Modern enterprise networks depend heavily on continuous connectivity and uninterrupted security enforcement. In environments where even a few minutes of downtime can result in financial loss, service disruption, or security exposure, designing resilient infrastructure becomes essential. High Availability (HA) is one of the core design approaches used to ensure that critical systems remain operational even when hardware or software failures occur.
In the context of network security, High Availability refers to a configuration where two or more security devices work together as a synchronized system. Instead of relying on a single firewall to inspect and control all traffic, organizations deploy a pair of firewalls that continuously share operational state and configuration data. The purpose of this design is to eliminate a single point of failure. If one device becomes unavailable, the other can immediately take over without interrupting network traffic.
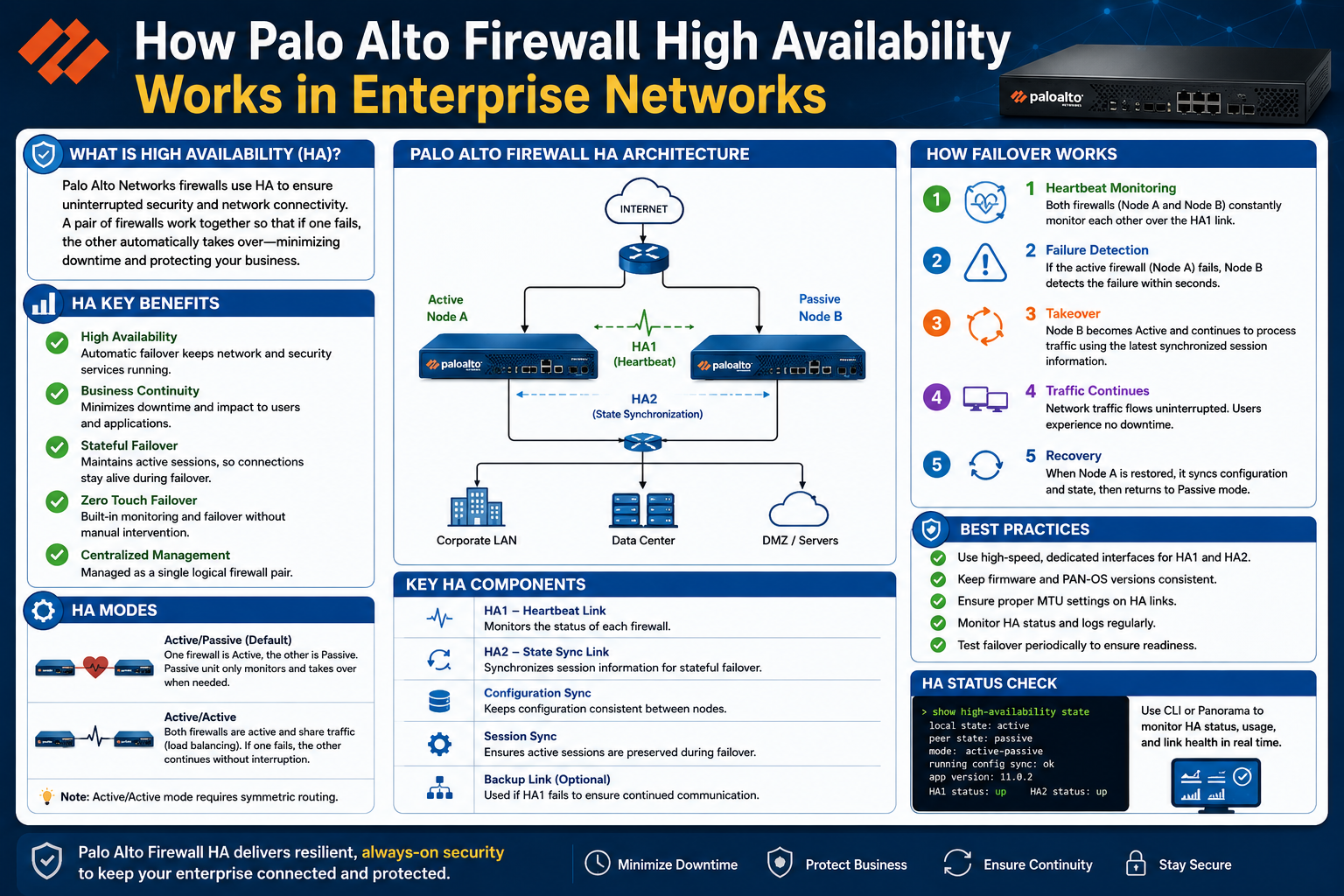
Palo Alto Networks firewalls implement High Availability in a structured and tightly integrated manner. The goal is not only to keep traffic flowing but also to ensure that security policies, active sessions, and network visibility remain consistent during and after a failover event. This level of continuity is critical in modern cybersecurity environments where attackers often exploit downtime or misconfigurations during transitions.
High Availability is not simply about having a backup device. It is about building a synchronized system where two firewalls behave almost like a single logical unit. This requires continuous communication, shared state awareness, and coordinated decision-making between the paired devices.
Core Idea Behind Palo Alto Firewall High Availability
The High Availability model in Palo Alto firewalls is designed around redundancy and synchronization. Two firewalls are configured as a pair, where one actively processes traffic while the other remains in a standby or synchronized state, depending on the deployment mode. Both devices continuously exchange information to ensure that they maintain identical configurations and an updated view of network sessions.
The most important idea behind this design is continuity. A firewall not only enforces policies; it also tracks active sessions such as user connections, application flows, and security inspections. If a firewall suddenly fails without state synchronization, all active sessions would be dropped, causing disruption. Palo Alto HA prevents this by maintaining session state across both devices.
This synchronized behavior allows the standby firewall to take over active sessions without requiring users or applications to reconnect. From the network perspective, the transition appears seamless, even though the underlying hardware has changed.
Another important aspect of Palo Alto HA is configuration synchronization. Any changes made on the active device, such as security policies, NAT rules, or interface adjustments, are automatically replicated to the peer firewall. This ensures that both devices are always aligned in terms of security posture.
By combining state synchronization and configuration replication, Palo Alto HA ensures that both firewalls are always ready to assume the active role at any moment. This readiness is what makes the system resilient against failures.
Architecture of a Palo Alto High Availability Pair
A High Availability pair in Palo Alto firewalls is built on a structured architecture that defines how devices communicate, share data, and coordinate failover decisions. At its core, the architecture consists of two identical firewalls connected through dedicated communication channels that serve specific purposes.
Each firewall in the pair operates independently at the hardware level but is logically bound to its peer through HA configuration. This logical binding allows them to function as a single security system rather than two separate devices.
The architecture is divided into several functional components. One component handles control plane communication, another manages data synchronization, and another ensures packet-level coordination in advanced deployment modes. These components work together continuously to maintain consistency between both devices.
The control plane handles high-level information exchange such as system status, configuration updates, and heartbeat signals. The data plane focuses on session synchronization and forwarding table consistency. This separation ensures that both operational intelligence and traffic handling remain aligned between devices.
In a properly designed HA pair, both firewalls are configured with identical software versions, matching hardware capabilities, and consistent feature support. This uniformity is essential because any mismatch can lead to synchronization issues or failover instability.
The architecture also includes decision-making logic that determines which firewall should be active at any given time. This decision is influenced by factors such as device priority, health status, and link monitoring results. If the active firewall fails or becomes unstable, the system automatically transitions control to the peer device.
HA Communication Channels and Their Roles
The effectiveness of Palo Alto High Availability depends heavily on the communication channels established between the paired firewalls. These channels are responsible for maintaining synchronization, monitoring health, and ensuring that failover decisions are executed correctly.
One of the most critical communication channels is the control link, often referred to as HA1. This link is responsible for exchanging system-level information between the firewalls. It carries heartbeat signals, configuration updates, and state information that helps each device understand the condition of its peer. The heartbeat mechanism is especially important because it continuously verifies that both firewalls are operational and able to communicate.
Another key channel is the data link, commonly referred to as HA2. This channel is responsible for synchronizing session information and forwarding tables. It ensures that active connections are mirrored across both firewalls so that sessions can continue without interruption during failover. The data link typically carries a large volume of real-time information, especially in busy network environments where thousands of sessions may be active simultaneously.
In advanced configurations, a third communication channel may be used, often referred to as HA3. This channel is primarily used in active/active deployments and is responsible for packet forwarding coordination between firewalls. It helps manage scenarios where traffic may need to be processed by both devices simultaneously or rerouted dynamically during asymmetric traffic flows.
Together, these communication channels form the backbone of the High Availability system. Without them, the firewalls would not be able to maintain synchronization or perform seamless failover operations. Each channel serves a distinct role, and their combined operation ensures that both firewalls function as a unified system.
Session Synchronization and State Continuity
One of the most powerful aspects of Palo Alto High Availability is its ability to maintain session continuity across firewall devices. In traditional network setups, a firewall failure often results in dropped connections because session information is stored locally on the device. Palo Alto HA addresses this limitation through real-time session synchronization.
Session synchronization involves copying active connection data from the active firewall to its peer device. This includes information such as source and destination IP addresses, application state, protocol details, and security inspection status. By maintaining this mirrored session table, the standby firewall is always aware of ongoing network activity.
When a failover occurs, the newly active firewall already has a complete understanding of existing sessions. This allows it to continue processing traffic without requiring users to re-establish connections. The transition is nearly invisible from an end-user perspective, which is essential for maintaining business continuity.
State continuity also extends to network address translation and security inspection processes. The firewall ensures that translated sessions and inspected traffic flows remain consistent even after a role change. This level of detail is what differentiates stateful high availability from simple backup redundancy systems.
Maintaining session synchronization requires continuous communication and efficient data transfer between firewalls. The system must balance accuracy with performance to ensure that synchronization does not impact normal traffic processing.
Failover Behavior and Trigger Mechanisms
Failover is the process through which control shifts from one firewall to its peer in a High Availability pair. This mechanism is at the core of HA functionality and ensures uninterrupted service during system disruptions.
A failover can be triggered by several conditions. One of the most common triggers is hardware or system failure on the active firewall. If the device becomes unresponsive or experiences critical errors, the peer firewall automatically assumes the active role.
Another trigger involves interface monitoring. Firewalls continuously check the health of key network interfaces. If a monitored interface fails, it may indicate a broader network issue, prompting a failover to maintain connectivity.
Heartbeat failure is another important trigger. If the standby firewall stops receiving heartbeat signals from the active device through the control link, it assumes that the active firewall is no longer operational and initiates failover procedures.
Path monitoring can also influence failover decisions. In this case, the firewall checks connectivity to important network destinations. If these destinations become unreachable, the system may determine that the active firewall is unable to properly route traffic and initiate a transition.
The failover process itself is carefully coordinated to avoid instability. The standby firewall transitions to active status, activates necessary interfaces, and begins processing traffic based on synchronized session data. This transition is designed to be fast and seamless to minimize disruption.
Importance of System Consistency in HA Deployment
For High Availability to function correctly, both firewalls must operate under consistent system conditions. This includes running the same PAN-OS version, having identical hardware configurations, and maintaining synchronized feature sets.
Version consistency is particularly important because differences in software behavior can lead to mismatched session handling or configuration interpretation. Even minor differences between versions can disrupt synchronization processes or cause failover instability.
Licensing consistency is also required, although each firewall maintains its own unique license. This ensures that both devices are capable of supporting the same features without relying on shared licensing.
Interface configuration consistency is another important requirement. Both firewalls must have matching interface types and roles to ensure that traffic is handled identically regardless of which device is active.
Without this level of consistency, the HA system cannot guarantee reliable failover behavior. Any mismatch introduces the risk of synchronization errors or traffic disruption during transitions.
Overview of Operational Roles in HA Pairing
Within a High Availability pair, each firewall is assigned a specific operational role. These roles define how the devices behave during normal operation and during failover events.
One firewall operates as the active device, responsible for processing all traffic and enforcing security policies. The second firewall operates in a passive or secondary role, continuously synchronizing data and monitoring the health of the active device.
Although only one firewall actively handles traffic in certain deployment modes, both devices remain fully operational and aware of each other’s state. This ensures that the system is always ready to respond to failures without delay.
In more advanced configurations, both firewalls may actively process traffic while still maintaining synchronization. This introduces additional complexity but allows for higher scalability and load distribution in large environments.
The assignment of roles is not static and can change dynamically based on system conditions, priority settings, and health evaluations.
Deep Dive into High Availability Deployment Modes
High Availability in Palo Alto firewalls is implemented through two primary deployment models, each designed for different network requirements and operational priorities. These models are Active/Passive and Active/Active, and while both aim to ensure continuity, they differ significantly in how traffic is handled and how system resources are utilized.
In an Active/Passive setup, only one firewall actively processes traffic at any given time. The second firewall remains in a synchronized standby state. It continuously receives updates about configuration changes, session states, and system health, but does not actively forward traffic unless a failure occurs. This model is widely used in enterprise environments because of its simplicity and predictability. It minimizes complexity and reduces the risk of asymmetric routing issues.
The Active/Passive model is particularly effective in environments where stability is more important than load distribution. Since only one firewall handles traffic, performance is predictable, and troubleshooting is simpler. The passive unit acts as a fully prepared backup, capable of taking over within seconds if the active device fails.
In contrast, Active/Active mode allows both firewalls to process traffic simultaneously. Each device maintains its own session table while synchronizing critical information with its peer. This model is designed for high-throughput environments where traffic loads exceed the capacity of a single firewall.
Active/Active introduces additional complexity because traffic can be processed by either device, depending on routing decisions, load conditions, or session ownership rules. It requires careful planning to avoid asymmetric routing and to ensure consistent session handling across both devices.
While Active/Active offers better resource utilization, it is generally used in more advanced deployments where network engineers are experienced in managing distributed firewall operations.
Election Process and Role Determination
In a High Availability pair, the decision about which firewall becomes active is determined through an election process. This process ensures that only one device assumes the active role under normal conditions, preventing conflicts or duplicate traffic processing.
The election process is influenced by several factors, with device priority being one of the most important. Each firewall is assigned a priority value, and the device with the lower numerical value (indicating higher priority) is typically preferred as the active unit. However, priority alone does not guarantee an active role if other conditions suggest otherwise.
System health plays a critical role in the election process. If the preferred firewall is experiencing hardware issues, interface failures, or synchronization problems, the peer firewall may assume the active role even if its priority is lower.
Another important factor is preemption. When preemption is enabled, a higher-priority firewall can reclaim the active role after recovering from a failure. Without preemption, the current active firewall retains its role even if a higher-priority device becomes available later.
The election process also considers configuration consistency and synchronization status. A firewall that is not fully synchronized may be excluded from becoming active until it reaches a stable state.
This dynamic decision-making process ensures that the most stable and properly configured firewall is always responsible for handling network traffic.
HA Timers and Convergence Behavior
High Availability systems rely heavily on timers to detect failures and initiate failover actions. These timers control how quickly a firewall reacts to changes in peer status or network conditions.
Heartbeat timers are among the most important. These timers define how frequently the firewalls exchange health-check messages over the control link. If a firewall fails to receive heartbeat signals within a defined interval, it may assume that the peer is no longer operational.
There are also hold timers that introduce a delay before triggering failover actions. These timers help prevent unnecessary failovers caused by temporary network glitches or short-lived communication interruptions.
Convergence behavior refers to the time it takes for the system to stabilize after a failover event. During convergence, the new active firewall must activate interfaces, synchronize session data, and begin processing traffic. The efficiency of this process depends on system load, configuration complexity, and the volume of active sessions.
Fast convergence is critical in environments where downtime must be minimized. However, overly aggressive timer settings can lead to instability, causing frequent or unnecessary failovers.
Balancing timer sensitivity with system stability is a key aspect of HA design. Properly tuned timers ensure that the system reacts quickly to real failures while ignoring transient issues.
Path Monitoring and Interface Monitoring Logic
Palo Alto High Availability uses monitoring mechanisms to evaluate the health of both network interfaces and external destinations. These monitoring systems play a key role in determining whether a firewall should remain active or trigger a failover.
Interface monitoring focuses on physical and logical interface health. Each firewall can be configured to monitor specific interfaces, such as uplinks or critical network connections. If one of these interfaces fails, it may indicate a broader network issue that justifies a failover.
Path monitoring, on the other hand, evaluates connectivity to external destinations. The firewall sends periodic probes to predefined IP addresses or network endpoints. These endpoints typically represent critical infrastructure such as routers, servers, or internet gateways.
If path monitoring detects that these destinations are unreachable, the firewall may conclude that it is unable to properly route traffic. This can trigger a failover even if the firewall itself is still operational.
Together, interface and path monitoring provide a comprehensive view of network health. They allow the HA system to make intelligent decisions based not only on device status but also on overall network reachability.
Configuration Synchronization Mechanism
One of the most important functions in a High Availability setup is configuration synchronization. This process ensures that both firewalls maintain identical security policies, network settings, and system configurations.
When a configuration change is made on the active firewall, it is automatically propagated to the passive device through the HA control link. This includes updates to security rules, NAT configurations, interface settings, and system parameters.
Synchronization occurs in real time or near real time, depending on system load and configuration complexity. The goal is to ensure that both devices are always aligned so that failover can occur without requiring additional configuration adjustments.
However, not all data is synchronized. Certain elements, such as logs, management IP settings, and administrative sessions, remain local to each firewall. This separation ensures that operational data does not interfere with synchronization processes.
Configuration synchronization also includes validation checks. Before applying changes to the peer device, the system verifies compatibility and consistency to prevent errors or misconfigurations.
This mechanism ensures that both firewalls are always prepared to assume the active role without delay.
Session Ownership and Traffic Continuity Handling
In High Availability environments, session ownership determines which firewall is responsible for handling a specific network connection. This is especially important in Active/Active deployments where both devices are actively processing traffic.
Each session is assigned an owner firewall based on routing decisions, load distribution, or session initiation location. Once a session is established, its ownership remains consistent to avoid disruption.
Session continuity is maintained through synchronization between firewalls. Even if a session is owned by one device, its state information is mirrored to the peer firewall. This ensures that if a failover occurs, the session can continue without interruption.
Handling asymmetric routing is one of the more complex challenges in HA environments. This occurs when incoming and outgoing traffic for the same session takes different paths through different firewalls. Palo Alto HA systems are designed to detect and manage such conditions to maintain session integrity.
By carefully tracking session ownership and state, the system ensures that traffic flows remain consistent even during topology changes or failover events.
Behavior and Design of HA Links
The communication between firewalls in a High Availability pair relies on specialized HA links, each serving a distinct purpose in maintaining system synchronization.
The control link is responsible for exchanging high-level information such as system health, configuration updates, and heartbeat signals. It acts as the primary communication channel for coordination between firewalls.
The data link handles session synchronization and forwarding table updates. It ensures that both firewalls have an identical view of active network sessions, allowing seamless failover without session loss.
In more advanced setups, a packet forwarding link may be used. This link supports direct packet exchange between firewalls in Active/Active deployments, enabling coordinated traffic handling across both devices.
These links are typically configured using dedicated interfaces or ports to ensure reliability and separation from regular network traffic. This isolation prevents synchronization traffic from interfering with production data flows.
Each link is carefully designed to operate at high speed and low latency, ensuring that synchronization remains efficient even in high-traffic environments.
Backup Link Strategy and Redundancy Planning
To further enhance reliability, High Availability configurations often include backup links for critical communication channels. These backup links provide an alternative path for synchronization traffic in case primary HA links fail.
Backup links are typically configured using separate physical interfaces or network paths. This ensures that a single point of failure does not disrupt communication between firewalls.
Proper design of backup links requires careful planning of IP addressing and network segmentation. Backup interfaces must be placed on separate subnets to avoid conflicts and ensure clear routing paths.
Redundancy in HA links is essential in large-scale deployments where network stability is critical. Without backup paths, a failure in the control or data link could lead to synchronization loss or failover instability.
Backup link strategies also include monitoring mechanisms that detect primary link failure and automatically switch communication to the backup path.
Common Operational Challenges and Failure Scenarios
Despite its robustness, High Availability systems can encounter operational challenges if not properly configured or maintained. One common issue is split-brain behavior, where both firewalls mistakenly believe they are active due to a communication failure. This can result in traffic conflicts and network instability.
Another issue is session desynchronization, which occurs when session tables are not properly synchronized between devices. This can lead to dropped connections during failover events.
Interface flapping is also a frequent problem in poorly designed networks. When monitored interfaces frequently go up and down, it can trigger unnecessary failovers, disrupting network stability.
Configuration mismatches between firewalls can also cause synchronization failures. Even small differences in settings or software versions can prevent proper HA operation.
Monitoring tools and system dashboards are essential for detecting these issues early. They provide visibility into synchronization status, failover history, and system health indicators.
Operational Monitoring and System Visibility
Effective management of High Availability systems requires continuous monitoring of firewall health and synchronization status. Palo Alto firewalls provide detailed visibility into HA operations through system dashboards and status indicators.
Administrators can monitor which device is currently active, synchronization status between peers, and the health of communication links. This visibility is essential for identifying potential issues before they lead to failures.
Log analysis also plays a key role in understanding HA behavior. System logs provide detailed information about failover events, configuration changes, and synchronization status updates.
By maintaining continuous visibility into HA operations, network administrators can ensure that the system remains stable, synchronized, and ready to handle failures at any time.
Advanced Failover Scenarios in Palo Alto High Availability Environments
High Availability in Palo Alto firewalls is designed to handle a wide range of failure scenarios, from simple interface outages to complex system-level disruptions. While basic failover behavior is relatively straightforward, real-world environments introduce conditions that are far more dynamic and unpredictable. Understanding advanced failover scenarios is essential for building resilient networks that can withstand both planned and unplanned disruptions.
One of the most important aspects of failover behavior is that it is not always triggered by a single event. In many cases, multiple conditions must be evaluated together before a decision is made. For example, a firewall might still be operational at the hardware level but unable to reach critical network destinations. In such cases, the system may determine that continuing to use that firewall would compromise network availability, even though the device has not fully failed.
This decision-making process ensures that failover is not purely reactive but also predictive in nature. The system continuously evaluates health indicators to determine whether the active firewall is still suitable for traffic processing.
Layered Failure Detection and Decision Logic
Palo Alto High Availability uses a layered approach to failure detection. This means that different types of checks operate simultaneously, each focusing on a specific aspect of system health. These layers include hardware monitoring, interface monitoring, link monitoring, and application-level reachability checks.
Hardware monitoring focuses on physical components such as power supplies, CPU health, and system memory. If a critical hardware failure is detected, the firewall is immediately considered unhealthy, and failover is triggered.
Interface monitoring evaluates the status of network ports. If key interfaces go down, especially those connected to upstream or downstream networks, the system may interpret this as a loss of connectivity that affects traffic flow.
Link monitoring goes beyond physical interfaces and examines logical connectivity. It checks whether the firewall can still communicate with important network devices such as routers, switches, or core services.
At a higher level, application reachability monitoring evaluates whether essential services are accessible. This may include DNS servers, authentication systems, or external endpoints required for business operations.
The combination of these monitoring layers allows the firewall to make intelligent decisions about whether it should remain active or relinquish control to its peer.
Split-Brain Prevention Mechanisms
One of the most critical challenges in any high-availability system is preventing a condition known as split-brain. This occurs when both firewalls believe they are active simultaneously due to a communication breakdown between them. If not properly controlled, this condition can lead to duplicate traffic processing, routing conflicts, and severe network instability.
Palo Alto firewalls implement multiple safeguards to prevent split-brain scenarios. The most important safeguard is the control link, which continuously exchanges heartbeat messages between devices. If this link fails, the system does not immediately assume that the peer is down. Instead, it evaluates additional factors such as backup heartbeat paths and path monitoring results.
Another safeguard is the use of predefined priority rules and election logic. Even if communication is lost, the system uses stored priority values and last known states to determine which firewall should remain active.
In some configurations, backup heartbeat mechanisms through the management interface provide an additional layer of protection. These secondary communication paths help maintain awareness between devices even when primary links fail.
Split-brain prevention is essential because it ensures that only one firewall processes traffic at any given time. Without these mechanisms, network consistency could not be guaranteed.
Complex Failover Decision Chains in Real Networks
In practical environments, failover decisions are rarely based on a single trigger. Instead, they are the result of multiple conditions being evaluated simultaneously. This creates a decision chain that determines whether a failover should occur.
For example, consider a scenario where the active firewall is still operational but has lost connectivity to a critical upstream router. At the same time, the control link between firewalls remains active. In this case, the system must decide whether the issue is localized or systemic.
If path monitoring confirms that external connectivity is lost, the firewall may still trigger failover even though internal communication between peers is intact. This ensures that traffic is always routed through the device with the best network visibility.
In another scenario, the active firewall may experience high CPU utilization due to traffic spikes. While this alone may not trigger failover, combined with interface instability or packet drops, it could lead the system to determine that the firewall is no longer suitable for active duty.
These layered conditions create a sophisticated decision-making framework that prioritizes network stability over device status alone.
Failover During Software and System Upgrades
Software upgrades introduce one of the most common planned failover scenarios in High Availability environments. When upgrading Palo Alto firewalls, administrators typically follow a controlled process that leverages HA to maintain uptime.
During an upgrade, the passive firewall is upgraded first while the active firewall continues to handle traffic. Once the passive device is upgraded and synchronized, a manual or automatic failover is initiated. The upgraded device then becomes active, and the original active firewall is upgraded in turn.
This process ensures that at no point are both firewalls offline or running incompatible software versions simultaneously in an active state. However, temporary synchronization mismatches can occur during the upgrade window.
Careful coordination is required to ensure that session continuity is maintained throughout the upgrade process. In well-designed environments, users experience no disruption during this transition.
Upgrades highlight the importance of HA not only as a failure recovery mechanism but also as a maintenance tool that enables zero-downtime operations.
Impact of Network Topology on HA Behavior
The behavior of High Availability systems is heavily influenced by network topology. The placement of firewalls within the network determines how traffic flows, how failover is detected, and how quickly recovery occurs.
In a simple topology where firewalls are placed at the network edge, failover decisions are straightforward. Traffic enters and exits through a single point, making it easy to detect disruptions.
In more complex topologies, such as multi-tier or distributed networks, failover behavior becomes more dynamic. Firewalls may need to coordinate with multiple upstream and downstream devices to determine the best course of action.
Asymmetric routing is a common challenge in complex topologies. This occurs when return traffic takes a different path than outbound traffic. High Availability systems must be able to recognize and handle such scenarios to avoid session disruption.
Network segmentation also plays a role in HA behavior. Different segments may have different monitoring requirements, and failover decisions may be influenced by the criticality of each segment.
Proper topology design ensures that HA systems can operate efficiently without introducing routing inconsistencies or performance bottlenecks.
Role of Session Tables in Maintaining Stability
Session tables are one of the most important components of Palo Alto firewall operation, especially in High Availability environments. These tables store detailed information about active network connections, including source and destination addresses, ports, protocols, and application metadata.
In an HA pair, session tables are continuously synchronized between devices. This ensures that both firewalls maintain an identical view of network activity.
During failover, the new active firewall relies on its session table to continue processing existing connections. Without this synchronization, all active sessions would be dropped, leading to service disruption.
Session table management also includes pruning and optimization processes. As sessions expire or become inactive, they are removed from the table to maintain efficiency.
In high-traffic environments, session synchronization can become resource-intensive. Firewalls must balance synchronization accuracy with performance to ensure that traffic processing remains efficient.
Active/Active Traffic Distribution Behavior
In Active/Active deployments, both firewalls actively process traffic, which introduces additional complexity in traffic distribution. Sessions may be distributed between devices based on routing decisions, load conditions, or session ownership rules.
Each firewall maintains its own session table while synchronizing essential information with its peer. This allows both devices to maintain awareness of all active sessions in the environment.
Traffic distribution is influenced by routing protocols and network design. In some cases, one firewall may handle more traffic than the other, depending on its position within the network path.
Active/Active configurations also introduce the possibility of session rebalancing during network changes. If one firewall becomes overloaded, new sessions may be directed to the peer device to balance the load.
However, maintaining consistency in Active/Active mode requires careful configuration. Without proper design, issues such as duplicate sessions or routing loops can occur.
HA Stability Under High Traffic Conditions
High Availability systems must remain stable even under extreme traffic conditions. In enterprise environments, firewalls often process thousands or even millions of sessions simultaneously.
Under high load, synchronization mechanisms must operate efficiently to prevent performance degradation. The system prioritizes critical synchronization tasks such as session updates and heartbeat communication.
If synchronization becomes delayed due to heavy load, there is a risk that failover decisions may be based on outdated information. To prevent this, Palo Alto firewalls are designed to prioritize HA communication over less critical processes when necessary.
Resource management plays a key role in maintaining stability. CPU, memory, and bandwidth usage must be carefully balanced to ensure that both traffic processing and HA synchronization remain reliable.
Behavior During Partial Failures and Degraded States
Not all failures result in complete device failure. In many cases, firewalls enter a degraded state where they are still operational but not functioning optimally.
Examples of degraded states include partial interface failure, memory pressure, or slow response times. In such cases, the HA system must determine whether the device should remain active or be replaced by its peer.
This decision is based on multiple health indicators rather than a single failure signal. If the degraded condition affects traffic processing or synchronization reliability, failover may be triggered.
Degraded states are particularly challenging because they require the system to distinguish between temporary performance issues and long-term instability.
Coordination Between Control Plane and Data Plane
The control plane and data plane play distinct but interconnected roles in High Availability systems. The control plane handles configuration, routing decisions, and HA communication, while the data plane handles actual traffic forwarding.
Synchronization between these planes is essential for maintaining consistent behavior across firewalls. If the control plane is synchronized but the data plane is not, traffic forwarding inconsistencies may occur.
During failover, both planes must transition together to ensure that routing, session handling, and security enforcement remain aligned.
This coordination ensures that the firewall continues to operate as a unified security system even when underlying hardware roles change.
Continuous State Awareness and System Intelligence
One of the most advanced aspects of Palo Alto High Availability is its continuous state awareness. The system constantly evaluates the condition of both firewalls, network paths, and active sessions.
This continuous evaluation allows the system to respond quickly to changes without requiring manual intervention. It also enables predictive decision-making, where potential failures can be detected before they fully occur.
By combining real-time monitoring, synchronization, and intelligent decision logic, the HA system behaves as a self-regulating architecture capable of maintaining stability in dynamic environments.
Extended Stability Considerations in Real-World HA Operations
In real production environments, High Availability behavior is influenced not only by configuration and design but also by subtle operational factors that develop over time. One of the most important of these factors is environmental consistency. Even when two firewalls are correctly configured as a pair, differences in traffic patterns, interface utilization, or external dependencies can gradually affect how each device performs under load. These variations do not necessarily cause failure, but they can influence synchronization efficiency and failover sensitivity.
Another key consideration is long-running session behavior. In networks where sessions remain active for extended periods—such as VPN tunnels, database connections, or streaming applications—the stability of session synchronization becomes especially important. If synchronization delays occur, even briefly, there is a risk that long-lived sessions may lose state accuracy during a failover event. This is why HA systems are designed to continuously refresh session metadata rather than relying on periodic bulk updates.
Timing drift between HA peers can also introduce subtle issues. Although control links maintain heartbeat communication, small variations in system timing under heavy load can affect how quickly events are processed. Over time, this may influence failover responsiveness or cause minor inconsistencies in event logging between devices. Modern implementations mitigate this by prioritizing HA communication threads and ensuring that critical synchronization tasks are not delayed by non-essential processes.
Another often overlooked factor is asymmetric load distribution in Active/Active environments. While both firewalls are technically active, traffic is rarely distributed evenly. One device may consistently handle more complex or higher-volume sessions, leading to uneven resource consumption. This imbalance can affect synchronization performance, as the heavier-loaded firewall may experience slightly delayed updates compared to its peer. Over-extended periods, this can influence failover behavior if not properly monitored.
External dependency reliability also plays a major role. High Availability systems rely on stable connectivity not only between peers but also with monitored network endpoints. If external monitoring targets are unstable or intermittently unreachable, the system may misinterpret these signals as firewall failure, leading to unnecessary failovers. For this reason, monitoring targets must be carefully selected to represent truly critical and stable network infrastructure.
Another important aspect is recovery stabilization after a failover. When a new active firewall takes over, it does not immediately operate at steady-state efficiency. It must rebuild confidence in network paths, refresh routing tables, and stabilize session handling under live traffic conditions. During this period, performance may fluctuate slightly as the system adjusts to its new role. Well-designed HA systems minimize this window through pre-synchronization and pre-initialization of critical components.
Finally, long-term HA reliability depends heavily on consistent operational maintenance. Over time, software updates, configuration changes, and network expansions can introduce subtle mismatches if not carefully managed. Regular validation of synchronization status, interface health, and failover readiness ensures that both firewalls remain truly aligned as a unified system rather than drifting into inconsistent operational states.
Conclusion
High Availability in Palo Alto firewalls is a foundational design approach for maintaining continuous network security and minimizing downtime in modern IT environments. By pairing two firewalls and synchronizing their configurations, sessions, and operational states, organizations can ensure that security enforcement remains uninterrupted even during hardware failures, network disruptions, or planned maintenance activities. The combination of control links, data links, and intelligent monitoring mechanisms enables seamless failover, allowing one firewall to instantly take over the responsibilities of its peer without disrupting active connections.
Whether deployed in Active/Passive or Active/Active mode, HA provides flexibility to match different business and traffic requirements while maintaining strong resilience. Its effectiveness depends on proper configuration, consistent system alignment, and ongoing monitoring of health and synchronization status. When implemented correctly, Palo Alto HA significantly strengthens network reliability, reduces operational risk, and ensures that critical services remain available even under adverse conditions.