interpret. For instance, the scheme might suggest whether the resource is accessible via a web browser, email client, or file transfer system. Even though a URI may contain elements that resemble a location or method of access, its primary purpose remains identification. This flexibility allows URIs to adapt to different use cases, making them a foundational element in networking.
Understanding Uniform Resource Locators
A Uniform Resource Locator, or URL, is a specific type of URI that not only identifies a resource but also provides the means to locate it. In simple terms, a URL tells you where a resource is and how to access it. This dual functionality makes URLs the most commonly used form of resource identification on the internet. Whenever you type a web address into a browser, you are using a URL to direct your request to a specific server and retrieve the desired content. The inclusion of access methods, such as protocols, distinguishes URLs from other types of URIs and gives them a practical role in everyday internet usage.
The Components That Make a URL Functional
A URL is composed of several key parts that work together to enable resource access. The scheme or protocol is one of the most important components, as it defines how the resource should be accessed. Common examples include protocols used for secure web browsing, file transfers, and email communication. Following the protocol, the URL typically includes a domain name or address that specifies the location of the resource. Additional elements, such as paths and query parameters, may further refine the request by pointing to a specific file or piece of data within the resource. This structured format allows systems to interpret URLs accurately and perform the necessary actions to retrieve the requested content.
Exploring Uniform Resource Names
A Uniform Resource Name, or URN, represents another category within the broader URI framework. Unlike URLs, URNs are designed to identify resources by name without providing any information about their location or how to access them. The primary goal of a URN is to offer a persistent and globally unique identifier that remains consistent even if the resource’s location changes over time. This makes URNs particularly useful in scenarios where long-term identification is more important than immediate accessibility. By focusing solely on naming, URNs ensure that resources can be referenced reliably without being tied to a specific location or access method.
The Importance of Global Uniqueness in URNs
One of the defining characteristics of a URN is its requirement for global uniqueness. This means that each URN must correspond to a single resource and cannot be duplicated or reused for another resource. Achieving this level of uniqueness often involves the use of standardized naming systems or namespaces that are carefully managed to prevent conflicts. The emphasis on uniqueness ensures that URNs can serve as stable identifiers across different systems and environments. Even if a resource is moved, replicated, or modified, its URN remains unchanged, providing a consistent reference point for users and applications alike.
Comparing Identification and Location
A key distinction between URI, URL, and URN lies in the concepts of identification and location. While all three are used to identify resources, only URLs provide explicit information about where a resource is located and how to access it. URNs, on the other hand, focus exclusively on naming and do not offer any details about location or retrieval methods. URIs encompass both approaches, acting as a general framework that includes identifiers based on names, locations, or a combination of both. Understanding this distinction is crucial for grasping how these terms are used in different contexts and why they are not interchangeable despite their similarities.
The Relationship Between URI, URL, and URN
The relationship between these three concepts can be understood as a hierarchy. At the top level, the URI serves as the broadest category, encompassing all forms of resource identification. Within this category, URLs and URNs represent more specific types of identifiers. Every URL and URN is a URI, but not every URI qualifies as a URL or URN. This hierarchical structure helps clarify the roles of each term and highlights the importance of using the correct terminology when discussing resource identification. By recognizing that URLs and URNs are subsets of URIs, it becomes easier to understand their unique characteristics and applications.
Practical Examples to Illustrate the Differences
To better understand the differences between these concepts, it can be helpful to consider practical examples. Imagine a library system where books are organized and cataloged for easy access. In this analogy, a URI would represent the general identifier used to distinguish one book from another. A URL would correspond to the specific location of a book within the library, including details about the section, shelf, and position where it can be found. A URN, on the other hand, would act as a unique identifier assigned to the book, such as a standardized code that remains constant regardless of where the book is stored. This comparison highlights how each concept serves a distinct purpose while contributing to the overall system of resource identification.
Why These Distinctions Matter in Networking
Understanding the differences between URI, URL, and URN is not just a theoretical exercise; it has practical implications for anyone working with networks or the internet. These concepts influence how resources are designed, accessed, and managed across different systems. For developers, using the correct type of identifier can improve the clarity and efficiency of applications. For network engineers, these distinctions help ensure that resources are organized and referenced in a consistent manner. Even for everyday users, having a basic understanding of these terms can enhance their ability to navigate and interact with digital environments. By recognizing the unique roles of URI, URL, and URN, individuals can develop a deeper appreciation for the underlying structure of the internet and the systems that make it possible.
How Resource Identification Supports Modern Networking Systems
As networks continue to grow in complexity, the need for clear and reliable resource identification becomes even more critical. Every interaction that takes place over a network—whether it involves loading a webpage, accessing a cloud service, or retrieving stored data—depends on the ability to precisely identify the target resource. URI, URL, and URN play a central role in enabling this process by providing structured ways to refer to resources. Without these identification systems, devices would struggle to communicate effectively, leading to confusion and inefficiency. The evolution of networking technologies has only increased the importance of these concepts, as modern systems rely heavily on automation and interoperability. By using standardized identifiers, networks can handle large volumes of requests while maintaining accuracy and consistency.
The Evolution of Resource Identification Concepts
The development of URI, URL, and URN did not happen in isolation. These concepts emerged as part of a broader effort to create a unified system for managing resources across interconnected networks. Early networking systems faced challenges in distinguishing between resources and determining how to access them. As the internet expanded, it became clear that a more structured approach was needed to handle the growing number of resources. This led to the introduction of standardized identifiers that could be universally understood and applied. Over time, these standards have been refined to accommodate new technologies and use cases, ensuring that they remain relevant in an ever-changing digital landscape.
How URIs Provide Flexibility in Identification
One of the most important advantages of URIs is their flexibility. Because a URI is not limited to a specific type of resource or method of access, it can be used in a wide variety of contexts. This flexibility allows developers and network architects to design systems that can adapt to different requirements without being constrained by rigid structures. For example, a URI can represent a physical file stored on a server, a virtual resource generated dynamically, or even an abstract concept within an application. This broad applicability makes URIs a powerful tool for organizing and managing resources in complex environments.
Understanding the Role of Schemes in URIs and URLs
A key component of both URIs and URLs is the scheme, which appears at the beginning of the identifier. The scheme indicates the protocol or method used to interact with the resource. This element is particularly important in URLs, as it defines how the resource should be accessed. Different schemes correspond to different types of services, such as web browsing, file transfer, or email communication. By specifying the scheme, a URL provides clear instructions to the system on how to handle the request. In contrast, while URIs may also include schemes, their primary focus remains on identification rather than access.
The Importance of Protocols in Resource Access
Protocols are the backbone of communication in networking, and they play a crucial role in how URLs function. When a user enters a URL into a browser or application, the protocol specified in the scheme determines how the request is transmitted and processed. This ensures that the system can establish a connection with the appropriate server and retrieve the desired resource. Different protocols are designed for different purposes, each with its own set of rules and capabilities. By incorporating protocols into URLs, networks can support a wide range of interactions while maintaining a consistent approach to resource access.
How URLs Enable Direct Interaction with Resources
Unlike URNs, which focus solely on naming, URLs are designed for direct interaction with resources. This means that a URL not only identifies a resource but also provides all the information needed to locate and retrieve it. This functionality is what makes URLs so essential for everyday internet use. Whether you are browsing websites, downloading files, or accessing online services, URLs serve as the primary means of connecting to resources. Their ability to combine identification and access into a single string of characters simplifies the process of interacting with networked systems.
The Persistence Advantage of URNs
While URLs are highly practical for accessing resources, they can be affected by changes in location. If a resource is moved or its address is updated, the corresponding URL may no longer work. This is where URNs offer a significant advantage. Because URNs are designed to provide persistent identifiers, they remain valid even if the resource’s location changes. This persistence is particularly valuable in scenarios where long-term referencing is required, such as in digital archives, libraries, or large-scale information systems. By separating identification from location, URNs ensure that resources can be consistently referenced over time.
Namespaces and Their Role in URNs
To achieve global uniqueness, URNs rely on namespaces, which are structured systems for organizing identifiers. A namespace defines the rules and conventions for creating unique names within a specific domain. By using namespaces, URNs can avoid conflicts and ensure that each identifier corresponds to a single resource. These namespaces are often managed by organizations or standards bodies that oversee the assignment of identifiers. This structured approach helps maintain the integrity of the identification system and ensures that URNs remain reliable and consistent across different environments.
Comparing Real-World Applications of URLs and URNs
In practical terms, URLs and URNs serve different but complementary roles. URLs are widely used for accessing resources in real time, making them essential for web browsing and online services. URNs, on the other hand, are more commonly used in systems that require stable and long-lasting identifiers. For example, digital libraries may use URNs to catalog and reference documents, ensuring that they can be identified even if their storage locations change. By understanding these differences, it becomes easier to choose the appropriate type of identifier for a given application.
How Misunderstandings Arise Between These Terms
Despite their distinct roles, URI, URL, and URN are often misunderstood or used interchangeably. This confusion can be attributed to their overlapping definitions and the fact that URLs are the most visible and commonly used type of URI. As a result, many people use the term URL to refer to any kind of resource identifier, even when a more general term like URI would be more accurate. This tendency can lead to misunderstandings, particularly in technical discussions where precision is important. By recognizing the differences between these terms, individuals can communicate more effectively and avoid potential confusion.
The Impact of Resource Identification on Web Architecture
The structure of the web itself is heavily influenced by the principles of resource identification. Every component of a web application, from individual pages to backend services, relies on identifiers to function correctly. URIs provide the foundation for this system, enabling resources to be linked, referenced, and accessed in a consistent manner. URLs build on this foundation by facilitating direct interaction with resources, while URNs offer a stable means of identification for long-term use. Together, these concepts form the backbone of web architecture, supporting the seamless operation of modern internet systems.
Why Developers Must Understand These Concepts
For developers and IT professionals, a clear understanding of URI, URL, and URN is essential. These concepts influence how applications are designed, how resources are managed, and how users interact with systems. By using the correct type of identifier, developers can create more efficient and maintainable applications. Additionally, understanding these distinctions can help prevent errors and improve communication within development teams. As technology continues to evolve, the importance of these foundational concepts remains constant, making them a critical area of knowledge for anyone working in the field of networking or software development.
Deeper Insight into How Identifiers Work Behind the Scenes
When a resource identifier is used in a network environment, there is a complex process happening behind the scenes that most users never see. Whether it is a URI, URL, or URN, the identifier must be interpreted by software systems in a precise and predictable way. This interpretation involves parsing the string into its components, understanding the scheme, and determining what action should be taken. For URLs, this often includes initiating a connection to a server, sending a request, and waiting for a response. For URNs, the process may involve looking up the identifier in a registry or database to find associated information. These operations highlight the importance of having a well-defined structure for identifiers, as even a small inconsistency can lead to errors or failed requests.
Parsing and Interpreting Resource Identifiers
Before any resource can be accessed or referenced, the system must break down the identifier into meaningful parts. This process, known as parsing, allows software to understand the structure of the identifier and determine how to handle it. For example, when a URL is entered into a browser, the application separates the scheme, domain, path, and any additional parameters. Each part plays a specific role in guiding the request. The scheme tells the system which protocol to use, while the domain identifies the server that hosts the resource. The path and parameters provide further details about the exact resource being requested. This structured approach ensures that identifiers can be interpreted consistently across different systems and platforms.
The Role of Resolution in Resource Access
Resolution is another critical concept in understanding how resource identifiers function. It refers to the process of converting an identifier into a form that can be used to locate or retrieve the resource. In the case of URLs, resolution often involves translating a domain name into an IP address through a naming system, followed by establishing a connection to the corresponding server. For URNs, resolution may involve querying a database or registry to find information about the resource. This process highlights the difference between identifiers that provide direct access and those that require additional steps to locate the resource. By separating identification from resolution, networking systems can achieve greater flexibility and scalability.
How Hierarchical Structure Improves Organization
Many resource identifiers, particularly URLs, use a hierarchical structure to organize information. This structure allows resources to be arranged in a logical and easily navigable manner. For example, a URL may include multiple levels of directories, each representing a different category or grouping of resources. This hierarchy not only makes it easier for users to understand the organization of a website but also helps systems manage and retrieve resources more efficiently. By following a consistent structure, identifiers can convey a significant amount of information in a compact format, reducing the need for additional context or explanation.
The Significance of Human-Readable Identifiers
One of the reasons URLs are so widely used is their human-readable nature. Unlike many other types of identifiers, URLs are designed to be easily understood and remembered by people. This makes them particularly useful for sharing and accessing resources in everyday situations. While URNs and some URIs may be more abstract or complex, URLs strike a balance between technical precision and usability. This emphasis on readability has played a key role in the growth of the internet, as it allows users to interact with resources without needing extensive technical knowledge. However, this convenience also introduces challenges, such as the need to ensure that identifiers remain accurate and up to date.
Handling Changes in Resource Location
One of the challenges associated with URLs is that they are tied to the location of a resource. If the resource is moved or reorganized, the URL may no longer point to the correct location. This can result in broken links and inaccessible content. To address this issue, various strategies have been developed, such as redirection and aliasing, which allow systems to guide users to the new location of a resource. Despite these solutions, the problem highlights the limitations of using location-based identifiers. In contrast, URNs avoid this issue by providing a stable identifier that remains unchanged regardless of where the resource is stored.
The Concept of Persistence in Digital Systems
Persistence is a key consideration in the design of resource identifiers. In many applications, it is important to ensure that references to resources remain valid over time. This is particularly true in fields such as digital archiving, academic publishing, and data management, where resources may need to be accessed long after they were created. URNs are specifically designed to address this need by providing identifiers that do not depend on location. By separating identification from access, URNs enable systems to maintain consistent references even as resources evolve or move. This focus on persistence makes them an essential tool for long-term information management.
Security Considerations in Resource Identification
Security is another important aspect of resource identification. When accessing resources عبر a network, it is essential to ensure that the communication is secure and that the resource being accessed is authentic. URLs often include protocols that support secure communication, helping to protect data from interception or tampering. Additionally, systems may use various mechanisms to verify the identity of resources and prevent unauthorized access. While URIs and URNs are primarily focused on identification, they can also play a role in security by providing consistent and reliable references that can be validated by the system.
Interoperability Across Different Systems
One of the strengths of URI-based identification is its ability to support interoperability between different systems. Because URIs follow standardized formats, they can be used across a wide range of platforms and technologies. This allows systems developed by different organizations to communicate and share resources without compatibility issues. URLs, as a subset of URIs, are particularly important in this context, as they enable seamless interaction between web browsers, servers, and applications. URNs also contribute to interoperability by providing stable identifiers that can be recognized and used across different environments. This compatibility is essential for the functioning of modern networks, which rely on the integration of diverse systems and technologies.
Common Challenges in Using Resource Identifiers
Despite their advantages, resource identifiers are not without challenges. One common issue is the potential for ambiguity or duplication, particularly in systems that do not enforce strict naming conventions. This can lead to confusion and errors when attempting to access or reference resources. Another challenge is maintaining the accuracy and relevance of identifiers over time, especially in dynamic environments where resources are frequently updated or relocated. Addressing these challenges requires careful planning and adherence to best practices, such as using consistent naming schemes and implementing mechanisms for handling changes in resource location.
The Future of Resource Identification in Networking
As technology continues to evolve, the role of resource identifiers is likely to expand and adapt to new requirements. Emerging technologies, such as distributed systems and advanced data management platforms, may introduce new approaches to identification and access. However, the fundamental principles behind URI, URL, and URN are expected to remain relevant, as they provide a solid foundation for organizing and managing resources. By building on these concepts, future systems can continue to improve efficiency, scalability, and reliability in network communication. Understanding these identifiers today not only helps in current applications but also prepares individuals for the innovations that lie ahead in the field of networking.
How Resource Identification Shapes User Experience on the Web
The way resources are identified has a direct impact on how users experience the internet. Every time a user clicks a link, types an address, or interacts with an application, resource identifiers are working in the background to connect them with the desired content. URLs, in particular, are designed to be intuitive and easy to use, allowing users to navigate complex systems with minimal effort. A well-structured identifier can improve usability by making it clear what kind of resource is being accessed and how it is organized. On the other hand, poorly designed identifiers can create confusion, making it harder for users to find what they need. This connection between identification and user experience highlights the importance of thoughtful design in networking systems.
Designing Clear and Meaningful Identifiers
Creating effective resource identifiers requires careful consideration of both technical and human factors. From a technical perspective, identifiers must follow standardized formats to ensure compatibility across systems. From a user perspective, they should be simple, descriptive, and easy to interpret. This balance is particularly important for URLs, which are often visible to end users. A clear and meaningful URL can provide valuable context about the resource, such as its purpose or category. This not only improves navigation but also enhances trust, as users are more likely to interact with identifiers that appear organized and transparent.
The Role of Consistency in Resource Naming
Consistency is a key principle in the design of resource identifiers. When identifiers follow a predictable pattern, it becomes easier for both users and systems to understand and manage them. Consistent naming conventions can simplify navigation, reduce errors, and improve the overall efficiency of a network. For example, using a uniform structure for URLs across a website can help users anticipate where certain types of content are located. Similarly, consistent use of URNs within a system can ensure that resources are uniquely and reliably identified. By maintaining consistency, organizations can create more organized and user-friendly environments.
Balancing Flexibility and Control in Identifier Systems
While consistency is important, identifier systems must also be flexible enough to accommodate change. Networks are dynamic environments where resources are constantly being added, updated, or removed. This requires a balance between maintaining a stable structure and allowing for growth and adaptation. URIs provide this flexibility by serving as a broad framework that can support different types of identifiers. URLs offer control over how resources are accessed, while URNs provide stability through persistent naming. Together, these elements create a system that can evolve without losing its integrity.
Managing Large-Scale Resource Collections
In large-scale systems, such as enterprise networks or global platforms, managing resource identifiers becomes a complex task. Thousands or even millions of resources may need to be organized and accessed efficiently. In such environments, the choice of identifier plays a crucial role in ensuring scalability. URLs are often used for direct access, enabling users and applications to retrieve resources quickly. URNs, on the other hand, are valuable for maintaining consistent references across large datasets. By combining different types of identifiers, organizations can create systems that are both efficient and resilient.
The Importance of Documentation and Governance
Effective use of resource identifiers requires proper documentation and governance. Organizations must establish clear guidelines for creating, managing, and maintaining identifiers to prevent inconsistencies and conflicts. This includes defining naming conventions, assigning responsibilities, and implementing processes for handling changes. Without proper governance, identifier systems can become disorganized, leading to errors and inefficiencies. By documenting best practices and enforcing standards, organizations can ensure that their resource identification systems remain reliable and effective over time.
How Resource Identifiers Support Integration and APIs
Modern applications often rely on integration with other systems, and resource identifiers play a central role in this process. Application programming interfaces use identifiers to specify the resources that can be accessed or manipulated. URLs are commonly used in these interfaces to define endpoints, allowing applications to communicate and exchange data. The use of standardized identifiers ensures that different systems can interact seamlessly, even if they are built using different technologies. This ability to integrate and share resources is a cornerstone of modern software development, enabling the creation of complex and interconnected applications.
Common Misconceptions and Clarifications
Despite their importance, resource identifiers are often misunderstood. One common misconception is that all web addresses are simply URLs, without recognizing their relationship to URIs. Another misunderstanding is the assumption that URNs are rarely used or unnecessary. In reality, each type of identifier serves a specific purpose and contributes to the overall functionality of networking systems. Clarifying these misconceptions is essential for developing a deeper understanding of how resources are managed and accessed. By using the correct terminology and recognizing the distinctions between these concepts, individuals can communicate more effectively and make better decisions in their work.
The Long-Term Value of Understanding These Concepts
Gaining a clear understanding of URI, URL, and URN provides long-term benefits for anyone involved in technology. These concepts form the foundation of resource identification, influencing everything from web development to data management. By mastering these ideas, individuals can improve their ability to design, analyze, and troubleshoot network systems. This knowledge also supports better decision-making when choosing the appropriate type of identifier for a given situation. As technology continues to evolve, the principles behind resource identification will remain relevant, making them a valuable area of study for both beginners and experienced professionals.
Why Precision in Terminology Matters in Networking
In technical fields like networking, precision in terminology is not just a matter of preference but a necessity for clear communication and accurate system design. Using URI, URL, and URN interchangeably without understanding their distinctions can lead to confusion, especially when designing or troubleshooting systems. Each term carries a specific meaning that influences how resources are interpreted, accessed, or maintained. For instance, treating a URL as a generic identifier without acknowledging its access capabilities can result in design flaws or miscommunication between systems and developers. Similarly, overlooking the persistent nature of URNs may lead to improper handling of long-term references in databases or documentation systems. Clear and correct usage of these terms ensures that both human understanding and machine processing remain aligned, reducing errors and improving overall system reliability.
Final Conclusion
URI, URL, and URN are closely related concepts that work together to enable efficient resource identification in networking systems. A URI serves as the broadest category, providing a general way to identify resources. Within this category, URLs offer a practical means of locating and accessing resources by combining identification with an access method. URNs focus on providing stable and globally unique names that remain consistent over time, regardless of changes in location. Understanding these distinctions is essential for navigating and working within modern network environments. By recognizing the unique roles of each type of identifier, it becomes possible to use them more effectively and appreciate the structure that underpins the digital world.