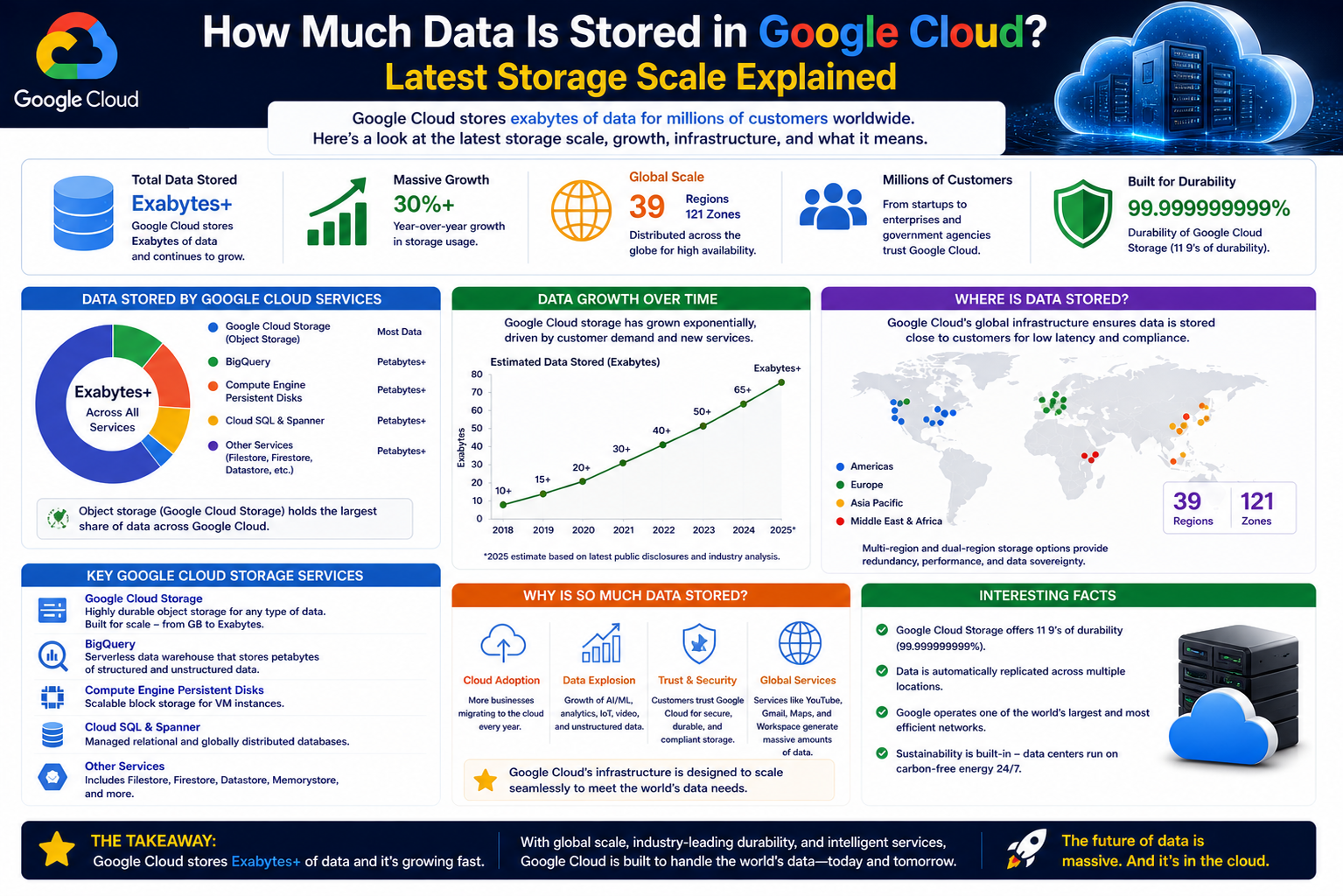
When discussing how much data is stored in Google Cloud, it is important to first understand the scale and complexity behind modern cloud storage systems. Google Cloud is not just a simple storage drive; it is a vast global infrastructure designed to handle enormous volumes of digital information generated every second. This includes everything from personal photos and emails to enterprise databases, video streaming content, application data, and machine learning models. The total amount of data stored in such a system is not fixed and continuously grows as more users and businesses rely on cloud-based services.
At its core, Google Cloud Storage acts as the backbone for many widely used services. Every time a user uploads a file, sends an email, watches a video, or saves a document online, that information is stored in distributed data centers across multiple regions. These systems are engineered to replicate and balance data automatically, ensuring reliability and speed. Because of this distributed nature, the total storage capacity is not limited by a single machine or server but rather by a massive network of interconnected systems that can expand continuously.
What Google Cloud Storage Actually Means
Google Cloud Storage refers to a highly scalable data storage service built on Google’s global infrastructure. It allows users and organizations to store different types of digital content, including structured and unstructured data. This can range from simple text files to complex datasets used in artificial intelligence and big data analytics. Unlike traditional storage methods that rely on physical hardware limitations, cloud storage operates through virtualized environments, making it far more flexible and expandable.
Behind the scenes, this storage system supports several well-known Google products. Services like email platforms, document editing tools, cloud backups, and media storage applications all depend on this same underlying architecture. When users upload or create content, it is distributed across multiple secure servers rather than being stored in one physical location. This approach improves performance, reduces the risk of data loss, and allows seamless access from anywhere in the world.
The design of Google Cloud Storage also ensures redundancy. This means that multiple copies of data are stored in different locations so that even if one system fails, the data remains accessible. This level of reliability is one of the reasons cloud storage has become essential for both personal and enterprise use.
How Data Is Distributed Across Global Infrastructure
The storage system behind Google Cloud does not function like a single warehouse of information. Instead, it operates as a globally distributed network of data centers. These data centers are located in various regions around the world and work together to store and manage user data efficiently. When a file is uploaded, it is automatically divided, replicated, and stored in multiple locations depending on performance and reliability requirements.
This distribution strategy ensures that users can access their data quickly, regardless of where they are located. If a user in one region requests a file, the system delivers it from the nearest available server, reducing latency and improving speed. At the same time, backup copies are maintained in other regions to protect against data loss caused by hardware failure or unexpected disruptions.
This architecture also allows Google Cloud to scale continuously. As more data is added, additional storage resources can be integrated into the system without affecting existing services. This ability to expand dynamically is one of the key reasons why the total amount of data stored in Google Cloud is extremely large and constantly increasing.
Types of Data Stored Within Google Cloud Systems
The data stored in Google Cloud is extremely diverse and comes from millions of different sources. On a personal level, users store emails, documents, photos, videos, and application backups. These everyday digital assets account for a significant portion of the total storage usage. However, this is only a small part of the overall system.
Businesses and organizations contribute an even larger volume of data. Companies use cloud storage for databases, customer records, financial transactions, software applications, and internal communication systems. In addition, developers use cloud infrastructure to run applications, host websites, and manage backend systems that generate continuous streams of data.
Another major contributor is artificial intelligence and machine learning. These technologies require massive datasets for training and analysis. The processing and storage of such data significantly increases overall storage demand. Streaming services, gaming platforms, and social media applications also rely heavily on cloud storage to manage multimedia content and user activity logs.
Together, these different categories create an enormous and ever-expanding ecosystem of stored information.
The Role of Consumer and Business Storage Plans
Google Cloud storage capacity is also influenced by the structure of its consumer and business offerings. On the consumer side, users are provided with a base level of free storage, which is shared across multiple services such as email, photos, and file storage. When users require more space, they can upgrade to subscription-based plans that offer significantly larger storage capacities.
These plans are designed to scale according to user needs, with higher tiers providing additional storage and advanced features. Many users store large volumes of high-resolution media files, backups, and personal archives, which contributes to increasing overall data usage.
On the business side, organizations use cloud-based productivity and collaboration systems that include dedicated storage allocations per user. These enterprise environments often handle sensitive business data, large project files, and collaborative documents shared across teams. Since businesses typically operate at a larger scale than individual users, their storage consumption grows rapidly and consistently over time.
This combination of personal and business usage creates a continuously expanding demand for cloud storage capacity.
Estimating the Scale of Stored Data Globally
Although exact figures are not publicly disclosed, it is widely understood that the total amount of data stored in Google Cloud reaches an extremely large scale. Estimates based on user numbers and storage allocations suggest that the system handles data measured in multiple exabytes or more. To understand this scale, it helps to break down the terminology.
A single terabyte represents a large amount of personal data, such as thousands of high-quality photos or hundreds of hours of video. When multiplied by thousands, millions, or billions of users, this quickly expands into petabytes and exabytes of information. Given the global user base and enterprise adoption, the cumulative storage demand becomes enormous.
Even conservative estimates indicate that the minimum stored data must account for billions of active users, each contributing at least a baseline amount of storage usage. When business accounts, premium storage plans, and high-volume applications are included, the total grows significantly beyond basic calculations.
This makes Google Cloud one of the largest data storage systems in existence, with capacity that continues to grow as digital activity increases worldwide.
Growth of Data in Google Cloud Over Time
The amount of data stored in Google Cloud has been increasing at a rapid and continuous pace due to global digital transformation. As more individuals, businesses, and developers adopt cloud-based solutions, the demand for scalable storage has grown significantly. This growth is not just linear but exponential, driven by the expansion of internet usage, mobile applications, and digital services that generate massive volumes of data every second.
Over time, traditional storage systems have become insufficient for modern requirements. Organizations have shifted from local servers to cloud infrastructure because it offers virtually unlimited scalability. Google Cloud benefits from this shift as it continuously absorbs new data from millions of active users and enterprise systems. Each new file uploaded, email sent, video streamed, or application log generated contributes to this ever-expanding ecosystem.
One of the key reasons for this growth is the increasing reliance on digital ecosystems. Businesses are no longer storing isolated files; instead, they are building entire operational systems in the cloud. These systems continuously generate and store transactional data, analytics records, customer interactions, and system logs. As digital transformation accelerates, the volume of stored data increases proportionally.
How User Activity Drives Cloud Storage Expansion
Every interaction within Google’s ecosystem contributes to cloud storage growth. Simple actions such as sending an email, uploading a photo, or editing a document generate data that must be stored, replicated, and indexed. When multiplied by billions of users worldwide, this creates an enormous flow of continuously generated information.
Email services alone are a major contributor. Each message, attachment, and metadata entry is stored and often replicated for reliability. Similarly, cloud-based photo and video storage systems handle high-resolution media files that consume significant storage space. As camera technology improves and file sizes increase, the storage requirements grow even further.
Another major factor is application usage. Many mobile and web applications rely on cloud backends to store user preferences, session data, and activity logs. These applications run continuously in the background, generating data even when users are not actively interacting with them. This constant stream of information adds to the overall storage load.
Streaming platforms and content delivery systems also play a significant role. Every time a video is streamed or buffered, temporary and permanent data is generated. This includes usage statistics, quality metrics, and caching data that improves performance for future users.
Enterprise Systems and Large-Scale Data Contribution
While individual users contribute a large amount of data, enterprise systems are responsible for an even greater share of cloud storage consumption. Businesses use Google Cloud for a wide range of purposes, including data analytics, application hosting, customer management systems, and artificial intelligence processing.
Large organizations often generate continuous streams of structured and unstructured data. This includes financial transactions, customer interactions, inventory updates, and operational logs. These datasets are often stored for long-term analysis and compliance purposes, significantly increasing total storage requirements.
Many enterprises also operate global applications that serve millions of users. These applications rely on cloud infrastructure to manage real-time data processing and storage. As usage scales, the amount of stored information increases proportionally, requiring advanced storage optimization techniques such as data compression, partitioning, and automated lifecycle management.
Additionally, companies working in fields such as healthcare, finance, and e-commerce generate highly detailed datasets that must be securely stored and frequently accessed. This adds another layer of complexity and volume to the overall cloud storage ecosystem.
The Role of Media Content in Storage Growth
Media content is one of the largest contributors to cloud storage usage. High-resolution images, 4K and 8K videos, audio files, and live streaming content require significant storage capacity. As digital media consumption continues to rise globally, the demand for storage increases at the same pace.
Modern smartphones and cameras produce extremely large files compared to earlier generations of devices. Users frequently upload photos and videos directly to cloud storage for backup and sharing purposes. Over time, these personal media collections accumulate into large datasets that are stored permanently.
Video platforms and content creators also contribute heavily to storage expansion. Every uploaded video is stored in multiple formats and resolutions to support different devices and network conditions. This requires additional storage space for encoding, replication, and distribution.
Live streaming services generate even more complex data patterns. Streams are often recorded, analyzed, and stored for later playback or analytics. This adds both temporary and long-term storage demands, further increasing the total volume of data managed by cloud systems.
Data Replication and Redundancy at Scale
One of the reasons Google Cloud stores such a large amount of data is its replication strategy. To ensure reliability and fault tolerance, data is often stored in multiple copies across different geographic regions. This means that a single file may exist in several locations simultaneously.
Replication ensures that data remains accessible even if one data center experiences failure or disruption. It also improves access speed by allowing users to retrieve data from the nearest available server. However, this redundancy also increases total storage consumption, as multiple copies of the same data are maintained.
In addition to replication, cloud systems also use backup mechanisms for disaster recovery. These backups are stored separately from active data systems and may be retained for long periods. While this enhances security and reliability, it further contributes to overall storage volume.
The combination of replication, backup, and distributed architecture means that actual physical storage usage is significantly higher than the raw user-uploaded data alone.
Impact of Artificial Intelligence and Machine Learning Data
Artificial intelligence and machine learning systems are another major factor driving cloud storage growth. These technologies require massive datasets for training, testing, and optimization. The data used in AI systems often includes images, text, audio, and structured numerical data.
Training large-scale AI models involves processing enormous volumes of information repeatedly. Each iteration generates additional metadata, logs, and intermediate results that must be stored. As AI systems become more advanced, the size of datasets required for training continues to increase.
In addition to training data, AI systems also generate inference data during real-world usage. This includes user interactions, predictions, and system responses that are stored for performance improvement and auditing purposes.
Machine learning pipelines also rely heavily on data versioning. Multiple versions of datasets are often stored to track changes and improve model accuracy over time. This adds another layer of storage consumption within the cloud ecosystem.
Continuous Expansion of Global Cloud Infrastructure
Google Cloud continues to expand its infrastructure to accommodate growing data demands. New data centers are regularly added in different regions to improve performance and scalability. Each new facility increases the overall storage capacity of the system and allows for more efficient data distribution.
This expansion is driven by increasing global demand for digital services. As more countries adopt cloud technologies, the need for localized storage and faster access becomes critical. To meet these requirements, cloud infrastructure must scale both vertically and horizontally.
Vertical scaling involves increasing the capacity of existing systems, while horizontal scaling involves adding new systems to the network. Google Cloud uses both strategies to ensure that storage capabilities grow alongside user demand.
This continuous expansion means that the total amount of stored data is not static. It increases every day as new users join the platform and existing users generate more content.
How Google Cloud Handles Massive Data Growth
As the volume of data stored in Google Cloud continues to expand, the system relies on advanced engineering techniques to manage and organize information efficiently. The infrastructure is designed to handle extremely large workloads without slowing down or becoming unstable. This is achieved through distributed computing, automated balancing systems, and intelligent data routing mechanisms that ensure smooth performance even under heavy usage.
At a technical level, data is not stored in a single location but is spread across multiple interconnected systems. These systems constantly communicate with each other to ensure consistency and availability. When data is requested, the system determines the most efficient path to retrieve it, often selecting the nearest or least congested server. This reduces delays and ensures users experience fast and reliable access regardless of where they are located.
Another important aspect of managing large-scale data growth is automation. Many processes within the cloud infrastructure are handled automatically, including data replication, load balancing, error correction, and resource allocation. This reduces the need for manual intervention and allows the system to scale efficiently as demand increases.
Data Storage Architecture and Distribution Strategy
The architecture behind Google Cloud storage is built on a layered and modular design. This means that different types of data are handled by specialized systems depending on their size, usage pattern, and importance. Frequently accessed data is stored in high-speed systems optimized for performance, while less frequently accessed data is moved to lower-cost storage tiers.
This tiered storage approach helps optimize both cost and efficiency. It ensures that critical data is always available quickly while long-term archival data is stored in a more resource-efficient manner. As data usage patterns change over time, the system automatically moves data between different storage tiers to maintain balance.
The distribution strategy also plays a key role in scalability. Data is broken into smaller chunks and distributed across multiple storage nodes. These nodes work together to reconstruct the data when it is requested. This approach not only improves performance but also enhances reliability, as data remains accessible even if some nodes experience issues.
Additionally, metadata systems track the location and status of every piece of stored data. This allows the system to quickly locate and retrieve information without searching through entire datasets. The combination of distributed storage and metadata indexing is essential for handling billions of files efficiently.
Scalability Through Virtualization and Automation
One of the most powerful features of Google Cloud storage is its ability to scale dynamically through virtualization. Virtualization allows physical hardware resources to be divided into multiple virtual environments, each capable of handling independent workloads. This means storage capacity can be expanded without requiring users to interact with physical infrastructure.
When demand increases, additional virtual resources can be allocated automatically. This process is seamless and happens behind the scenes without affecting user experience. As a result, the system can handle sudden spikes in traffic or data uploads without performance degradation.
Automation further enhances scalability by managing routine tasks such as data balancing, system monitoring, and fault detection. If a storage node becomes overloaded, the system automatically redistributes data to maintain efficiency. If a failure occurs, backup systems activate immediately to ensure continuity.
This combination of virtualization and automation allows Google Cloud to grow continuously without interruption. It ensures that storage capacity can keep pace with global data generation, which increases every day across industries and applications.
The Role of Data Compression and Optimization
To manage the enormous volume of stored data, Google Cloud uses advanced compression and optimization techniques. Data compression reduces the physical size of files without losing important information, allowing more data to be stored in the same amount of space. This is especially useful for large-scale systems where efficiency is critical.
Different compression methods are applied depending on the type of data. Text files, images, videos, and structured datasets all require different optimization strategies. For example, media files may be compressed using lossy or lossless techniques depending on quality requirements, while structured data is often optimized for fast retrieval rather than size reduction alone.
In addition to compression, deduplication techniques are used to eliminate redundant data. If multiple copies of identical information exist, the system stores only one version and references it where needed. This significantly reduces unnecessary storage consumption and improves efficiency.
Indexing and caching also play important roles in optimization. Frequently accessed data is stored in high-speed cache systems, allowing faster retrieval and reducing load on primary storage systems. Together, these optimization methods ensure that even massive amounts of data can be managed effectively.
Security and Data Integrity in Large-Scale Storage
As the amount of stored data grows, ensuring security and integrity becomes increasingly important. Google Cloud employs multiple layers of security to protect data from unauthorized access, corruption, and loss. These security measures operate at both physical and digital levels.
Data is encrypted both during transfer and while stored. This ensures that even if data is intercepted, it cannot be read without proper authorization. Access control systems determine who can view or modify specific data, ensuring strict permissions are enforced across all levels.
Integrity checks are continuously performed to ensure that data remains accurate and uncorrupted. These checks compare stored data against original values to detect any inconsistencies. If corruption is detected, backup copies are used to restore the original information.
In addition to encryption and integrity checks, monitoring systems continuously track activity across the cloud infrastructure. Suspicious behavior is flagged automatically, allowing rapid response to potential threats. These security systems are essential for maintaining trust in a platform that stores enormous volumes of sensitive data.
Impact of Global Internet Usage on Data Volume
The growth of Google Cloud storage is closely tied to global internet usage patterns. As more people come online and digital services become more integrated into daily life, the amount of data generated increases significantly. Activities such as social media interaction, online shopping, video streaming, and remote work all contribute to this growth.
Mobile devices have played a particularly important role in accelerating data generation. Smartphones continuously produce and upload data in the form of photos, videos, app usage logs, and location information. This constant flow of information adds to the overall storage demand in cloud systems.
The rise of remote work and digital collaboration tools has also contributed to increased cloud usage. Businesses now rely heavily on cloud platforms to store documents, conduct meetings, and manage workflows. This shift has resulted in a significant increase in enterprise-level data storage.
As internet usage continues to expand globally, especially in developing regions, the amount of data stored in cloud systems is expected to keep growing at a rapid pace.
Long-Term Expansion of Cloud Storage Ecosystems
The cloud storage ecosystem is continuously evolving to support increasing data demands. New technologies, infrastructure improvements, and optimization techniques are regularly introduced to enhance performance and scalability. This ensures that the system can handle future growth without limitations.
As digital transformation accelerates, more industries are moving their operations to cloud-based platforms. This includes sectors such as healthcare, education, finance, entertainment, and manufacturing. Each of these industries generates large volumes of data that must be securely stored and efficiently managed.
The long-term expansion of cloud storage is also influenced by emerging technologies such as artificial intelligence, the Internet of Things, and advanced analytics. These technologies generate continuous streams of data that require real-time processing and long-term storage.
As a result, the total amount of data stored in Google Cloud is not only large but constantly expanding, driven by both technological advancement and global digital adoption.
Future Growth of Data in Google Cloud
The future of data stored in Google Cloud is expected to expand at an even faster rate as digital technologies continue to evolve. With increasing reliance on cloud-based systems across personal, business, and industrial sectors, the total volume of stored information will continue to grow significantly. This growth is largely driven by the rising demand for real-time services, artificial intelligence applications, and global connectivity that depends on fast and reliable data access.
As more devices become connected to the internet, the amount of data generated every second increases dramatically. Smart devices, wearable technology, autonomous systems, and IoT-enabled machines all contribute to continuous data streams. These systems do not just store occasional data; they produce constant updates that must be processed, analyzed, and stored in cloud environments. This ongoing cycle ensures that cloud storage requirements will keep expanding for the foreseeable future.
At the same time, advancements in digital content creation are also increasing storage demand. Higher-quality video formats, immersive media experiences, and interactive applications generate significantly larger files than traditional digital content. As users adopt these technologies globally, the storage ecosystem must scale accordingly to support them.
Role of Artificial Intelligence in Future Data Expansion
Artificial intelligence is one of the most influential factors in the future growth of cloud data storage. AI systems require vast datasets for training and continuous improvement, and these datasets are constantly growing in size and complexity. As AI becomes more integrated into everyday applications, the amount of data processed and stored will increase exponentially.
Modern AI models rely on large-scale learning processes that involve analyzing billions of data points. These include text, images, audio, video, and structured datasets. Each training cycle produces additional data that must be stored for validation, optimization, and future reference. This creates a continuous feedback loop where AI development directly contributes to increased storage requirements.
Furthermore, AI-driven services generate real-time data during operation. For example, recommendation systems, voice assistants, and predictive analytics tools all produce and store interaction data. This information is used to improve system accuracy and performance over time, further adding to overall storage volume.
As AI continues to evolve into more advanced systems, including generative models and autonomous decision-making platforms, the demand for scalable and efficient cloud storage will become even more critical.
Expansion of Global Digital Infrastructure
The global expansion of digital infrastructure is another key factor contributing to the growth of cloud storage. More countries are investing in internet connectivity, digital services, and cloud adoption, leading to an increase in data generation and storage needs. As digital access becomes more widespread, billions of new users contribute to the global data ecosystem.
Businesses around the world are rapidly shifting from traditional IT systems to cloud-based environments. This transition allows organizations to operate more efficiently, but it also significantly increases their dependency on cloud storage systems. Enterprise applications, customer databases, analytics platforms, and communication tools all rely heavily on cloud infrastructure.
Educational institutions, healthcare systems, and government services are also adopting cloud technologies at a large scale. These sectors generate sensitive and high-volume data that must be securely stored and efficiently managed. As digital transformation continues globally, the demand for cloud storage capacity will continue to rise.
The expansion of data centers in multiple regions ensures that this growth can be supported effectively. By distributing infrastructure globally, cloud providers can handle increasing workloads while maintaining performance and reliability.
Advancements in Storage Technology and Efficiency
To manage the increasing volume of data, continuous advancements in storage technology are essential. Future improvements in hardware and software systems will play a major role in ensuring that cloud storage remains efficient and scalable. Innovations in data compression, storage density, and retrieval speed will help optimize how information is stored and accessed.
Next-generation storage systems are being designed to handle higher capacities while reducing physical resource consumption. This includes the development of faster storage media, improved memory architectures, and more efficient data management algorithms. These innovations allow cloud systems to store more data without requiring proportional increases in physical infrastructure.
Software optimization also plays a key role in improving efficiency. Intelligent data management systems can automatically categorize, prioritize, and archive data based on usage patterns. This ensures that frequently accessed data remains easily available while less important data is stored in a cost-effective manner.
As storage technology continues to evolve, the ability to manage massive datasets will improve significantly, enabling even larger volumes of data to be stored in cloud environments.
Sustainability and Energy Efficiency in Cloud Storage
As data storage continues to grow, sustainability has become an increasingly important consideration. Large-scale data centers consume significant amounts of energy, and managing this consumption efficiently is essential for long-term sustainability. Cloud providers are investing heavily in energy-efficient technologies and renewable energy sources to reduce environmental impact.
Modern data centers are designed to optimize power usage and cooling efficiency. Advanced cooling systems, hardware optimization, and intelligent workload distribution help reduce energy consumption while maintaining performance. These improvements ensure that even as data volume increases, energy usage remains as efficient as possible.
Renewable energy integration is also becoming more common in cloud infrastructure. Solar, wind, and other sustainable energy sources are being used to power data centers, reducing reliance on traditional energy grids. This shift supports both environmental goals and long-term operational stability.
Sustainability efforts are closely linked to efficiency improvements in storage systems. By reducing redundancy where possible and optimizing data management processes, cloud systems can store more data while using fewer resources.
Long-Term Outlook of Cloud Data Storage Growth
Looking ahead, the long-term outlook for cloud data storage suggests continuous and significant expansion. As digital ecosystems become more deeply integrated into everyday life, the amount of data generated will keep increasing. This includes not only personal and business data but also machine-generated information from automated systems and intelligent devices.
The growth of emerging technologies such as augmented reality, virtual reality, and advanced robotics will further accelerate data generation. These technologies rely on real-time data processing and high-capacity storage systems to function effectively. As adoption increases, so will the demand for scalable cloud infrastructure.
In addition, global connectivity improvements will bring more users online, especially in regions that are currently expanding their digital infrastructure. This will introduce new sources of data and further increase global storage requirements.
Despite the massive scale of current cloud storage systems, there is no indication that growth will slow down. Instead, it is expected to accelerate as technology becomes more data-intensive and interconnected.
Data Governance and Management in Google Cloud
Managing such an enormous volume of data requires strict governance systems that control how information is stored, accessed, and used. In Google Cloud, data governance is not just about storage; it is about ensuring that data remains organized, compliant, secure, and usable across different services and regions. As the scale of data increases, governance becomes even more important because without proper control, large datasets can become difficult to manage and analyze effectively.
Data governance frameworks define rules for how data is categorized and stored. This includes assigning metadata, defining ownership, and establishing access permissions. Every piece of data stored in the cloud is associated with specific attributes that describe its purpose, origin, and usage rights. These attributes help systems automatically manage data lifecycles, ensuring that information is stored in the appropriate location and format.
One of the most important aspects of governance is data lifecycle management. Not all data is equally important at all times. Some data is frequently accessed, while other data becomes less relevant over time. Cloud systems automatically move data between different storage tiers based on usage patterns. Frequently used data is kept in high-performance storage, while older or less accessed data is moved to cost-efficient archival systems.
This automated lifecycle approach helps reduce storage costs while maintaining accessibility. It also ensures that unnecessary data does not consume high-performance resources, allowing the system to remain efficient even as total data volume increases.
Data Accessibility and Global User Experience
One of the key goals of cloud storage systems is to ensure that data remains easily accessible regardless of user location. Google Cloud achieves this through a globally distributed infrastructure that brings data closer to users. Instead of accessing a single centralized database, users interact with the nearest available data center, which significantly improves response time and performance.
This global accessibility is essential for modern applications that serve users across different continents. Whether a user is accessing a document, streaming content, or running an application, the system ensures that data is delivered quickly and reliably. This is made possible through intelligent routing systems that automatically select the most efficient path for data retrieval.
Caching systems also play a major role in improving accessibility. Frequently requested data is temporarily stored closer to the user, reducing the need to retrieve it from distant servers. This reduces latency and improves overall system performance, especially during high traffic periods.
The combination of global distribution and caching ensures that even as data volume increases, user experience remains smooth and consistent. This is a critical factor in maintaining the scalability of cloud systems as demand continues to grow worldwide.
Data Processing at Scale Within Cloud Systems
Beyond storage, Google Cloud also processes massive amounts of data continuously. This processing includes analyzing, transforming, indexing, and organizing data to make it usable for applications and services. At such a large scale, traditional processing methods are not sufficient, so cloud systems rely on distributed computing frameworks.
Distributed processing allows large datasets to be broken into smaller chunks and processed simultaneously across multiple machines. This parallel approach significantly increases speed and efficiency. Once processed, the results are combined and stored back into the system for further use or analysis.
This type of processing is essential for services such as search engines, recommendation systems, and real-time analytics platforms. These systems rely on continuously updated data to function effectively. As a result, data is not only stored but actively processed and refined within the cloud environment.
Batch processing and real-time processing are both used depending on the nature of the task. Batch processing handles large volumes of data at scheduled intervals, while real-time processing handles continuous streams of information. Together, these methods ensure that cloud systems can handle both historical and live data efficiently.
Role of Networking in Large-Scale Cloud Storage
Networking infrastructure is a critical component of cloud storage systems. Without fast and reliable networks, even the most advanced storage systems would struggle to deliver data efficiently. Google Cloud relies on a high-speed global network that connects data centers across different regions.
This network is designed to handle massive volumes of data traffic with minimal delay. It uses optimized routing protocols to ensure that data travels through the most efficient paths. This reduces congestion and improves overall system performance.
Network redundancy is also an important feature. Multiple network paths are available between data centers, ensuring that if one route becomes unavailable, traffic can be automatically redirected. This improves reliability and ensures uninterrupted access to stored data.
Bandwidth management is another key factor. As data volume increases, the system dynamically allocates network resources based on demand. This ensures that high-priority services receive the necessary bandwidth while maintaining overall system balance.
The strength of the underlying network infrastructure is one of the reasons cloud systems can handle such large-scale data storage and transfer operations efficiently.
Challenges of Managing Massive Data Volumes
While cloud systems are highly advanced, managing extremely large volumes of data comes with its own set of challenges. One of the primary challenges is maintaining performance as data continues to grow. As storage increases, systems must ensure that retrieval times remain fast and consistent.
Another challenge is cost management. Storing and processing large amounts of data requires significant infrastructure investment. Efficient resource allocation is essential to ensure that storage remains cost-effective while still meeting performance requirements.
Data consistency is also a critical challenge. In distributed systems, ensuring that all copies of data remain synchronized across multiple locations requires complex coordination. Any inconsistencies must be detected and corrected quickly to prevent errors.
Security risks also increase with data volume. Larger datasets provide more opportunities for potential vulnerabilities, making strong encryption, monitoring, and access control systems essential. Continuous monitoring is required to detect and respond to potential threats in real time.
Despite these challenges, advanced engineering and automation allow cloud systems to manage massive data volumes effectively and reliably.
Continuous Evolution of Cloud Storage Systems
Cloud storage systems are constantly evolving to meet the demands of an increasingly digital world. New technologies are regularly introduced to improve scalability, performance, and efficiency. These innovations ensure that cloud systems can continue to handle growing data volumes without interruption.
One major area of evolution is automation. More processes are being handled automatically, reducing the need for manual intervention and improving system efficiency. This includes automated scaling, error correction, and performance optimization.
Another area of advancement is artificial intelligence integration within cloud infrastructure itself. AI is increasingly being used to optimize storage distribution, predict usage patterns, and improve resource allocation. This helps systems adapt dynamically to changing workloads.
Hardware improvements also contribute to system evolution. Faster storage devices, improved processors, and more efficient memory systems allow cloud infrastructure to handle larger datasets more effectively.
As these advancements continue, cloud systems will become even more capable of managing massive amounts of data efficiently and reliably.
Expanding Digital Dependency and Future Data Flow
The world’s increasing dependence on digital systems ensures that cloud data storage will continue to grow. Nearly every modern application relies on cloud infrastructure in some form, whether for storage, processing, or communication. This dependency creates a continuous flow of data into cloud systems.
Digital services are becoming more integrated into everyday life, from personal communication tools to large-scale industrial systems. This integration ensures that data is constantly being generated, stored, and processed across multiple platforms simultaneously.
As technology continues to advance, new types of data will emerge, further increasing storage demands. These may include data from smart cities, autonomous vehicles, immersive virtual environments, and advanced robotics systems.
The result is a continuously expanding digital ecosystem where cloud storage plays a central role in supporting global connectivity and technological progress.
Final Conclusion
The total amount of data stored in Google Cloud is extremely large and continues to grow every second. While exact figures are not publicly disclosed, it is clear that the system operates at a scale measured in exabytes or more. This includes data from billions of users, countless businesses, and a wide range of digital applications across the world.
What makes this scale even more significant is not just the amount of data, but the speed at which it is growing. Every online interaction, digital service, and connected device contributes to this expansion. With advancements in artificial intelligence, global internet usage, and emerging technologies, the volume of stored data will continue to increase well into the future.
In simple terms, Google Cloud is one of the largest and most complex data storage systems ever built, and its size is constantly expanding as the digital world grows.