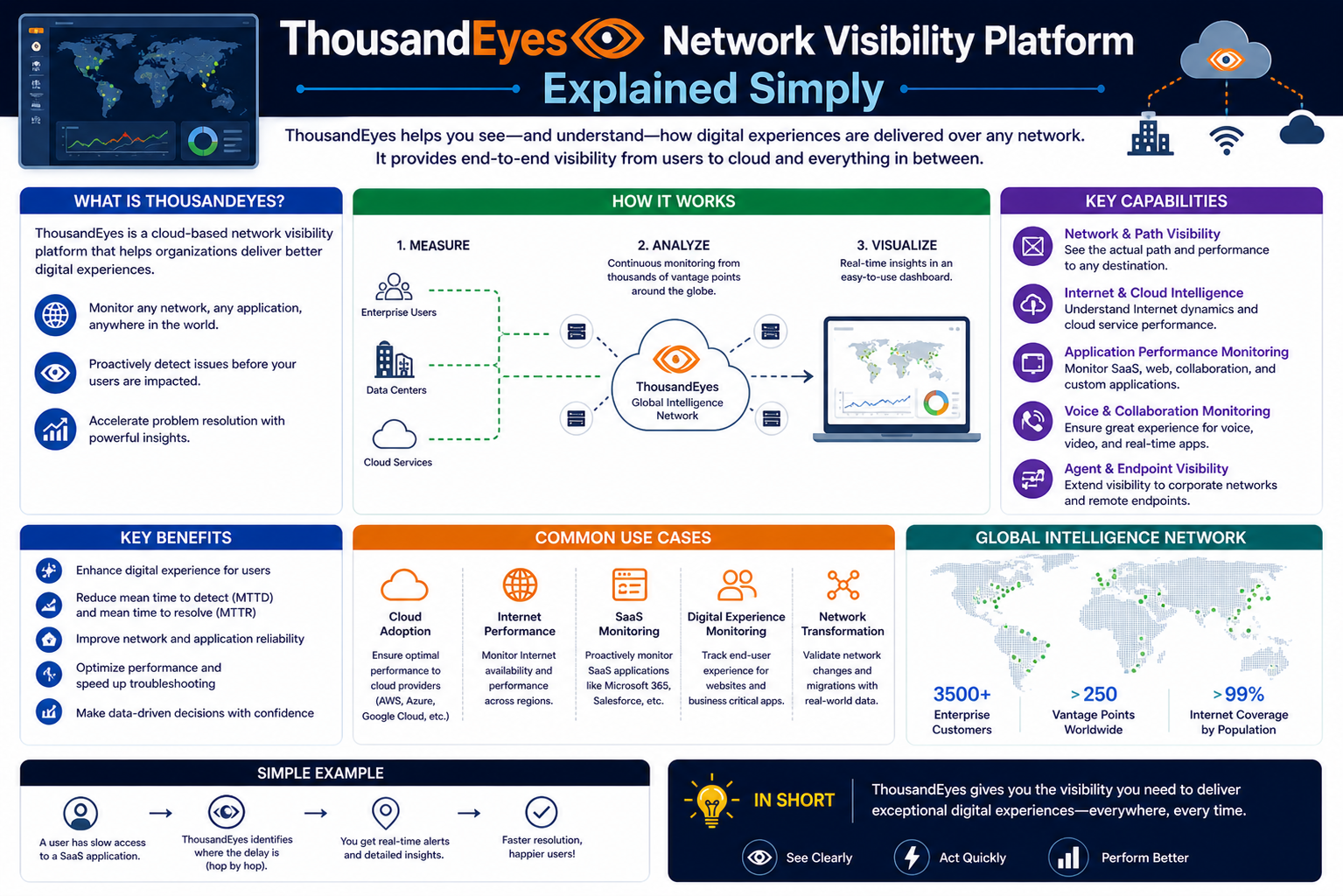
ThousandEyes is an advanced network intelligence and monitoring platform designed to give organizations deep visibility into how digital services perform across local networks, cloud environments, and the global internet. It helps businesses understand not only whether a service is working, but also how well it is performing from the perspective of real users. Instead of relying on limited internal network data, it expands visibility across multiple layers of connectivity, making it easier to detect hidden issues that affect performance. The platform is widely used in environments where digital reliability and user experience are critical, such as cloud applications, enterprise systems, and large-scale online services. Its main purpose is to eliminate blind spots in network operations by combining real-time analytics, global monitoring points, and intelligent diagnostics into a single unified system.
Why Network Visibility Matters in Modern Digital Systems
In today’s connected environment, organizations depend heavily on uninterrupted digital communication. Even a small disruption in network performance can lead to delays, service failures, and poor user experiences. Traditional monitoring tools often focus only on internal infrastructure, leaving gaps when data travels outside organizational boundaries. ThousandEyes addresses this limitation by extending visibility across the entire delivery path, including internet service providers, cloud platforms, and external networks. This broader perspective allows IT teams to understand exactly where performance issues originate instead of guessing or reacting after users are affected. Better visibility leads to faster troubleshooting, reduced downtime, and improved operational stability, which are essential for maintaining trust and efficiency in digital services.
How ThousandEyes Collects and Analyzes Network Data
The platform operates by gathering continuous data from distributed monitoring points located across different regions and network environments. These monitoring points simulate real-world traffic conditions and user interactions, allowing the system to observe how data moves across the internet. The collected information is processed in real time to identify delays, interruptions, and routing inefficiencies. Instead of relying on isolated metrics, ThousandEyes builds a complete picture of network behavior by correlating multiple data sources. This helps organizations understand not just what is happening, but why it is happening, enabling more accurate diagnosis and resolution of performance issues.
Active and Passive Monitoring Techniques Explained
ThousandEyes uses a combination of active and passive monitoring methods to capture network performance insights. Active monitoring involves sending test traffic through the network to measure response times, packet delivery, and connection stability. This helps simulate real user behavior and detect issues before they affect actual users. Passive monitoring, on the other hand, analyzes existing traffic flows without injecting additional data. It observes real interactions and identifies anomalies or performance degradation. By combining both approaches, the platform provides a comprehensive view of network health, ensuring that both simulated and real-world conditions are evaluated effectively.
Understanding End-to-End Internet Visibility
One of the most powerful aspects of ThousandEyes is its ability to provide end-to-end visibility across the internet. Instead of focusing only on internal systems, it tracks how data travels through multiple external networks before reaching its destination. This includes routing paths, service provider infrastructure, and global internet exchange points. By mapping the full journey of data packets, the platform can identify exactly where delays or failures occur. This level of visibility is especially important for cloud-based applications that rely on third-party infrastructure, where issues can arise outside the control of the organization.
Key Network Performance Metrics Captured by the Platform
ThousandEyes collects a wide range of performance metrics that help evaluate network quality and stability. These include latency, which measures the time it takes for data to travel between points, packet loss, which indicates whether data is being dropped during transmission, and jitter, which reflects variations in data delivery timing. It also monitors Quality of Service indicators that provide insights into how consistently data is delivered. By analyzing these metrics together, the platform can detect subtle performance degradation that might not be immediately visible but can still impact user experience over time.
Network Path Analysis and Routing Intelligence
The platform provides detailed analysis of network paths to show exactly how data moves from source to destination. This includes every hop along the route, along with performance data for each segment. If a delay or failure occurs, it becomes easier to pinpoint the exact location of the problem. This is especially useful in complex network environments where traffic passes through multiple service providers. By visualizing the full path, organizations can identify inefficient routing, congestion points, or misconfigured network elements that may be affecting performance.
Role of BGP Visibility in Internet Performance Monitoring
Border Gateway Protocol visibility is another important component of ThousandEyes. It helps track how internet routing decisions are made across global networks. Since BGP determines how data travels between large network systems, any instability or misconfiguration can significantly impact connectivity. The platform monitors these routing changes and provides insights into how they affect application performance. By understanding BGP behavior, organizations can detect routing anomalies, avoid inefficient paths, and maintain more stable connectivity across distributed systems.
DNS Performance Monitoring and Its Importance
Domain Name System performance plays a crucial role in how quickly users can access online services. ThousandEyes continuously monitors DNS resolution processes to ensure that domain requests are being resolved efficiently and accurately. If DNS failures or delays occur, users may experience slow loading times or inability to reach services altogether. By tracking DNS behavior, the platform helps identify misconfigurations, server outages, or resolution delays that could impact accessibility. This ensures that one of the most fundamental components of internet connectivity remains reliable and responsive.
Real-Time Detection of Network and Application Outages
Another key capability of ThousandEyes is its ability to detect outages as they happen. The system continuously monitors global network conditions and application availability to identify disruptions in real time. When an issue occurs, it quickly determines whether the problem is local, regional, or related to external infrastructure. This rapid identification allows IT teams to respond immediately instead of waiting for user complaints or delayed alerts. Early detection of outages helps minimize downtime and reduces the overall impact on business operations and customer experience.
Understanding User Experience Through Network Intelligence
Beyond technical metrics, ThousandEyes also focuses on how users actually experience digital services. It evaluates page load performance, application responsiveness, and interaction delays to determine how smooth the user journey is. By simulating real user behavior, it provides a realistic view of how applications perform under different network conditions. This helps organizations prioritize improvements that directly enhance customer satisfaction. Instead of focusing only on infrastructure health, the platform connects technical performance with real-world user impact.
How ThousandEyes Improves Decision Making in IT Operations
With access to detailed performance data and global visibility, organizations can make more informed decisions about their network strategies. Instead of reacting to problems after they occur, IT teams can proactively identify risks and optimize performance before users are affected. This data-driven approach reduces uncertainty and improves planning for infrastructure upgrades, service deployments, and network optimization. It also helps align technical performance with business goals by ensuring that digital services remain reliable and efficient.
Early Role in Supporting Digital Reliability and Stability
ThousandEyes plays a foundational role in supporting digital reliability across modern organizations. By continuously monitoring network behavior and providing actionable insights, it helps maintain stable connectivity across complex environments. Whether dealing with cloud services, hybrid networks, or global internet traffic, the platform ensures that performance issues are detected early and resolved efficiently. This proactive approach strengthens overall system resilience and supports consistent digital operations across all levels of the organization.
Deep Network Intelligence Across Complex Digital Environments
ThousandEyes extends network visibility far beyond traditional monitoring by delivering deep intelligence across highly complex and distributed digital environments. Modern organizations operate across multiple infrastructures including private networks, cloud platforms, and third-party services. This complexity makes it difficult to pinpoint where performance issues originate. ThousandEyes addresses this challenge by continuously mapping how data flows across every segment of the digital ecosystem. It correlates performance signals from different environments and transforms them into a unified view. This allows IT teams to understand how each part of the network contributes to overall service behavior, making it easier to detect inefficiencies and hidden disruptions.
Comprehensive End-to-End Path Visibility for Data Traffic
A key strength of ThousandEyes is its ability to provide complete end-to-end visibility of data traffic paths. Instead of viewing isolated network segments, it shows the full journey of packets as they travel from source to destination. This includes internal systems, external networks, internet service providers, and cloud infrastructure. Each hop in the path is analyzed for performance metrics such as delay, loss, and routing efficiency. By presenting this full path visualization, the platform helps organizations quickly identify where degradation occurs. This level of insight is critical for troubleshooting issues that span multiple administrative boundaries and service providers.
High-Precision Performance Monitoring Through Distributed Agents
ThousandEyes relies on distributed monitoring agents that are strategically placed across different geographic and network locations. These agents continuously perform synthetic tests to simulate real user interactions and measure performance conditions. They generate detailed insights into how applications respond under different network conditions. Because these agents are located in diverse environments, they can capture variations in performance caused by geography, routing paths, or infrastructure differences. This distributed approach ensures that performance monitoring is not limited to a single perspective but reflects global user experience.
Latency, Packet Loss, and Jitter Analysis for Network Health
The platform continuously evaluates essential network health indicators such as latency, packet loss, and jitter. Latency measures how long data takes to travel between points, while packet loss identifies whether data is dropped during transmission. Jitter tracks inconsistencies in data delivery timing. When analyzed together, these metrics provide a clear understanding of network stability and quality. ThousandEyes not only records these values but also correlates them with network events and routing changes. This helps organizations determine whether performance issues are caused by infrastructure congestion, misconfiguration, or external network disruptions.
Advanced Routing Path Diagnostics and Visualization
One of the most powerful diagnostic capabilities of ThousandEyes is its ability to visualize routing paths in detail. Every data request travels through multiple network nodes before reaching its destination, and each node plays a role in performance. The platform maps these routes and highlights where delays or failures occur. If a routing change happens, it is immediately detected and analyzed for its impact on performance. This makes it easier for network engineers to identify inefficient routing decisions or unstable paths. By understanding routing behavior, organizations can optimize connectivity and reduce unnecessary latency.
Integration of Internet-Level Intelligence for Global Awareness
ThousandEyes incorporates internet-level intelligence to provide visibility into global network conditions. Instead of focusing only on internal infrastructure, it analyzes how the broader internet behaves at any given time. This includes monitoring large-scale disruptions, routing instability, and service degradation across different regions. By understanding global internet health, organizations can predict how external factors might impact their own services. This broader awareness helps IT teams prepare for potential disruptions and adjust configurations proactively to maintain consistent service delivery.
Application Performance Monitoring from a User Perspective
Beyond infrastructure analysis, ThousandEyes also focuses heavily on how applications perform from the end-user perspective. It simulates real user interactions such as loading pages, submitting requests, and navigating multi-step processes. These simulations generate detailed performance reports that show how users experience digital services. If delays or failures occur, the platform identifies whether the issue is caused by the application, network, or external dependency. This user-centric approach ensures that performance optimization is aligned with actual customer experience rather than just backend system health.
Multi-Step Transaction Testing for Realistic Performance Insights
The platform is capable of simulating complex multi-step transactions that replicate real-world user behavior. These transactions may involve multiple requests, authentication steps, or data exchanges between systems. By analyzing each step individually, ThousandEyes identifies where delays occur within the process. This level of detail helps organizations understand not just whether a service is slow, but exactly which part of the workflow is causing the slowdown. This is especially useful for applications that rely on multiple interconnected services or APIs.
DNS Resolution Tracking and Domain Performance Assurance
Domain resolution plays a critical role in ensuring that users can access digital services quickly and reliably. ThousandEyes continuously tracks DNS resolution processes to ensure that domain queries are resolved efficiently. It monitors response times, resolution accuracy, and server availability. If DNS issues arise, they can lead to widespread accessibility problems even if the main application is functioning correctly. By identifying DNS-related delays or failures early, the platform helps maintain uninterrupted access to services and prevents user-facing disruptions.
Real-Time Visualization of Network Anomalies and Disruptions
The platform provides real-time visualization of network anomalies as they occur. Instead of waiting for periodic reports or manual alerts, it immediately highlights unusual behavior in network performance. This includes sudden spikes in latency, unexpected packet loss, or routing instability. These visual insights allow IT teams to quickly understand the severity and scope of an issue. By seeing problems unfold in real time, organizations can respond faster and reduce the impact of disruptions on end users.
Correlation of Network Events with Performance Impact
ThousandEyes does not simply detect network events; it correlates them with their actual impact on performance. For example, if a routing change occurs, the platform analyzes whether it results in slower application response times or increased latency. This correlation helps distinguish between harmless network changes and those that negatively affect user experience. By linking technical events with performance outcomes, the platform provides actionable intelligence rather than isolated data points.
Visibility Into Cloud-Based Application Dependencies
Modern applications often depend on multiple cloud services and third-party providers. ThousandEyes provides visibility into these dependencies by tracking how external services affect overall performance. If a cloud service experiences delays or outages, the platform identifies how it impacts the main application. This is especially important in environments where organizations do not have direct control over all components. By monitoring external dependencies, IT teams can better understand risk exposure and prepare for potential service interruptions.
Global Perspective on Network Reliability and Stability
The platform offers a global perspective on network reliability by aggregating data from multiple regions and environments. This allows organizations to compare performance across different geographic locations and identify regional inconsistencies. If one region experiences higher latency or instability, it becomes immediately visible. This global view helps organizations balance traffic, optimize infrastructure placement, and improve overall service reliability for users across different locations.
Continuous Performance Baselines for Network Optimization
ThousandEyes establishes continuous performance baselines that represent normal network behavior over time. These baselines help detect deviations that may indicate emerging issues. Instead of reacting only to major failures, the system identifies gradual performance degradation before it becomes critical. This proactive monitoring approach allows organizations to fine-tune network configurations and maintain consistent performance levels across all environments.
Support for Hybrid and Multi-Cloud Network Environments
Many organizations now operate in hybrid and multi-cloud environments where workloads are distributed across different infrastructures. ThousandEyes is designed to handle this complexity by providing unified visibility across all environments. It tracks how data moves between on-premises systems, cloud platforms, and external services. This ensures that performance monitoring remains consistent regardless of where applications are hosted. By bridging visibility gaps between environments, the platform simplifies network management in highly distributed systems.
Expanding Visibility Across Enterprise and Global Networks
ThousandEyes provides enterprise-grade monitoring that extends visibility across both internal infrastructure and the global internet. In modern digital ecosystems, enterprise networks are no longer confined within organizational boundaries. They span across cloud services, remote offices, third-party providers, and distributed applications. This complexity creates blind spots that traditional monitoring tools struggle to handle. ThousandEyes addresses this challenge by combining multiple layers of observation into a unified intelligence system. It continuously tracks how enterprise traffic behaves across every segment of its journey, ensuring that organizations maintain a complete understanding of performance conditions at all times.
Internet Insights for Global Network Health Awareness
Internet Insights is a core capability that delivers a real-time understanding of global internet health. It continuously analyzes large volumes of network telemetry collected from distributed vantage points. This allows the platform to detect widespread outages, routing instability, and performance degradation across different regions of the internet. Instead of focusing only on isolated network segments, Internet Insights provides a macro-level view of connectivity trends. This global awareness helps organizations understand whether performance issues originate within their own infrastructure or are caused by external internet conditions. By identifying large-scale disruptions early, businesses can adjust routing strategies and reduce the impact on users.
WAN Insights for Predictive Network Optimization
WAN Insights introduces predictive intelligence into enterprise network monitoring by analyzing wide area network behavior over time. It uses advanced statistical models to evaluate telemetry data and forecast potential performance issues before they occur. This capability is especially useful in environments where networks are highly dynamic and subject to frequent changes in traffic patterns. WAN Insights helps organizations optimize SD-WAN configurations by providing recommendations based on Quality of Experience metrics. Instead of reacting to network degradation after users are affected, IT teams can proactively adjust policies to maintain consistent performance and avoid disruptions.
Understanding Quality of Experience in Network Performance
Quality of Experience is a user-focused measurement that evaluates how effectively applications perform from the end-user perspective. Unlike traditional metrics that focus solely on infrastructure health, Quality of Experience considers how users actually perceive performance. This includes responsiveness, loading times, and interaction smoothness. ThousandEyes integrates this concept into its analytics engine, allowing organizations to align technical performance with user satisfaction. By prioritizing experience-based metrics, enterprises can make more informed decisions about network optimization and application delivery.
Network and Application Synthetics for Proactive Testing
Network and Application Synthetics is a powerful capability that simulates real user interactions to proactively test network and application performance. These synthetic tests are designed to mimic user behavior such as accessing web pages, completing transactions, and interacting with services. By running these tests continuously, the platform identifies potential issues before they impact real users. This proactive approach ensures that organizations can detect performance degradation early and take corrective action immediately. It also helps validate application performance under different network conditions, improving overall reliability.
Simulating Real-World User Journeys for Accurate Insights
Synthetic monitoring goes beyond basic connectivity checks by simulating complete user journeys across applications. These journeys may involve multiple steps such as authentication, data retrieval, and service interaction. By replicating these workflows, ThousandEyes provides detailed insights into how each step performs under real-world conditions. This helps organizations identify bottlenecks within application logic or network pathways. It also enables more accurate performance testing during system updates, migrations, or infrastructure changes.
Deep Visibility Into Application Delivery Chains
Modern applications rely on complex delivery chains that include servers, APIs, databases, and third-party services. ThousandEyes provides visibility into each component of this chain, ensuring that performance issues can be traced accurately. If an application slows down, the platform identifies whether the issue originates from the network, the application layer, or an external dependency. This granular visibility reduces troubleshooting time and eliminates guesswork. It also allows organizations to prioritize fixes based on actual impact rather than assumptions.
Integration with SD-WAN for Intelligent Traffic Management
ThousandEyes integrates seamlessly with software-defined wide area network environments to enhance traffic management and visibility. SD-WAN technologies dynamically route traffic based on network conditions, and ThousandEyes provides the intelligence needed to optimize these decisions. By analyzing real-time performance data, it helps ensure that traffic is directed through the most efficient paths. This integration improves overall network reliability and ensures consistent application performance across distributed environments. It also helps organizations validate SD-WAN policies and identify misconfigurations that could impact connectivity.
End User Monitoring for Real-Time Experience Tracking
End User Monitoring focuses on capturing performance data directly from the user’s perspective. It uses browser-based agents and endpoint monitoring tools to measure how applications behave in real time. This includes tracking page load speeds, responsiveness, and interaction delays. By collecting data directly from user devices, the platform provides an accurate representation of actual experience rather than simulated conditions. This helps IT teams identify issues that may only appear under specific user environments or configurations.
Browser-Based Visibility Into Application Performance
One of the key strengths of End User Monitoring is its ability to analyze performance at the browser level. This includes tracking how web pages load, how scripts execute, and how resources are rendered. It provides detailed breakdowns of each stage of page loading, allowing organizations to identify performance bottlenecks with precision. If a page is slow, the system can determine whether the delay is caused by network latency, server response time, or client-side processing. This level of detail is essential for optimizing modern web applications.
Device-Level Metrics for Endpoint Performance Analysis
ThousandEyes also collects device-level metrics to understand how endpoints contribute to overall performance. This includes CPU usage, memory consumption, and network interface behavior. By analyzing endpoint conditions, the platform can determine whether performance issues are caused by local device limitations or external network factors. This helps differentiate between infrastructure-related problems and user-side issues. Device-level insights are especially useful in remote work environments where endpoint variability can significantly impact application performance.
Topology Discovery for Network Mapping and Analysis
Topology discovery is a capability that automatically maps network structures to provide a clear visualization of connectivity relationships. It identifies how devices, routers, and network segments are connected within an environment. This mapping helps organizations understand how traffic flows through their infrastructure and where potential bottlenecks may exist. By visualizing topology, IT teams can quickly identify misconfigurations, inefficient routing paths, or overloaded network segments. This improves troubleshooting efficiency and supports better network design decisions.
Correlation Between Network Layers and Application Behavior
ThousandEyes correlates data from multiple network layers to understand how infrastructure behavior impacts application performance. Instead of analyzing each layer separately, it connects signals from the physical, network, transport, and application layers. This holistic approach provides a complete understanding of how issues propagate through the system. For example, a network delay may eventually impact application response time, and this correlation helps trace the root cause more effectively. It reduces diagnostic complexity and improves resolution speed.
Real-Time Alerting and Incident Detection Mechanisms
The platform includes real-time alerting systems that notify IT teams when performance anomalies are detected. These alerts are based on predefined thresholds and behavioral baselines. When an issue occurs, the system immediately identifies its severity and potential impact. This ensures that organizations can respond quickly to emerging problems before they escalate. Real-time alerts are particularly important for mission-critical applications where even short disruptions can have significant consequences.
Cross-Domain Visibility for Distributed Infrastructure
ThousandEyes provides cross-domain visibility that spans across internal networks, cloud environments, and third-party services. This is essential for modern infrastructure that relies on multiple interconnected systems. By unifying visibility across domains, the platform eliminates silos that typically exist between different IT environments. This enables a more coordinated approach to monitoring and troubleshooting. It also ensures that performance issues can be traced across organizational boundaries without losing visibility.
Data Correlation for Accurate Root Cause Analysis
One of the most valuable capabilities of ThousandEyes is its ability to correlate multiple data sources for root cause analysis. Instead of treating each metric independently, it combines them to identify relationships between different performance signals. This helps pinpoint the exact source of an issue more accurately. For example, a routing change might coincide with increased latency and degraded application performance. By correlating these events, the platform provides a clear explanation of cause and effect, reducing investigation time.
Scalability Across Large and Distributed Networks
The platform is designed to scale across large and complex network environments. Whether an organization operates a small infrastructure or a global enterprise network, ThousandEyes can adapt to varying levels of complexity. It supports high volumes of monitoring data and distributed testing across multiple regions. This scalability ensures that performance visibility remains consistent even as network environments grow. It also allows organizations to expand monitoring coverage without sacrificing accuracy or efficiency.
Unified Visibility Across Multi-Cloud Architectures
Modern enterprises often use multiple cloud providers to host applications and services. ThousandEyes provides unified visibility across these multi-cloud environments, ensuring that performance can be monitored consistently regardless of where services are hosted. It tracks how data moves between cloud platforms and identifies performance variations across different providers. This helps organizations optimize cloud usage, improve redundancy strategies, and maintain consistent user experiences across distributed systems.
Transforming Network Monitoring Into Business Intelligence
ThousandEyes goes beyond traditional network monitoring by transforming raw performance data into meaningful business intelligence. Instead of only reporting technical metrics, it connects network behavior with business outcomes such as service availability, user satisfaction, and operational efficiency. This allows organizations to understand how network performance directly affects revenue, productivity, and customer trust. When digital services slow down or fail, the impact is no longer seen as just a technical issue but as a business disruption. ThousandEyes helps bridge this gap by translating technical signals into actionable insights that decision-makers can understand and act upon.
Improving Digital Reliability Across Enterprise Systems
Digital reliability has become a core requirement for modern organizations, especially those that depend heavily on online services and cloud applications. ThousandEyes strengthens reliability by continuously monitoring every layer of the digital delivery chain. It identifies weak points in connectivity, application delivery, and external dependencies before they escalate into major failures. This proactive approach ensures that systems remain stable even under changing network conditions. By improving reliability, organizations can reduce service interruptions, maintain user trust, and ensure smooth digital operations across all platforms.
Supporting Cloud Migration and Hybrid Infrastructure Strategies
As organizations move toward cloud-based and hybrid infrastructure models, visibility becomes increasingly complex. ThousandEyes supports this transition by providing consistent monitoring across on-premises systems, cloud environments, and hybrid setups. It helps organizations understand how data flows between different infrastructures and whether performance is affected during migration or integration processes. This visibility is critical during cloud adoption, as it allows IT teams to verify that applications perform consistently across environments. It also reduces the risks associated with migration by identifying potential issues before they impact users.
Enhancing Troubleshooting Efficiency in Complex Networks
Troubleshooting network issues in modern environments can be challenging due to the number of interconnected systems involved. ThousandEyes simplifies this process by providing detailed diagnostics that trace issues back to their root cause. Instead of manually checking multiple systems, IT teams can use unified visibility to quickly identify where performance degradation begins. This reduces mean time to resolution and improves operational efficiency. The ability to see both internal and external network behavior in one platform eliminates guesswork and accelerates problem-solving.
Reducing Downtime Through Early Detection of Issues
Downtime can have serious consequences for any organization, including financial losses and reputational damage. ThousandEyes reduces downtime by detecting issues early through continuous monitoring and intelligent alerting. It identifies anomalies in network behavior before they escalate into full outages. This early detection allows IT teams to take corrective action proactively. By addressing problems at an early stage, organizations can maintain service continuity and avoid prolonged disruptions that affect users and business operations.
Strengthening Dependency Visibility Across External Services
Modern applications rely heavily on third-party services, including cloud providers, APIs, and external platforms. ThousandEyes provides visibility into these dependencies, ensuring that organizations understand how external systems impact their performance. If a third-party service experiences delays or outages, the platform immediately highlights its effect on internal applications. This level of dependency awareness is critical for risk management, as it allows organizations to prepare for external disruptions and design more resilient systems.
Optimizing Network Performance Through Data-Driven Insights
Network optimization is a continuous process that requires accurate and timely data. ThousandEyes supports this by providing detailed insights into network performance trends and patterns. It identifies areas where latency, congestion, or routing inefficiencies occur and offers recommendations for improvement. These insights allow IT teams to fine-tune configurations and improve overall network efficiency. Instead of relying on assumptions, organizations can make data-driven decisions that lead to measurable performance improvements.
Supporting Digital Experience Management Across Organizations
Digital experience management focuses on ensuring that users have a smooth and consistent interaction with applications and services. ThousandEyes plays a key role in this by monitoring every aspect of the user journey, from network connectivity to application responsiveness. It provides visibility into how users experience services across different devices, locations, and network conditions. This helps organizations identify experience gaps and take corrective action to improve satisfaction. By focusing on the end-user perspective, businesses can align technical performance with user expectations.
Enterprise Scalability for Large-Scale Monitoring Needs
Large organizations require monitoring solutions that can scale with their infrastructure. ThousandEyes is designed to handle large-scale environments with distributed networks, global users, and complex application architectures. It supports high volumes of data collection and analysis without compromising performance. This scalability ensures that organizations can expand their operations without losing visibility into network behavior. Whether monitoring a few applications or thousands of services, the platform maintains consistent accuracy and reliability.
Integration With Modern IT Ecosystems and Tools
ThousandEyes integrates seamlessly with modern IT ecosystems, allowing it to work alongside other monitoring, analytics, and network management tools. This integration enables organizations to centralize their observability strategy and reduce fragmentation between systems. By connecting with existing workflows, it enhances operational efficiency and improves collaboration between IT teams. Integration also ensures that performance insights are shared across departments, supporting better decision-making at all levels of the organization.
Improving Security Awareness Through Network Visibility
While primarily focused on performance monitoring, ThousandEyes also contributes to security awareness by identifying unusual network behavior. Sudden changes in traffic patterns, unexpected routing shifts, or abnormal connectivity issues can indicate potential security concerns. By providing visibility into these anomalies, the platform helps organizations detect risks early. Although it is not a dedicated security tool, its insights can complement security strategies by highlighting suspicious network activity and supporting incident investigations.
Supporting Incident Response and Recovery Processes
During network incidents, rapid response is critical to minimizing impact. ThousandEyes supports incident response by providing real-time data and historical context for troubleshooting. IT teams can quickly identify when an issue started, what systems were affected, and how it evolved over time. This information is essential for coordinating recovery efforts and restoring services efficiently. By reducing the time needed to understand incidents, the platform helps organizations recover faster and maintain operational stability.
Enabling Proactive Network Management Strategies
Traditional network management is often reactive, addressing issues only after they occur. ThousandEyes shifts this approach toward proactive management by continuously monitoring performance and identifying potential risks in advance. This allows organizations to prevent issues rather than simply responding to them. Proactive management improves overall network health, reduces downtime, and enhances user satisfaction. It also enables IT teams to focus on long-term optimization rather than constant firefighting.
Supporting Compliance and Operational Transparency
Many organizations must meet compliance requirements related to service availability, data handling, and operational transparency. ThousandEyes supports these requirements by providing detailed logs, performance records, and visibility reports. These insights help organizations demonstrate compliance with internal policies and external regulations. Operational transparency also improves accountability, as teams can clearly see how systems are performing and where improvements are needed.
Enhancing Collaboration Between IT and Business Teams
ThousandEyes helps bridge the gap between technical teams and business stakeholders by presenting performance data in an understandable format. Instead of focusing solely on technical metrics, it highlights how network performance affects user experience and business outcomes. This shared understanding improves collaboration between departments and ensures that technical decisions align with business priorities. It also helps non-technical stakeholders make informed decisions based on real performance data.
Driving Continuous Improvement in Digital Infrastructure
Continuous improvement is a key principle in modern IT operations. ThousandEyes supports this by providing ongoing visibility into network and application performance. Organizations can track improvements over time, identify recurring issues, and refine their infrastructure strategies accordingly. This continuous feedback loop ensures that systems evolve in line with business needs and technological advancements. It also helps maintain long-term stability and performance consistency.
Final Conclusion
ThousandEyes stands as a powerful platform for achieving complete visibility across modern digital environments. It combines network intelligence, application monitoring, and global internet insights into a unified system that helps organizations maintain reliable and high-performing services. By providing deep visibility into every stage of data delivery, it enables faster troubleshooting, proactive optimization, and improved user experience. Its ability to connect technical performance with business outcomes makes it a strategic tool for organizations operating in complex, distributed, and cloud-driven environments.