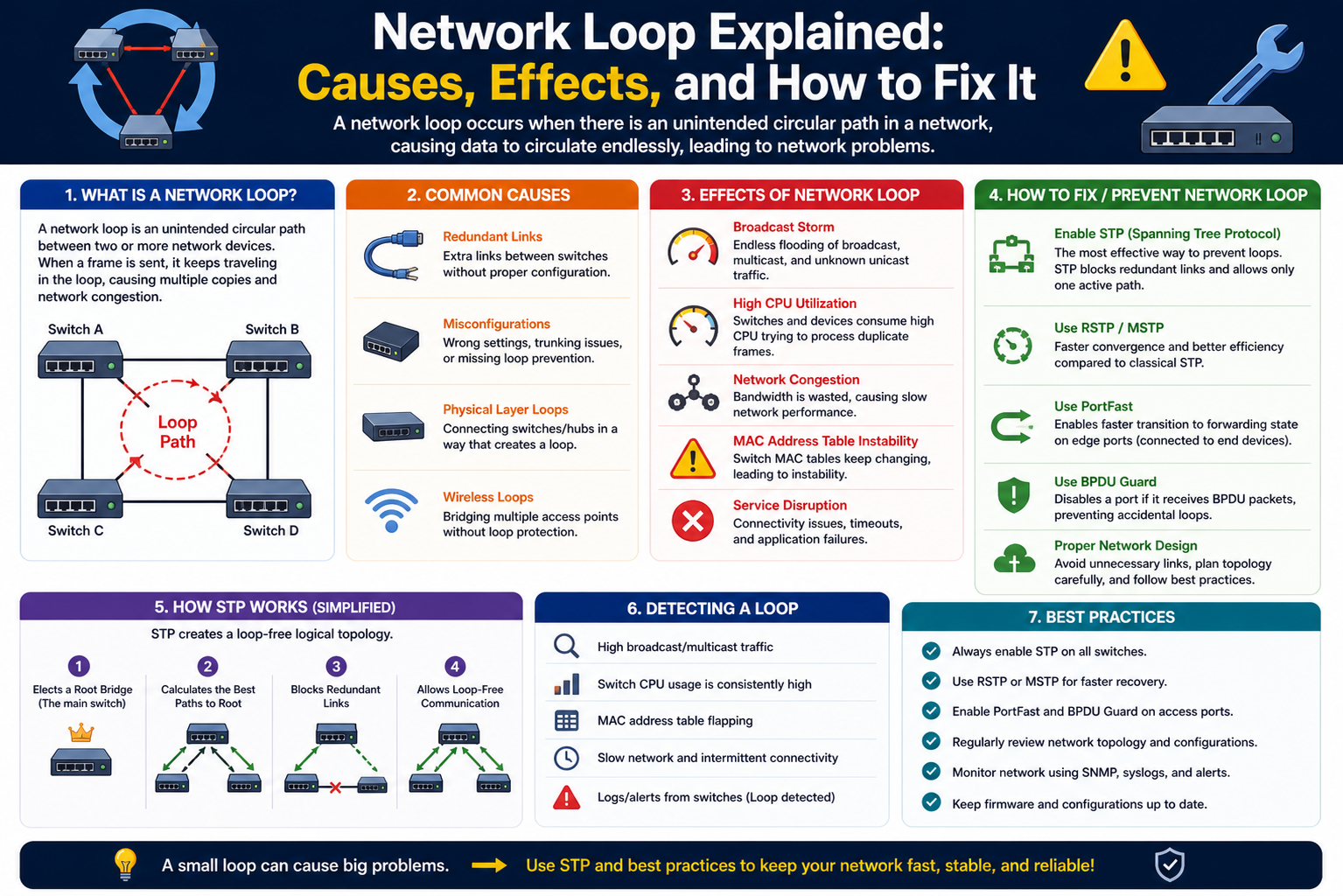
A network loop is a situation in a computer network where data packets continuously circulate through a series of connected devices without reaching their final destination. Instead of moving forward and completing their journey, the packets are redirected back into the same path again and again, creating an endless cycle of transmission. This repeated circulation leads to unnecessary consumption of network resources, which eventually reduces performance and can cause serious disruptions in communication across the system.
In simple terms, a network loop can be compared to a road system where vehicles are unintentionally directed into a circular route with no exit. No matter how much time passes, the vehicles keep moving around the same path without ever reaching their destination. In networking, this behavior is not intentional and usually occurs due to incorrect configurations, redundant connections, or errors in routing and switching logic.
Understanding How Network Loops Occur
Network loops usually happen when there are multiple paths between devices in a network and the system fails to properly manage which path should be used for forwarding data. Modern networks are designed with redundancy so that if one path fails, another can take over. While this redundancy improves reliability, it also increases the risk of loops forming if proper controls are not in place.
When devices such as switches or routers are not correctly configured, they may continuously forward the same data back and forth between each other. Each device believes it is helping deliver the packet, but in reality, the packet is stuck in a repeating cycle. This can happen due to incorrect routing information, miscommunication between devices, or missing loop prevention mechanisms.
Another common cause is incorrect updates in forwarding tables. Switches use MAC address tables to decide where to send data frames. If these tables are inaccurate or constantly changing due to unstable connections, packets may be forwarded in circles instead of moving toward their intended destination.
Network Traffic Behavior in a Loop
When a network loop occurs, the behavior of traffic becomes highly inefficient. Instead of following a direct path, data packets start traveling repeatedly between the same set of devices. Each time the packet passes through a device, it consumes processing power, memory, and bandwidth.
As more packets enter the loop, the amount of traffic inside the network increases rapidly. This creates a snowball effect where the network becomes overloaded with repeated data. Since the same packets are being circulated multiple times, new legitimate data struggles to get through, leading to congestion and delays.
Over time, the looped traffic can grow so large that it consumes almost all available network capacity. Devices become overwhelmed trying to process and forward the repeated packets, which significantly reduces overall network efficiency and responsiveness.
Role of Redundant Paths in Networks
Modern computer networks are intentionally designed with redundant paths to ensure reliability and fault tolerance. Redundancy means that there is more than one possible route for data to travel between two points. If one path fails, another path can immediately take over, ensuring continuous communication without interruption.
However, these multiple paths can also become a source of problems if not properly controlled. When two or more active paths exist between devices without a mechanism to manage them, data packets may start circulating through all available routes instead of following a single optimized path.
This is where network loops become possible. The presence of redundant connections alone does not cause loops; rather, it is the lack of proper coordination between those connections that leads to looping behavior. Therefore, redundancy must always be managed carefully using intelligent network protocols.
Why Networks Allow Redundancy Despite Risks
Even though redundancy can lead to potential looping issues, it remains a critical feature in modern network design. The primary reason for using redundancy is to improve reliability and availability. Networks that serve businesses, organizations, and communication systems cannot afford downtime caused by a single point of failure.
Redundant paths ensure that if one connection fails due to hardware damage, cable issues, or configuration errors, another path is immediately available to maintain connectivity. This improves system stability and ensures that users experience minimal disruption.
The challenge lies in balancing redundancy with proper loop prevention techniques. Without redundancy, networks would be highly vulnerable. Without loop control, they would become unstable. Therefore, both aspects must work together in a controlled and well-managed environment.
Loop Formation in Complex Network Designs
As networks grow in size and complexity, the chances of accidental loop formation increase significantly. Large networks often include multiple switches, routers, and interconnected segments, all communicating simultaneously. Each device plays a role in forwarding data, and each connection adds another potential path for traffic.
In such environments, even a small misconfiguration can lead to serious issues. For example, connecting two switches with multiple cables without proper loop control can cause traffic to circulate endlessly between them. Similarly, incorrect routing configurations in layered network structures can create indirect loops that are harder to detect.
Complex network designs require strict planning and coordination to ensure that data flows efficiently without unnecessary repetition. Without proper design principles, even well-intentioned redundancy can turn into a source of instability.
Difference Between Intentional and Unintentional Loops
Not all looping behavior in networks is harmful or accidental. In some cases, looping mechanisms are used intentionally for testing or diagnostic purposes. For example, loopback testing allows network administrators to verify whether a device is functioning correctly by sending data out and receiving it back internally.
However, these intentional loops are controlled and isolated within a single device or a specific testing environment. They are not allowed to spread across the entire network.
Unintentional loops, on the other hand, occur due to configuration errors or system failures. These loops are not controlled and can spread across multiple devices, leading to congestion and performance degradation. The key difference lies in control and purpose—intentional loops are designed and limited, while unintentional loops are accidental and disruptive.
Importance of Traffic Flow Control in Networks
Proper traffic flow control is essential to prevent network loops and ensure smooth communication between devices. Networks rely on various mechanisms to direct data along the most efficient path while avoiding unnecessary repetition.
Devices such as switches and routers use specialized logic to determine where data should be sent next. This decision-making process depends on updated network information, including routing tables and addressing data. When this information is accurate and consistent, traffic flows smoothly without interruption.
However, when inconsistencies arise, traffic may be misdirected, leading to looping behavior. This is why maintaining accurate configuration and stable network information is critical. Without proper flow control, even simple communication tasks can become inefficient and unstable.
Network engineers continuously monitor and adjust traffic flow to ensure that data moves in a predictable and optimized manner. This helps maintain performance, reduce congestion, and prevent the formation of unwanted loops within the system.
Layered Structure of Network Loops
Network loops can occur at different layers of a computer network, and each layer behaves differently when a loop forms. Understanding these layers is important because the cause, impact, and solution of a loop depend heavily on where it originates. The two most common layers where loops are observed are Layer 2 and Layer 3 of the networking model.
Layer 2 is responsible for switching and MAC address-based forwarding, while Layer 3 handles routing and IP-based communication. When loops occur at Layer 2, they are usually related to switching behavior and broadcast traffic. On the other hand, Layer 3 loops are associated with routing decisions and incorrect path selection between networks.
Each layer has its own mechanisms for handling data, which means loop detection and prevention must also be handled differently. Without proper separation of responsibilities, a small error at one layer can escalate into a larger network-wide issue.
Layer 2 Network Loop Behavior
Layer 2 loops occur within switching environments where devices use MAC addresses to forward data frames. Switches learn where devices are located by building MAC address tables. These tables map devices to specific ports so that data can be sent efficiently without unnecessary flooding.
A Layer 2 loop happens when there are multiple active paths between switches without proper control. In such cases, a data frame may be forwarded from one switch to another in a circular manner. Since Ethernet frames do not have a built-in mechanism to limit their lifetime, they continue circulating indefinitely.
This behavior can quickly overwhelm a network. Each time the frame is forwarded, it is replicated across multiple paths, increasing traffic exponentially. As more frames enter the loop, the network becomes saturated with repeated data, leading to severe congestion and instability.
Layer 2 loops are particularly dangerous because they can develop very quickly and spread across multiple switches without immediate detection.
Broadcast Storms and Their Connection to Loops
One of the most damaging effects of Layer 2 loops is the broadcast storm. Broadcast storms occur when broadcast frames are continuously forwarded across the network without restriction. Since broadcast messages are intended to reach all devices in a network segment, they can easily multiply when loops are present.
When a loop exists, a single broadcast frame can be duplicated repeatedly by switches. Each switch forwards the frame to all connected ports, including the one it came from. This creates a continuous cycle where broadcast traffic increases uncontrollably.
As broadcast traffic grows, it consumes bandwidth and processing resources, leaving very little capacity for legitimate communication. Devices become overwhelmed, and normal network operations slow down or stop entirely. In severe cases, the network may become completely unusable until the loop is resolved.
Role of MAC Address Tables in Layer 2 Loops
MAC address tables play a crucial role in how switches manage data forwarding. These tables store information about which devices are connected to which ports. When functioning correctly, they allow switches to send data directly to the correct destination without unnecessary flooding.
However, in a looped environment, MAC address tables can become unstable. Because the same frame is seen arriving from multiple paths, the switch may continuously update its table with conflicting information. This process is known as MAC flapping.
MAC flapping causes confusion in the network because the switch cannot reliably determine the correct location of a device. As a result, frames may be forwarded incorrectly, dropped, or continuously circulated. This instability contributes to worsening the loop condition and further degrading network performance.
Layer 3 Network Loops and Routing Issues
Layer 3 loops occur in routing environments where devices use IP addresses to determine the best path for data. Unlike Layer 2, Layer 3 has mechanisms such as Time-To-Live (TTL) to limit packet circulation. However, routing loops can still occur when routing information is incorrect or inconsistent.
A routing loop happens when routers send data packets in a circular path between multiple devices. Each router believes the next hop is the correct destination, but due to incorrect routing tables, the packet never reaches its intended endpoint.
Routing loops are often caused by misconfigured static routes or delays in updating dynamic routing protocols. When routers do not have synchronized information, they may continue forwarding packets based on outdated or incorrect data.
Although TTL eventually stops packets from looping forever, the repeated forwarding still consumes bandwidth and processing power during the loop period.
Dynamic Routing Protocol Issues Leading to Loops
Dynamic routing protocols are designed to automatically update network paths based on changes in topology. While this improves flexibility, it can also introduce temporary instability that leads to loops.
Protocols such as OSPF and EIGRP exchange routing information between devices to maintain updated maps of the network. If updates are delayed, lost, or incorrectly interpreted, routers may develop inconsistent views of the network.
During these inconsistencies, a router may believe that another router offers the best path to a destination, while that router may hold conflicting information. This mismatch creates a loop where packets are continuously passed between routers without reaching the destination.
Although routing protocols include mechanisms to reduce loop formation, such as convergence timers and path recalculation, temporary loops can still occur during network changes.
Impact of Network Topology on Loop Formation
Network topology plays a significant role in the likelihood of loop formation. Topology refers to the physical or logical arrangement of devices within a network. Certain topologies, especially those with multiple interconnected paths, are more prone to loops if not properly managed.
In mesh-like structures where devices are highly interconnected, there are many alternative paths for data to travel. While this increases redundancy and reliability, it also increases the risk of circular data flow if loop prevention mechanisms are not active.
Star topologies, on the other hand, are less prone to loops because all devices connect through a central point. However, even in simpler topologies, misconfigurations can still introduce looping behavior.
Proper network design ensures that topology supports both performance and safety, minimizing the risk of unintended loops.
Role of VLANs in Loop Containment
Virtual Local Area Networks, commonly known as VLANs, are used to logically divide a physical network into separate segments. Each VLAN operates as an independent broadcast domain, meaning traffic is contained within its defined boundary.
VLANs help reduce the impact of network loops by limiting their scope. If a loop occurs within a VLAN, its effects are generally restricted to that segment rather than spreading across the entire network.
However, VLAN misconfigurations can also contribute to loop formation. If VLANs are incorrectly assigned or trunk links are improperly configured, traffic may cross unintended boundaries and create looping conditions.
Proper VLAN configuration is essential to ensure segmentation works effectively and does not introduce new network issues.
Power Over Ethernet and Loop Risks
Power over Ethernet (PoE) allows network cables to carry both data and electrical power. While this technology simplifies infrastructure, it also introduces additional complexity in network design.
If PoE devices are incorrectly connected or misconfigured, they can contribute to unstable network behavior. In some cases, improper power negotiation between devices can cause link resets, which may indirectly lead to looping conditions as network paths are recalculated repeatedly.
Although PoE itself does not directly cause loops, it adds another layer of complexity that must be carefully managed within the network environment.
Early Signs of Loop Formation in Networks
Detecting network loops early is critical to preventing widespread disruption. Some common early signs include sudden increases in network traffic, unusual device behavior, and inconsistent connectivity.
Devices may begin responding slowly or intermittently as looped traffic consumes resources. Administrators may also notice repeated messages or duplicate data appearing across the network.
Monitoring tools often detect abnormal spikes in bandwidth usage, which can indicate the presence of a loop. Identifying these signs early allows corrective action before the loop escalates into a full network failure.
Continuous observation and proactive monitoring are essential components of loop management strategies in modern networks.
How Network Loops Affect Network Performance
Network loops have a direct and often severe impact on overall network performance. When a loop forms, data packets begin circulating repeatedly instead of reaching their intended destination. This repeated circulation consumes bandwidth unnecessarily and reduces the amount of available network capacity for legitimate traffic.
As more packets get trapped in the loop, the network becomes increasingly congested. Devices such as switches and routers are forced to process the same data multiple times, which places additional strain on their CPU and memory resources. This results in slower response times and reduced efficiency across the entire network.
Even small loops can gradually degrade performance, but larger loops can bring an entire network segment to a near halt. The continuous flow of redundant data leaves very little room for normal communication, making it difficult for users and applications to function properly.
Congestion Caused by Continuous Packet Circulation
One of the most immediate effects of a network loop is congestion. Congestion occurs when the volume of data in a network exceeds its capacity to handle it efficiently. In a looping scenario, the same packets are repeatedly transmitted, multiplying traffic without adding any useful information.
This unnecessary repetition quickly fills up available bandwidth. As congestion increases, new data struggles to enter the network, causing delays and communication bottlenecks. Even simple tasks such as loading a webpage or sending a file can become noticeably slower.
In severe cases, congestion can become so intense that the network becomes almost unresponsive. Devices may fail to process new requests, and communication between systems may break down entirely until the loop is identified and resolved.
Broadcast Storms and Network Overload
Broadcast storms are one of the most destructive outcomes of network loops, especially at Layer 2. A broadcast storm occurs when broadcast traffic is continuously replicated and forwarded across all network devices without control.
In a looped environment, broadcast packets are repeatedly duplicated as they circulate through interconnected switches. Each switch forwards the broadcast frame to all available ports, including the one it received it from, causing exponential growth in traffic.
This rapid multiplication of broadcast packets overwhelms the network. Devices are forced to process a large number of unnecessary frames, consuming processing power and memory resources. As the storm intensifies, legitimate traffic is pushed aside, leading to severe performance degradation.
Broadcast storms can spread quickly and affect multiple network segments, making them one of the most dangerous symptoms of an unmanaged loop.
Increased Latency in Looping Networks
Latency refers to the time it takes for data to travel from its source to its destination. In a healthy network, latency is minimal and consistent. However, when a network loop is present, latency increases significantly due to repeated packet forwarding and congestion.
Packets trapped in a loop must travel through the same devices multiple times before they can escape the cycle. Each pass adds processing delay and increases overall travel time. This results in slower communication between devices and applications.
High-latency environments are particularly problematic for real-time applications such as voice calls, video conferencing, and online gaming. Even small delays can disrupt performance and create noticeable interruptions for users.
Packet Loss and Data Inefficiency
Packet loss is another common consequence of network loops. As congestion builds and devices become overloaded, some packets may be dropped because the network cannot process them in time. This is especially common when buffers on switches or routers become full due to excessive looping traffic.
When packets are lost, applications may need to resend data, further increasing network load. This creates a cycle where congestion leads to packet loss, and packet loss leads to more retransmissions, worsening the overall situation.
In some cases, packets may also be discarded due to incorrect forwarding decisions caused by unstable MAC or routing tables. This reduces data reliability and leads to incomplete communication between devices.
Impact on Network Stability and Reliability
Network loops significantly reduce the stability and reliability of a system. A stable network is one where data flows predictably and consistently without interruption. Loops disrupt this balance by introducing unpredictable traffic patterns and resource overload.
As loops persist, devices may begin to behave erratically. Switches may frequently update forwarding tables, routers may continuously recalculate routes, and network paths may become unstable. This constant fluctuation creates an unreliable environment where consistent communication becomes difficult.
In extreme cases, entire network segments may become inaccessible. Services may fail, connections may drop unexpectedly, and users may experience widespread disruptions in connectivity.
Service Disruptions and Outages
Service outages are among the most serious consequences of prolonged network loops. When network resources are exhausted due to looping traffic, essential services such as file sharing, internet access, and internal communication systems may stop functioning.
Outages can affect individual devices or entire sections of a network depending on the severity of the loop. In some cases, core network devices become so overloaded that they restart or shut down temporarily to recover from the stress.
These interruptions can have a major impact on productivity, especially in environments that rely heavily on continuous connectivity. The longer a loop remains undetected, the greater the likelihood of widespread service disruption.
Challenges in Detecting Network Loops
Detecting network loops can be difficult, especially in large or complex environments. Since loops may initially appear as general network slowdowns or congestion, they are not always immediately identified as the root cause.
Symptoms such as high bandwidth usage, delayed responses, and intermittent connectivity can be caused by multiple issues, making it challenging to isolate a loop without detailed analysis.
In some cases, loops may develop gradually and remain unnoticed until they reach a critical level of impact. Subtle loops may only cause minor performance issues, making them even harder to detect early.
Effective monitoring and diagnostic tools are essential for identifying loop conditions before they escalate into major problems.
Role of Network Devices Under Loop Conditions
Network devices such as switches and routers play a crucial role in how loops behave and spread. Under normal conditions, these devices efficiently manage data forwarding using learned information and routing logic.
However, during a loop, their normal operations become disrupted. Switches may continuously update MAC address tables due to repeated frame circulation, while routers may constantly recalculate routes in response to changing network conditions.
This constant processing increases CPU usage and memory consumption, which can slow down device performance. As devices struggle to keep up with the load, their ability to process legitimate traffic decreases, further contributing to network instability.
Resource Exhaustion in Network Equipment
Resource exhaustion is a major concern during network loops. Every network device has limited processing power, memory, and buffer capacity. When looping traffic consumes these resources, devices may become overwhelmed.
Switch buffers can fill up quickly due to excessive frame repetition, leading to dropped packets and communication delays. Similarly, CPU overload can cause delays in forwarding decisions, making the network even slower.
If the loop persists for an extended period, devices may restart or fail to respond altogether. This can create a cascading effect where multiple devices in the network become unstable at the same time.
Importance of Early Response to Loop Conditions
Responding quickly to network loops is critical to minimizing their impact. The longer a loop remains active, the more damage it causes to network performance and stability.
Early response involves identifying unusual traffic patterns, isolating affected segments, and applying corrective measures to stop the loop from spreading. Network administrators must act quickly to restore normal traffic flow and prevent further degradation.
Proactive monitoring and rapid troubleshooting are essential skills for managing loop-related issues effectively. Without timely intervention, even small loops can escalate into large-scale network failures that are difficult to recover from.
Spanning Tree Protocol as a Core Loop Prevention Method
Spanning Tree Protocol is one of the most widely used mechanisms for preventing network loops in switched Ethernet networks. Its main purpose is to ensure that only one logical path exists between any two devices, even if multiple physical connections are present for redundancy.
The protocol works by analyzing the entire network topology and selecting the most efficient paths for data forwarding. Once the best path is chosen, all other redundant paths are placed in a blocked state. This prevents data frames from circulating endlessly and forming loops.
Even though some links are disabled logically, they are not physically disconnected. This allows them to become active again if the primary path fails, ensuring both loop prevention and network reliability.
How Spanning Tree Builds a Loop-Free Topology
Spanning Tree begins its operation by identifying a root bridge, which acts as the central reference point for the network. All other switches then calculate the shortest and most efficient path to this root bridge based on predefined metrics.
Once the paths are determined, each switch assigns roles to its ports. Some ports are designated for forwarding traffic, while others are placed in a blocking state to eliminate redundant loops. This creates a logical tree structure that prevents circular data flow.
The process is dynamic, meaning that if network conditions change, Spanning Tree recalculates the topology and adjusts port roles accordingly. This ensures that the network remains loop-free even as devices are added, removed, or reconfigured.
Loop Guard and Additional Protection Mechanisms
In addition to Spanning Tree, modern networks use several supplementary tools to strengthen loop prevention. One such feature is loop guard, which helps detect and prevent unintended changes in port states that could lead to loops.
Loop guard monitors non-designated ports and ensures they do not incorrectly transition into forwarding mode due to missing or delayed control messages. If such a condition is detected, the port is automatically placed into a safe state to prevent looping behavior.
These additional safeguards provide extra layers of protection, especially in large or complex networks where timing issues or misconfigurations can lead to instability.
Root Guard and Network Stability Control
Root guard is another important feature used to maintain network stability. It is designed to prevent unauthorized or unexpected switches from becoming the root bridge in a Spanning Tree topology.
If a switch receives superior information that could potentially change the root bridge election, root guard blocks that port to maintain the existing structure. This prevents unwanted topology changes that could introduce loops or instability.
By controlling the root bridge placement, root guard helps ensure that the network maintains a predictable and stable structure, reducing the risk of loop formation caused by topology shifts.
Bridge Protocol Data Units in Loop Detection
Bridge Protocol Data Units, commonly known as BPDUs, are essential messages exchanged between switches to maintain Spanning Tree operation. These messages carry information about network topology and help devices make informed decisions about path selection.
Switches continuously exchange BPDUs to identify changes in the network. If a switch stops receiving BPDUs on a specific port, it may assume that a failure has occurred and adjust its configuration accordingly.
However, in loop conditions, BPDU messages may be duplicated or delayed, causing confusion in the topology calculation process. Proper handling of BPDUs is therefore essential to ensure accurate loop prevention and stable network operation.
Port Security and Loop Prevention
Port security is another technique used to reduce the risk of network loops. It limits the number of MAC addresses that can be learned on a specific switch port. By controlling which devices are allowed to connect, port security reduces the chances of unauthorized or misconfigured connections creating loops.
If a port receives traffic from an unexpected number of devices, it can be automatically disabled or restricted. This helps prevent situations where multiple devices are connected in a way that creates circular traffic paths.
Although port security is not a direct loop prevention protocol, it acts as a protective measure that reduces the likelihood of misconfigurations leading to loops.
Role of VLAN Design in Preventing Loops
Virtual Local Area Networks play an important role in controlling network segmentation and reducing loop risks. By dividing a large network into smaller logical segments, VLANs limit the scope of broadcast domains and isolate traffic.
When VLANs are properly configured, a loop in one segment does not necessarily affect the entire network. This containment helps reduce the overall impact of looping conditions.
However, improper VLAN configuration, especially on trunk links, can introduce complex loop scenarios. Incorrect tagging or mismatched VLAN assignments may cause traffic to circulate unexpectedly between switches.
Careful VLAN planning is essential to ensure that segmentation improves both performance and stability without introducing new risks.
Importance of Good Network Design
Strong network design is one of the most effective ways to prevent network loops. A well-designed network takes redundancy, performance, and loop prevention into account from the beginning.
Designers carefully plan how devices are connected, how traffic flows, and where redundancy is necessary. By avoiding unnecessary complexity and ensuring proper configuration standards, the risk of loops is significantly reduced.
Poor design, on the other hand, increases the likelihood of misconfigurations and unstable connections. As networks grow, design quality becomes even more important in maintaining long-term stability.
Monitoring and Detection of Loop Conditions
Continuous monitoring is essential for identifying and resolving network loops quickly. Monitoring tools track network traffic, device performance, and topology changes to detect unusual patterns.
Signs such as sudden spikes in bandwidth usage, high CPU utilization on switches, and frequent MAC address changes can indicate the presence of a loop. Early detection allows administrators to isolate the problem before it spreads.
Modern monitoring systems often use automated alerts to notify administrators when abnormal behavior is detected. This proactive approach reduces response time and minimizes potential damage caused by loops.
Troubleshooting Network Loops in Practice
When a network loop is suspected, troubleshooting begins by identifying the affected segment of the network. Administrators often analyze traffic patterns and check switch logs to locate unusual activity.
Once the problematic area is identified, redundant connections may be temporarily disabled to stop the looping traffic. This helps stabilize the network while further investigation is conducted.
After isolating the issue, configuration errors are corrected, and proper loop prevention mechanisms are verified. The network is then gradually restored to full operation while ensuring stability is maintained.
Final Conclusion
Network loops are a serious challenge in modern networking environments, but they are not unavoidable. With proper design, configuration, and monitoring, they can be effectively controlled and prevented.
Mechanisms such as Spanning Tree Protocol, VLAN segmentation, port security, and loop guard work together to create a stable and reliable network environment. These tools ensure that even in complex and redundant systems, data flows efficiently without entering endless cycles.
Understanding how loops form, how they impact performance, and how they are prevented is essential for maintaining healthy network operations. A well-managed network not only avoids loops but also ensures consistent performance, reliability, and scalability across all connected systems.