In modern digital systems, uptime is not just a technical metric—it is directly tied to revenue, reputation, and user trust. Even brief service interruptions can lead to lost transactions, dissatisfied customers, and operational disruption. This reality has pushed organizations to design systems that are resilient by default. Within cloud computing, resilience is typically achieved through two closely related but distinct approaches: high availability and fault tolerance. While both aim to reduce downtime, they differ in how they respond to failures and the level of continuity they guarantee.
Cloud platforms have made it significantly easier to design resilient systems without the burden of managing physical infrastructure. Instead of investing heavily in hardware, data centers, and maintenance, teams can now rely on distributed architectures and managed services to achieve reliability at scale. However, choosing between high availability and fault tolerance—or combining both—requires a clear understanding of business needs, risk tolerance, and system criticality.
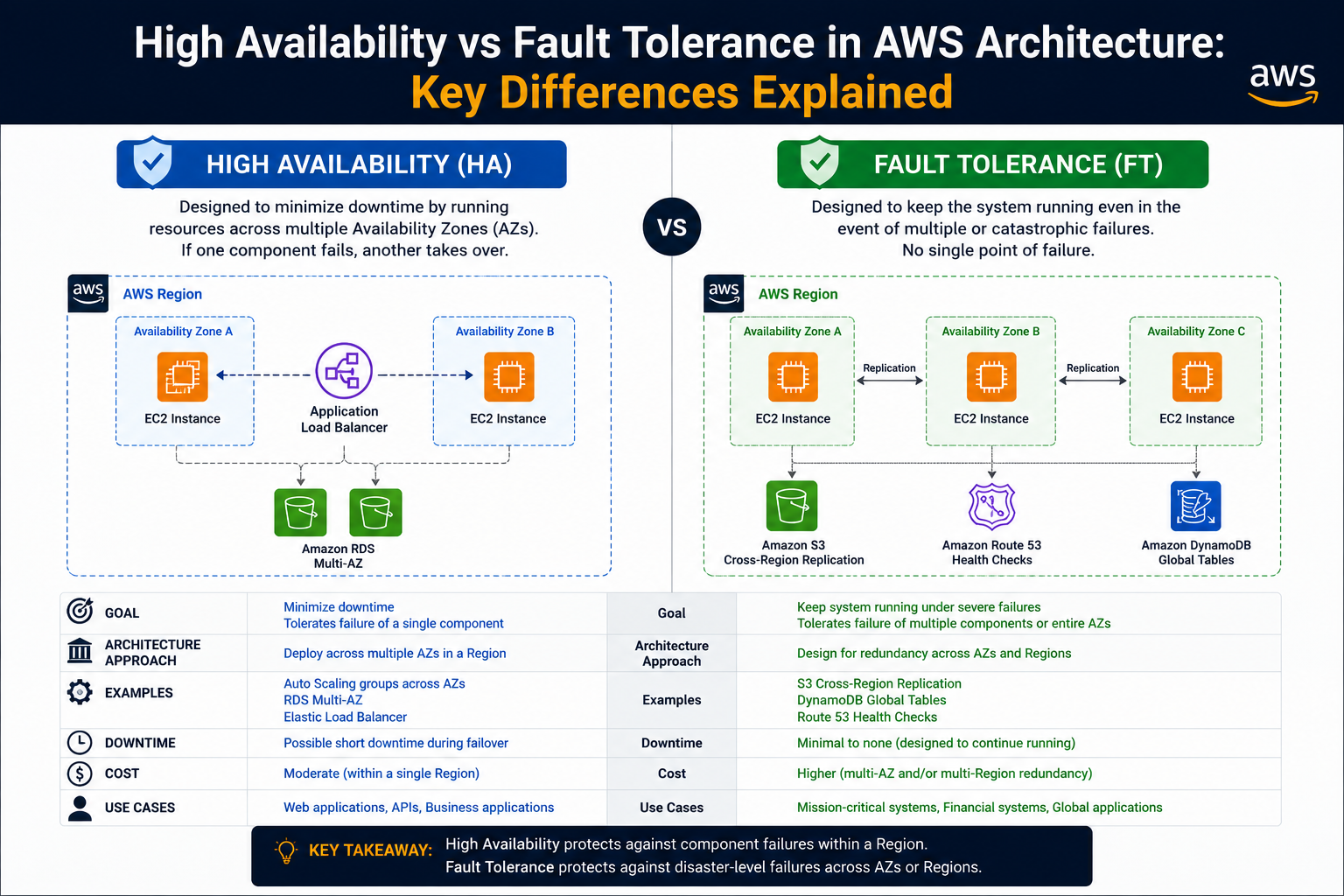
Understanding High Availability
High availability refers to a system’s ability to remain operational for the vast majority of time, even in the presence of failures. It does not mean that failures never occur, but rather that the system is designed to recover quickly and continue providing essential services. In most cases, a highly available system may experience short interruptions or operate in a limited capacity during a failure event.
The foundation of high availability lies in eliminating single points of failure. A single point of failure is any component whose failure would bring down the entire system. By introducing redundancy—such as multiple servers, replicated databases, and distributed workloads—systems can continue functioning even when individual components fail.
In a cloud environment, high availability is often achieved by distributing resources across multiple availability zones. These zones are isolated locations within a region, each with independent power, networking, and infrastructure. By deploying applications across multiple zones, organizations ensure that a failure in one zone does not impact the entire system.
Another critical aspect of high availability is failover. When a primary component fails, traffic is automatically redirected to a backup component. This transition may take a few seconds or minutes, during which users might experience slight delays or reduced functionality. However, the system remains accessible, and critical operations continue.
High availability also involves data replication, where data is copied from a primary database to secondary instances. These replicas ensure that data is not lost during failures. In many cases, replicas may be read-only, allowing users to access information even if write operations are temporarily unavailable.
While high availability significantly reduces downtime, it does not guarantee uninterrupted service. Users may notice slower performance, limited features, or temporary inconsistencies in data. Nevertheless, for many applications, this level of resilience is sufficient and cost-effective.
Practical Perspective on High Availability
Consider a digital application where users perform both read and write operations. In a highly available setup, the system is designed so that read operations remain accessible even during failures. Write operations, however, might be delayed or temporarily disabled if the primary system is unavailable.
This approach prioritizes continuity over completeness. Users can still interact with the system, access information, and perform essential tasks, even if some features are restricted. Once the primary system is restored, full functionality resumes, and any pending operations are processed.
High availability is particularly suitable for systems where occasional degradation is acceptable. Internal tools, reporting systems, and non-critical applications often fall into this category. The goal is to maintain productivity without incurring the high costs associated with more advanced resilience strategies.
Understanding Fault Tolerance
Fault tolerance takes resilience a step further. A fault-tolerant system is designed to continue operating without any noticeable interruption, even when components fail. Unlike high availability, where recovery may involve brief delays or reduced functionality, fault tolerance ensures seamless continuity.
In a fault-tolerant architecture, redundancy is not just present—it is active. Multiple components run simultaneously, and if one fails, another immediately takes over without any disruption. This requires real-time synchronization of data and continuous monitoring of system health.
Fault tolerance often involves deploying systems across multiple regions, not just availability zones. This geographic distribution protects against large-scale failures such as natural disasters, network outages, or regional disruptions. By maintaining identical environments in different regions, systems can switch operations instantly when needed.
Another key element of fault tolerance is load balancing. Traffic is distributed across multiple active instances, ensuring that no single component becomes a bottleneck. If one instance fails, traffic is automatically rerouted to others without affecting users.
Data consistency is also critical in fault-tolerant systems. Unlike high availability setups where replicas may lag behind the primary database, fault-tolerant architectures rely on near real-time replication. This ensures that all instances have up-to-date data, enabling seamless transitions during failures.
Practical Perspective on Fault Tolerance
In a fault-tolerant system, users are unaware of failures as they occur. Transactions continue without interruption, data remains consistent, and performance stays stable. This level of resilience is essential for applications where downtime is unacceptable, such as financial systems, large-scale e-commerce platforms, and critical infrastructure services.
Achieving fault tolerance requires careful planning, advanced architecture, and higher investment. Systems must be designed to handle failures automatically, without human intervention. Monitoring, automation, and testing play a crucial role in ensuring that failover mechanisms work as intended.
Because of its complexity and cost, fault tolerance is typically reserved for mission-critical applications. Organizations must weigh the benefits against the resources required to implement and maintain such systems.
Key Differences Between High Availability and Fault Tolerance
The distinction between high availability and fault tolerance lies in how systems respond to failure. High availability focuses on minimizing downtime and maintaining essential functionality, while fault tolerance aims to eliminate downtime entirely.
In a highly available system, failures trigger recovery processes. There may be a brief interruption or degradation in service, but the system quickly returns to normal operation. In contrast, a fault-tolerant system continues operating without any noticeable impact, as backup components are already active and synchronized.
Cost is another major differentiator. High availability is generally more affordable because it relies on standby resources that are activated only when needed. Fault tolerance, on the other hand, requires fully active duplicate systems, significantly increasing infrastructure and operational costs.
Complexity also varies between the two approaches. High availability can be implemented using standard cloud services and straightforward configurations. Fault tolerance demands advanced architecture, continuous synchronization, and rigorous testing to ensure seamless operation.
Choosing the Right Approach
Selecting between high availability and fault tolerance depends on the importance of the system and the potential impact of downtime. Not all applications require the same level of resilience, and over-engineering can lead to unnecessary expenses.
For systems where occasional downtime is acceptable, high availability provides a balanced solution. It ensures reliability without excessive cost, making it suitable for internal applications, content platforms, and services with moderate traffic.
For systems where downtime directly affects revenue or safety, fault tolerance is the preferred choice. Applications that handle financial transactions, real-time communications, or critical operations must remain available at all times, justifying the additional investment.
In many cases, organizations adopt a hybrid approach. Core components of the system may be fault-tolerant, while less critical parts rely on high availability. This allows for efficient resource allocation while maintaining overall resilience.
Design Considerations for Resilient Architectures
Building resilient systems requires more than just selecting an approach. It involves thoughtful design, continuous monitoring, and regular testing. Redundancy must be implemented at every level, including compute, storage, networking, and databases.
Automation plays a key role in both high availability and fault tolerance. Automated failover, scaling, and recovery processes ensure that systems respond quickly to failures without manual intervention. Monitoring tools provide visibility into system performance, enabling teams to detect and address issues proactively.
Testing is equally important. Simulating failures helps identify weaknesses in the architecture and ensures that recovery mechanisms work as expected. By regularly testing resilience, organizations can improve their systems and reduce the risk of unexpected downtime.
Scalability is another critical factor. As demand grows, systems must be able to handle increased traffic without compromising performance or reliability. Cloud environments make it easier to scale resources dynamically, supporting both high availability and fault tolerance strategies.
Balancing Performance and Cost
One of the biggest challenges in designing resilient systems is balancing performance with cost. While it may be tempting to aim for complete fault tolerance, the associated expenses may not always be justified.
High availability offers a cost-effective solution for most applications, providing strong reliability without excessive resource usage. Fault tolerance should be reserved for scenarios where the cost of downtime outweighs the cost of implementation.
Organizations must evaluate their requirements carefully, considering factors such as user expectations, business impact, and regulatory requirements. By aligning architecture with business goals, they can achieve the right balance between resilience and efficiency.
The Role of Cloud in Modern Resilience
Cloud computing has transformed the way systems are designed and operated. Instead of building and maintaining physical infrastructure, organizations can leverage managed services that handle many aspects of resilience automatically.
Features such as multi-zone deployment, automated backups, and global replication simplify the implementation of high availability and fault tolerance. This allows teams to focus on application logic and user experience rather than infrastructure management.
Cloud platforms also provide tools for monitoring, logging, and testing, enabling continuous improvement of system resilience. By taking advantage of these capabilities, organizations can build robust architectures that adapt to changing demands and evolving risks.
Conclusion
Resilience is a fundamental requirement in modern system design, and understanding the difference between high availability and fault tolerance is essential for making informed architectural decisions. High availability ensures that systems remain accessible with minimal downtime, even if some functionality is temporarily limited. Fault tolerance goes further by eliminating interruptions entirely, providing seamless continuity regardless of failures.
Each approach has its strengths, trade-offs, and ideal use cases. High availability offers a practical and cost-effective solution for most applications, while fault tolerance is reserved for mission-critical systems where downtime is not an option. By carefully evaluating requirements and leveraging cloud capabilities, organizations can design architectures that meet their reliability goals without unnecessary complexity.
Ultimately, failure is not a matter of if, but when. Systems will encounter disruptions, whether due to hardware issues, network failures, or unforeseen events. The key to success lies in preparing for these failures and designing systems that can withstand them. By embracing resilience as a core principle, organizations can ensure that their applications remain reliable, responsive, and ready to meet user expectations at all times.